When a prompt gives you a statistical claim from an article or previous study, first identify the test needed. Phrases like "do the data give convincing evidence..." or "is there convincing evidence of..." usually signal that you need a significance test.
When one of these key phrases appear in the prompt, we then need to determine if our data is categorical data or quantitative data. If we have quantitative data, we will set up a test for a population mean. As with confidence intervals, a test for population mean will make use of t-scores. If we only have one sample, we will perform a one sample t-test.
If the quantitative data are collected in matched pairs (for example, before-and-after on the same subjects, or naturally paired subjects like twins), identify this as a matched pairs situation. In matched pairs, compute a difference for each pair (for example, d = After − Before or Treatment − Control), then do a one-sample t-test on the mean difference, μd.
A one-sample t-test is used to compare the mean of a sample to a hypothesized value for the population mean. It is often used when the standard deviation (σ) of the population is not known. To conduct a one-sample t-test, you first need to determine the null and alternative hypotheses. The null hypothesis is a statement of no difference or no effect, and it is the hypothesis that is being tested, while the alternative hypothesis is the opposite of the null hypothesis, and it is what you hope to show is true.
Significance Level
One major aspect of our significance test is the significance level. The significance level (alpha, 𝞪) is the probability of rejecting the null hypothesis when it is actually true. It is the threshold that you set for determining whether the sample mean is significantly different from the claimed population mean. If the p-value is less than the significance level, then you can reject the null hypothesis and conclude that the sample mean is significantly different from the claimed population mean.
A smaller alpha reduces the chance of a Type I error (false positive) but increases the chance of a Type II error (false negative). A larger alpha increases the chance of a Type I error but reduces the chance of a Type II error, all else equal.
The most common significance level used in research is 0.05, which means that there is a 5% chance of rejecting the null hypothesis when it is actually true. This is often considered a good balance between minimizing the risk of Type I and Type II errors. However, the appropriate significance level will depend on the specific research question and the context in which the research is being conducted.

Optional connection: Confidence Intervals and Two-Sided Tests
A significance level is directly connected to a one sample t-interval for two-sided tests. For a two-sided test at significance level α, the corresponding confidence interval has confidence level 1 − α. This equivalence does not apply in the same way for one-sided tests.
Example
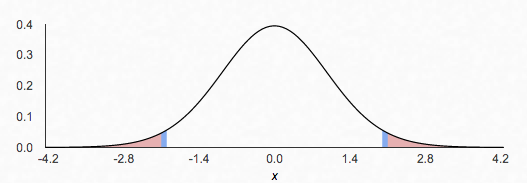
In the image below, we see a 95% confidence interval in the non-shaded region for a mean of 0 and 29 df. The shaded region is known as the rejection region. This is the region in which a statistic is significant enough (in accordance with its 𝞪 level) to reject the claimed population mean. In this example, any t-statistic greater than 2.04 or less than -2.04 would lead us to doubt that the true population mean is 0.
Writing Hypotheses
Once we have identified our test and significance level, we need to identify and write our hypothesized values. We have two hypotheses: null and alternate.
Null Hypothesis (Ho)
In a one-sample t-test, the null hypothesis is a statement about the population mean, and it is based on the claim made by the previous study or article. The null hypothesis is typically stated as H0: μ = μ0, where μ is the population mean and μ0 is the hypothesized value.
For example, if the previous study claimed that the mean number of chicken nuggets per bag is 20, the null hypothesis for a one-sample t-test would be H0: μ = 20. This means that the null hypothesis is that the true mean number of chicken nuggets per bag is equal to 20.
Our null hypothesis is always going to be μ = hypothesized population mean (in number format).
Down the road, the purpose of the one-sample t-test is to determine whether the sample mean is significantly different from the hypothesized population mean. If the p-value is less than the predetermined significance level (usually 0.05), then you can reject the null hypothesis and conclude that the sample mean is significantly different from the hypothesized population mean. If the p-value is greater than the significance level, then you fail to reject the null hypothesis. The data do not provide convincing evidence against H0; do not conclude H0 is true.
Alternate Hypothesis (Ha)
The alternative hypothesis is the opposite of the null hypothesis, and it is what you hope to show is true. In a one-sample t-test, Ha can be μ ≠ μ0, μ < μ0, or μ > μ0, where μ is the population mean.
For example, if the null hypothesis is μ = 20 (the hypothesized population mean is 20), the alternative hypothesis could be μ ≠ 20 (the population mean is not equal to 20), μ < 20 (the population mean is less than 20), or μ > 20 (the population mean is greater than 20).
The alternative hypothesis that you choose will depend on the specific research question and the context in which the research is being conducted. For example, if you are testing the claim that the mean number of chicken nuggets per bag is 20, and you expect the actual mean to be higher, you would choose the alternative hypothesis μ > 20. On the other hand, if you expect the actual mean to be lower, you would choose the alternative hypothesis μ < 20.
Matched Pairs: Writing Hypotheses
- Define the order of subtraction for the differences. For example, let d = After − Before, or d = Treatment − Control.
- State the hypotheses about the mean difference, μd:
- H0: μd = 0 (or another specified value)
- Ha: μd < 0, μd > 0, or μd ≠ 0, depending on the context and how you defined d
Be consistent: your conclusions about “greater” or “less” are tied to your chosen order of subtraction.
Example
A recent study has found that the average number of school days missed by a high school senior is 5.2 days. After taking a random sample of 150 high school seniors, our sample has an average of 4.1 days missed with a standard deviation of 0.4. Do the data give convincing evidence that the average number of days missed by a high school senior is less than the claim from the study?
- Ho: μ = 5.2
- Ha: μ < 5.2
For this example, our null hypothesis comes directly from the study. The alternative hypothesis comes from the fact that the question implies that we are checking to see if the actual value is less than the hypothesized value.
Checking Conditions
Once we have our test confirmed and our hypothesis developed, we need to check our conditions for inference to be sure that our test can accurately be carried out. Just as with confidence intervals, we have 3 conditions:
- Random
- Independent
- Normal
For matched pairs, apply these same checks to the differences (the list of d values).
Random
If we are planning on using our sample statistics to develop a statistical test, it is imperative that our sample was chosen randomly. This is important because we are planning on using our sample mean to draw inference or conclusions about our population mean.
Data should come from a random sample or a randomized experiment.
If our sample is not chosen randomly to mirror our population, we cannot make statistical claims about the given population.
Independence
Since we are more than likely sampling without replacement, our sample is not truly independent. However, if our sample is not super close to the population, the effect of sampling without replacement is said to be negligible enough that our sample is essentially independent.
To check that this condition is met, we must verify that it is reasonable to believe that our population is at least 10x that of our sample.
You should state, "It is reasonable to believe that there are ____ (10n) _________ (in context of our population)"
For matched pairs, the 10% condition applies to the number of pairs: verify that the number of pairs n satisfies n ≤ 0.1N (the population of pairs is at least 10n).
Normal
We use the t distribution for inference about a mean when σ is unknown; the conditions ensure the sampling distribution of the t-statistic is approximately t.
There are three options to check this:
- If the observed distribution is skewed, use n > 30.
- If n < 30, the sample data should be free from strong skewness and outliers.
- If the population is approximately normal, proceed regardless of n.
Checking these conditions in this order will be the least cumbersome attempt in verifying the normal condition. Only one is necessary to verify normality. For matched pairs, apply these checks to the distribution of the differences (the d values).
Vocabulary
The following words are mentioned explicitly in the College Board Course and Exam Description for this topic.Term | Definition |
|---|---|
10% condition | The requirement that sample size n is at most 10% of the population size N to ensure independence when sampling without replacement. |
alternative hypothesis | The claim that contradicts the null hypothesis, representing what the researcher is trying to find evidence for. |
approximately normal | A distribution that closely follows the shape of a normal distribution, allowing for the use of normal probability methods. |
conditions for the test | The requirements that must be satisfied before conducting a hypothesis test for a population mean, including independence and normality of the sampling distribution. |
independence | The condition that observations in a sample are not influenced by each other, typically ensured through random sampling or randomized experiments. |
matched pairs | Paired observations where two measurements are taken on the same subject or on subjects that are matched according to specific criteria, used to analyze the mean difference between the paired values. |
mean difference | The average of the differences between paired observations, denoted by μd, where the order of subtraction must be clearly defined. |
null hypothesis | The initial claim or assumption being tested in a hypothesis test, typically stating that there is no effect or no difference. |
one-sample t-test | A hypothesis test used to determine whether a population mean differs from a hypothesized value when the population standard deviation is unknown. |
outlier | Data points that are unusually small or large relative to the rest of the data. |
population mean | The average of all values in an entire population, denoted as μ. |
population means | The average values of two distinct populations being compared, denoted as μ₁ and μ₂. |
random sample | A sample selected from a population in such a way that every member has an equal chance of being chosen, reducing bias and allowing for valid statistical inference. |
randomized experiment | A study design where subjects are randomly assigned to treatment groups to establish cause-and-effect relationships. |
sample size | The number of observations or data points collected in a sample, denoted as n. |
sampling distribution | The probability distribution of a sample statistic (such as a sample proportion) obtained from repeated sampling of a population. |
sampling without replacement | A sampling method in which an item selected from a population cannot be selected again in subsequent draws. |
significance test | A statistical procedure used to determine whether there is sufficient evidence to reject the null hypothesis based on sample data. |
skewness | A measure of the asymmetry of a distribution, indicating whether data is concentrated more on one side of the center. |
Frequently Asked Questions
When do you use a one-sample t-test for a population mean?
Use a one-sample t-test when you are testing a claim about a population mean and the population standard deviation sigma is unknown.
What are the hypotheses for a population mean test?
The null hypothesis is H0: mu = mu0. The alternative is Ha: mu < mu0, mu > mu0, or mu not equal to mu0, depending on the question.
What is the p-value in a one-sample t-test?
The p-value is the probability, assuming the null hypothesis is true, of getting a test statistic as extreme as or more extreme than the observed result.
What conditions do you check for a one-sample t-test?
Check that the data come from a random sample or randomized experiment, that observations are independent, and that the sampling distribution is approximately normal.
How do matched pairs work in a t-test?
For matched pairs, calculate a difference for each pair, define the order of subtraction, and then perform a one-sample t-test on the mean difference.
How do you choose the alternative hypothesis?
Choose the alternative based on the claim in context. Use less than, greater than, or not equal to depending on whether the question is one-sided or two-sided.