📚AP Statistics Unit 2 Review
2.2 Summary Statistics for Two Categorical Variables
2.2 Summary Statistics for Two Categorical Variables
Unit & Topic Study Guides
Unit 1 – Exploring One–Variable Data and Collecting Data
Unit 2 – Probability, Random Variables, and Probability Distributions
Unit 3 – Inference for Categorical Data: Proportions
Unit 4 – Inference for Quantitative Data: Means
Unit 5 – Regression Analysis
AP Statistics Exam
Statistical Practices
Exam Skills
This topic is about reading a two-way table and calculating the right kind of relative frequency to compare two categorical variables. The three types you need are joint, marginal, and conditional relative frequencies, and comparing conditional relative frequencies is how you decide whether two categorical variables are associated.
Why This Matters for the AP Statistics Exam
Two-way tables show up across the AP Statistics exam, so getting comfortable with relative frequencies now pays off later. The skills here support both multiple-choice and free-response work where you read a contingency table, pick the correct calculation, and explain what it means in context.
You will also reuse this thinking in later units. The same table logic connects to conditional probability and independence in probability, and to chi-square tests for association in inference. Building fluency now makes those later topics easier.

Key Takeaways
- A joint relative frequency is one cell divided by the grand total.
- A marginal relative frequency is a row total or column total divided by the grand total.
- A conditional relative frequency is a cell divided by its own row total or column total, not the grand total.
- The "given" category sets your denominator, so a conditional relative frequency usually has a smaller total than a marginal one.
- To check for association, compare conditional relative frequencies across categories. If they differ noticeably, the variables are associated.
- If a conditional relative frequency roughly matches the marginal relative frequency for that response, that points toward no association.
Three Kinds of Relative Frequencies
Start with a two-way table (also called a contingency table) that summarizes two categorical variables. The cells hold counts, the row and column totals sit in the margins, and the grand total is the count for everyone.

From this single table you can pull three different relative frequencies depending on what you divide by.
Joint Relative Frequency
A joint relative frequency is a single cell divided by the grand total. It answers "what fraction of everyone is in this specific combination of both categories?"
Marginal Relative Frequency
A marginal relative frequency uses a row total or column total divided by the grand total. It describes one variable at a time, ignoring the other.
For example, the marginal relative frequency of a "50-50 chance" is 1416/4826, because the right margin shows that 1416 of the 4826 total respondents gave that response.
Conditional Relative Frequency
A conditional relative frequency is a relative frequency for one specific part of the table, such as a cell divided by its own row total or column total. The category you already know is the "given," and it sets your denominator.
For example, the conditional relative frequency for "50-50 chance given male" is 720/2459, because out of the 2459 males who responded, 720 said "50-50 chance." Notice the denominator (2459) is smaller than the grand total, which is normal for a conditional relative frequency.
Determining Associations from a Two-Way Table
You can use marginal and conditional relative frequencies to decide whether two categorical variables are associated.
The main move is to compare conditional relative frequencies across different categories. If two corresponding conditional relative frequencies are clearly different, the variables are associated, meaning knowing one category helps you predict the other. You can also compare a conditional relative frequency to the marginal relative frequency for that same response. If they line up closely, that suggests no association.
Worked Example
Using the table above, the variables "gender" and "opinion" look independent, or not associated, because the marginal relative frequency of "50-50 chance" is roughly equal to the conditional relative frequency of "50-50 chance given male."
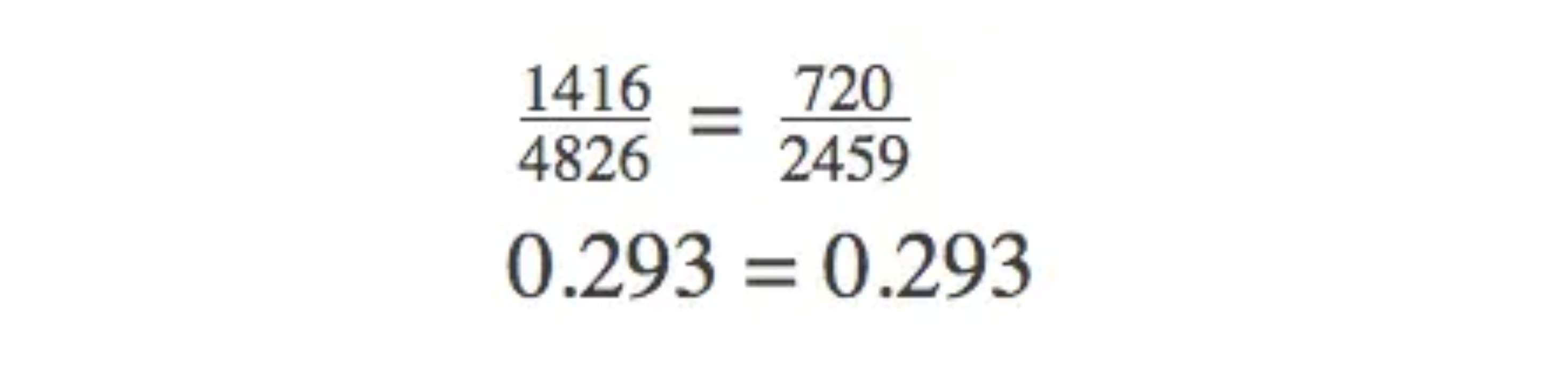
When you compare these on the exam, use clear language. Say something like "about the same proportion of males and females chose 50-50, so there is little evidence of an association," rather than just reporting two fractions.
How to Use This on the AP Statistics Exam
Problem Solving
- Read the question to decide which total you need. Grand total points to joint or marginal; a single row or column total points to conditional.
- Write the fraction before simplifying so your setup is clear, for example 720/2459.
- Convert to a percentage or decimal so comparisons are easy to read.
Free Response
- State the type of relative frequency you are calculating so your reasoning is easy to follow.
- When asked about association, compare conditional relative frequencies across groups, then write a sentence that ties the numbers back to the context.
- Use careful wording like "tend to" and name the actual categories and variables instead of saying "the two groups."
Common Trap
- Do not divide by the grand total when the question says "given." A conditional relative frequency uses the subgroup total.
Common Misconceptions
- Mixing up marginal and conditional: a marginal relative frequency uses a margin total, while a conditional one uses a single row or column as its denominator.
- Thinking the "given" group is always larger: the conditioning category usually makes the denominator smaller than the grand total.
- Assuming any difference means association: small differences can happen by chance, so compare whether conditional relative frequencies are clearly different, not just slightly off.
- Treating association as causation: an association between two categorical variables does not prove one causes the other.
- Calling categorical association "correlation": save the word correlation for relationships between two quantitative variables.
Vocabulary Practice from 2.1 to 2.3 Material
Match the number with the letter that corresponds to its description!
-
Two-way tables
-
Mosaic plots
-
Segmented bar graphs
-
Categorical variable
-
Quantitative variable
-
Bivariate variable
-
Marginal relative frequency
-
Conditional relative frequency
A. A graphical display that shows the relationship between two categorical variables by dividing the area of a rectangle into tiles that represent the different categories of both variables.
B. A graphical display that shows the distribution of a categorical variable by displaying the frequency or relative frequency of each category as a bar.
C. A graphical display that shows the relationship between two categorical variables by dividing the bars in a bar graph into segments that represent the different categories of one of the variables.
D. A statistical table that shows the frequencies or relative frequencies of two categorical variables in a cross-tabulated format, with one variable represented by rows and the other by columns.
E. A variable that can take on a limited number of categories or values, such as "male" or "female," but cannot be meaningfully ordered or measured on a continuous scale.
F. A variable that can be measured or ordered on a continuous scale, such as height or weight.
G. The relative frequency of a particular category of a categorical variable within another category, calculated by dividing the frequency or relative frequency of the first category within the second category by the total frequency or relative frequency of the second category.
H. The frequency or relative frequency of a particular category of a categorical variable, calculated by dividing the frequency or relative frequency of that category by the total frequency or relative frequency for the entire sample or population.
I. A statistical concept that refers to the relationship between two variables, often used to describe the association between two categorical variables.
Answers
-
D
-
B
-
A
-
C
-
E
-
F
-
I
-
H
-
G
Related AP Statistics Guides
Vocabulary
The following words are mentioned explicitly in the AP® course framework for this topic.Term | Definition |
|---|---|
association | The relationship between two variables where knowing the value of one variable provides information about the other variable. |
categorical variable | A variable that takes on values that are category names or group labels rather than numerical values. |
conditional relative frequency | A relative frequency for a specific part of a contingency table, such as cell frequencies in a row divided by the total for that row. |
distribution | The pattern of how data values are spread or arranged across a range. |
marginal relative frequencies | The row and column totals in a two-way table divided by the total for the entire table, representing the proportion of observations in each row or column. |
summary statistics | Numerical measures that describe key features of a dataset, such as center, spread, and shape. |
two-way table | A table that displays the frequency distribution of two categorical variables, organized in rows and columns. |
Frequently Asked Questions
What is conditional relative frequency?
A conditional relative frequency is a cell count divided by the total for the row or column you are conditioning on, not by the grand total.
What is joint relative frequency?
A joint relative frequency is one cell in a two-way table divided by the grand total for the entire table.
What is marginal relative frequency?
A marginal relative frequency is a row total or column total divided by the grand total.
How do you know which denominator to use in a two-way table?
Use the grand total for joint or marginal relative frequencies. Use the row or column total when the question says given or asks for a conditional relative frequency.
How do you identify association between two categorical variables?
Compare conditional relative frequencies across groups. Noticeably different conditional distributions suggest the variables are associated.
Does association between categorical variables prove causation?
No. Association means the variables are related in the data, but it does not prove that one variable causes the other.