📚AP Statistics Unit 3 Review
3.9 Sampling Distributions for the Difference Between Sample Proportions
3.9 Sampling Distributions for the Difference Between Sample Proportions
Unit & Topic Study Guides
Unit 1 – Exploring One–Variable Data and Collecting Data
Unit 2 – Probability, Random Variables, and Probability Distributions
Unit 3 – Inference for Categorical Data: Proportions
Unit 4 – Inference for Quantitative Data: Means
Unit 5 – Regression Analysis
AP Statistics Exam
Statistical Practices
Exam Skills
When you compare two groups by subtracting their sample proportions, the result has its own sampling distribution. Its center is the true difference , its standard deviation is , and it is approximately normal when all four large-counts checks pass.
Why This Matters for the AP Statistics Exam
This topic is the bridge between single-proportion sampling distributions and the two-sample proportion inference you will do later in revised Unit 3. Before you can build a confidence interval or run a test for the difference between two population proportions, you need to know the center, spread, and shape of the distribution of p̂₁ - p̂₂.
On the exam you may be asked to find these parameters, check whether the normal model applies, calculate a probability for an observed difference, or interpret what the distribution means in context. Showing the formula, your large-counts checks, and a contextual interpretation is important for clear exam work.

Key Takeaways
- The mean of the distribution of p̂₁ - p̂₂ is the difference in population proportions: μ(p̂₁-p̂₂) = p₁ - p₂.
- The standard deviation is σ(p̂₁-p̂₂) = √(p₁(1-p₁)/n₁ + p₂(1-p₂)/n₂). Variances add, then take the square root.
- The model is approximately normal only when all four counts are large: n₁p₁ ≥ 10, n₁(1-p₁) ≥ 10, n₂p₂ ≥ 10, n₂(1-p₂) ≥ 10.
- For proportions you check the large-counts (success-failure) condition, not the Central Limit Theorem. CLT applies to means.
- The two samples must come from two independent populations.
- When sampling without replacement, the true standard deviation is slightly smaller, but the difference is negligible if each sample is less than 10% of its population.
How the Distribution Works
The phrase "variances add" is the key to all difference distributions. Even though you subtract the two sample proportions, you add their variances before taking a square root for the standard deviation.
Center (mean):
μ(p̂₁-p̂₂) = p₁ - p₂
Spread (standard deviation):
σ(p̂₁-p̂₂) = √(p₁(1-p₁)/n₁ + p₂(1-p₂)/n₂)
Each piece p(1-p)/n is the variance of one group's sample proportion. You add those two variances, then square root the total. Some people call this the "Pythagorean Theorem of statistics" because you combine two squared pieces under a single square root.
Shape: The distribution of p̂₁ - p̂₂ is approximately normal when all four of these are met:
- n₁p₁ ≥ 10
- n₁(1 - p₁) ≥ 10
- n₂p₂ ≥ 10
- n₂(1 - p₂) ≥ 10
If any expected count falls below 10, the distribution can be skewed and the normal model may not be safe.
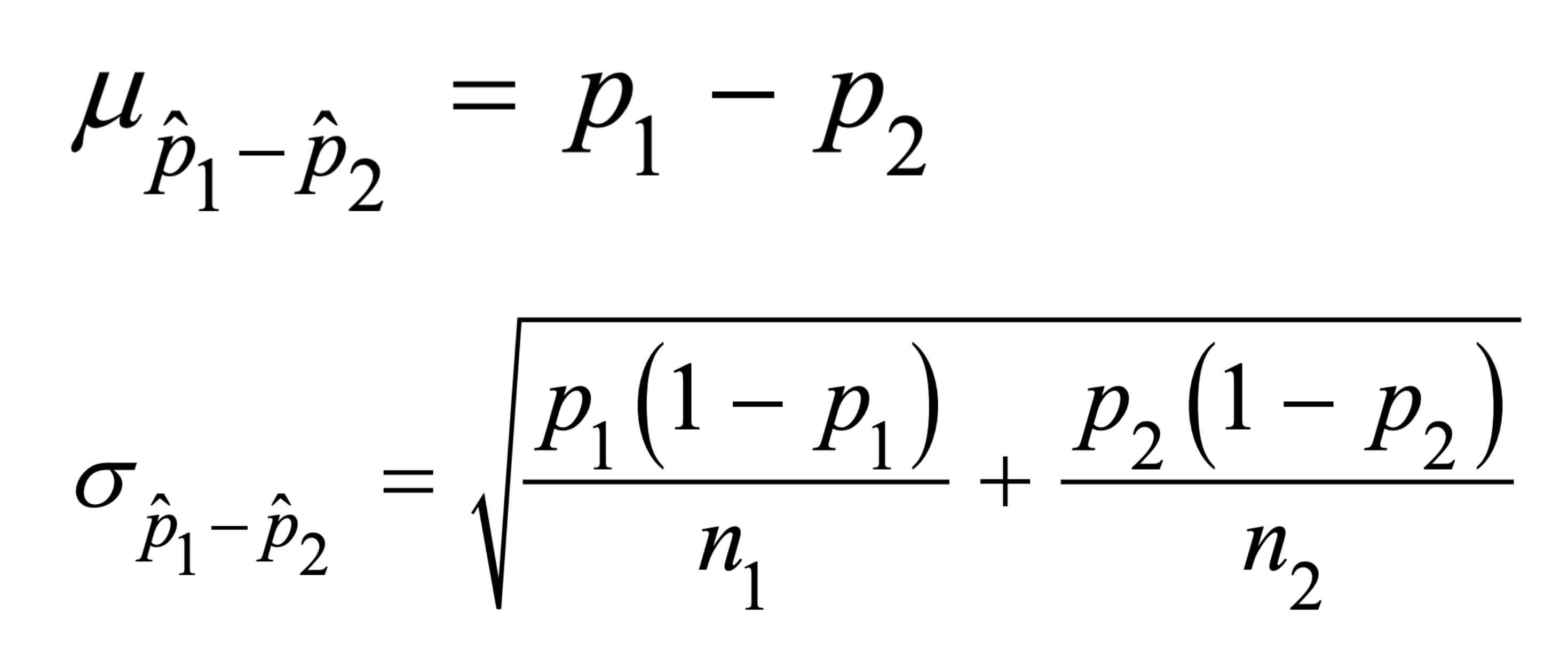
Source: AP Statistics Formula Sheet

This notation table is worth saving for quick reference.
How to Use This on the AP Statistics Exam
Problem Solving
-
Identify the two population proportions and sample sizes.
-
Find the center: p₁ - p₂.
-
Find the spread by adding the two variances p(1-p)/n, then square rooting.
-
Check all four large-counts conditions to confirm approximate normality.
-
If a probability is asked, standardize the observed difference with a z-score and use the normal model.
-
Interpret your answer in context, with units and a clear reference to both populations.
Common Trap
A frequent mistake is taking the square root of each group separately and then adding the standard deviations. That is wrong. You must add the variances first, then take one square root of the total.
Practice Problem
Suppose you are comparing the proportion of people in two cities who support a new public transportation system. You use simple random samples of 1000 people from each city. You find that 600 of the 1000 respondents from City A support the system, and 700 of the 1000 respondents from City B support the system.
a) Calculate the sample proportions of respondents who support the new system in each city.
b) Explain what the sampling distribution for the difference in sample proportions represents and why it is useful here.
c) Suppose the true population proportion in City A is 0.6 and in City B is 0.7. Describe the shape, center, and spread of the sampling distribution for the difference in sample proportions.
d) Explain why the difference in sample proportions can be modeled as approximately normal in this situation.
e) Discuss one potential source of bias that could affect the results, and explain how it could influence the estimate. (Hint: think about how this differs when working with two samples instead of one.)
Answer
a) City A: 600/1000 = 0.6. City B: 700/1000 = 0.7.
b) The sampling distribution for the difference in sample proportions represents the distribution of possible values of p̂₁ - p̂₂ if the study were repeated many times. It is useful because it lets you make inferences about the difference between the two population proportions based on the sample data.
c) If you define the difference as City A minus City B, the center is 0.6 - 0.7 = -0.1. If you define it as City B minus City A, the center is 0.7 - 0.6 = 0.1. The spread is the same either way: √(0.6(0.4)/1000 + 0.7(0.3)/1000) ≈ √(0.00024 + 0.00021) ≈ 0.0212. The shape is approximately normal because all four large-counts conditions are met.
d) All four expected counts are large: 1000(0.6) = 600, 1000(0.4) = 400, 1000(0.7) = 700, and 1000(0.3) = 300, all well above 10. With large counts satisfied for both groups, the distribution of p̂₁ - p̂₂ is approximately normal.
e) Nonresponse bias is one possibility. If supporters in City A are more likely to respond, that sample could overestimate support there. If people in City B who oppose the system are more likely to respond, that sample could underestimate support there. With two samples, bias in either group can distort the estimated difference, so you have to watch the response patterns in both cities, not just one.
Common Misconceptions
- Adding standard deviations instead of variances. Always add the two variances p(1-p)/n first, then square root once. Standard deviations do not add directly.
- Using the Central Limit Theorem for proportions. For proportions, you confirm normality with the large-counts (success-failure) checks. CLT is the justification you use for sample means.
- Checking only one group's counts. All four conditions must pass: both successes and failures, for both groups.
- Forgetting the independence requirement. The two samples must come from two independent populations for these formulas to apply.
- Ignoring the without-replacement adjustment. If a sample is 10% or more of its population, the true standard deviation is smaller than the formula gives. Below 10%, you can ignore the difference.
- Treating the sign of the difference as fixed. p̂₁ - p̂₂ and p̂₂ - p̂₁ have the same spread but opposite-signed centers. Be consistent about which group you label first.
Related AP Statistics Guides
Vocabulary
The following words are mentioned explicitly in the AP® course framework for this topic.Term | Definition |
|---|---|
approximately normal | A distribution that closely follows the shape of a normal distribution, allowing for the use of normal probability methods. |
categorical variable | A variable that takes on values that are category names or group labels rather than numerical values. |
difference in proportions | The difference between two population proportions, calculated as p₁ - p₂, used to compare the prevalence of a characteristic across two populations. |
difference in sample proportions | The difference between two sample proportions (p̂₁ - p̂₂) used to compare proportions from two different samples. |
independent populations | Two populations from which samples are drawn such that the selection from one population does not affect the selection from the other. |
mean of the sampling distribution | The expected value of a sample statistic; for sample proportions, μp̂ = p. |
normality conditions | The requirements that must be met for a sampling distribution to be approximately normal, such as n₁p₁ ≥ 10, n₁(1-p₁) ≥ 10, n₂p₂ ≥ 10, and n₂(1-p₂) ≥ 10. |
parameter | A numerical summary that describes a characteristic of an entire population. |
population proportion | The true proportion or percentage of a characteristic in an entire population, typically denoted as p. |
probability | The likelihood or chance that a particular outcome or event will occur, expressed as a value between 0 and 1. |
sample proportion | The proportion of individuals in a sample that have a particular characteristic, denoted as p-hat (p̂). |
sample size | The number of observations or data points collected in a sample, denoted as n. |
sampling distribution | The probability distribution of a sample statistic (such as a sample proportion) obtained from repeated sampling of a population. |
sampling with replacement | A sampling method in which an item selected from a population can be selected again in subsequent draws. |
sampling without replacement | A sampling method in which an item selected from a population cannot be selected again in subsequent draws. |
standard deviation of the sampling distribution | The measure of variability in a sampling distribution; for sample proportions, σp̂ = √(p(1-p)/n). |
Frequently Asked Questions
What is the sampling distribution for a difference in sample proportions?
It is the distribution of possible values of p-hat 1 minus p-hat 2 from repeated samples from two independent populations. It shows how the difference between two sample proportions varies from sample to sample.
What is the mean of p-hat 1 minus p-hat 2?
The mean of the sampling distribution is p1 - p2, the difference between the two population proportions. The sign depends on which group you label first.
What is the standard deviation formula for a difference in sample proportions?
The standard deviation is the square root of p1(1 - p1)/n1 plus p2(1 - p2)/n2. You add the variances first, then take one square root.
When is p-hat 1 minus p-hat 2 approximately normal?
The distribution is approximately normal when all four large-counts checks pass: n1p1, n1(1 - p1), n2p2, and n2(1 - p2) are each at least 10.
Why do variances add when subtracting sample proportions?
Independent random quantities combine by adding variances. So even though the statistic is a difference, the spread uses the sum of the two variances before taking the square root.
How is AP Stats 5.6 tested?
AP Stats 5.6 can ask you to find the center and spread, check the large-counts condition, use a normal model to calculate probability, or interpret p-hat 1 minus p-hat 2 in context.