📚AP Statistics Unit 2 Review
2.8 Introduction to Random Variables and Probability Distributions
2.8 Introduction to Random Variables and Probability Distributions
Unit & Topic Study Guides
Unit 1 – Exploring One–Variable Data and Collecting Data
Unit 2 – Probability, Random Variables, and Probability Distributions
Unit 3 – Inference for Categorical Data: Proportions
Unit 4 – Inference for Quantitative Data: Means
Unit 5 – Regression Analysis
AP Statistics Exam
Statistical Practices
Exam Skills
AP Statistics 4.7 Random Variables Summary
A random variable assigns a number to each outcome of a random process, and its probability distribution lists every possible value along with the probability of getting it. In AP Statistics, the random variable of interest is the specific quantity you define before doing probability work. You mostly work with discrete random variables here, where you can represent the distribution as a table, graph, or function, and where all the probabilities add up to 1.

Why This Matters for the AP Statistics Exam
This topic is the foundation for everything in the rest of Unit 4, including the mean and standard deviation of random variables, combining random variables, and the binomial and geometric distributions. Once you can read and build a probability distribution, you can calculate probabilities for ranges of values, describe shape, center, and spread, and interpret what those numbers mean in context.
On the exam, expect to recognize and use probability distributions in both multiple-choice and free-response settings. You may need to read a probability table or histogram, add the right probabilities for a phrase like "at least 4," and then explain your result using correct units and the situation in the problem. Showing the expression you used, the values you plugged in, and a final answer makes your work clear and easy to follow.
Key Takeaways
- The values of a random variable are the numerical outcomes of random behavior, often labeled with capital letters like X or Y.
- A discrete random variable can take only a countable number of values, and each value has a probability attached to it.
- The probabilities over all possible values must sum to 1.
- A probability distribution can be shown as a graph, a table, or a function.
- A cumulative probability distribution shows the probability of being less than or equal to each value, which is written as P(X ≤ x).
- Interpreting a distribution means describing its shape, center, and spread and connecting those features to the population in context.
What Is the Random Variable of Interest?
A random variable takes on different numerical values depending on the outcome of a random process. The random variable of interest is the quantity the problem asks you to track, such as "the number of heads in three coin flips" or "the number of cars passing through an intersection in an hour." The probability distribution of a random variable shows the probability of each value it can take. It is common to label random variables with capital letters such as X or Y.
A discrete random variable can take on only a countable number of values, like the number of heads in three coin flips or the number of cars passing through an intersection in an hour. Each value has its own probability, and you usually focus on the probability of specific values rather than intervals.
You may also hear about continuous random variables, which can take any value in a range, like a person's height or a runner's time. Those use a density curve, and finding their probabilities involves intervals rather than single values. The detailed math for continuous distributions is not part of this topic, so keep your attention on discrete random variables here.
In every case, the probabilities of all possible values must sum to 1, because some outcome always happens.
Representing a Discrete Distribution
You should be able to show a discrete random variable in a few ways:
- Table: list each value and its probability.
- Histogram: put the values of the random variable on the x-axis and the probabilities on the y-axis.
- Function: a rule that gives the probability for each value.
A sample probability distribution table looks like this:
| Value | x1 | x2 | x3 | x4 |
|---|---|---|---|---|
| Probability | p1 | p2 | p3 | p4 |
A cumulative probability distribution is a table or function that shows the probability of being less than or equal to each value. This is written P(X ≤ x), and it is useful when a question asks about a range of outcomes.
Reading "At Least" and "No More Than"
When you calculate probabilities for a discrete random variable, pay close attention to whether the boundary value is included.
- "At least 3" means 3 or more, so include 3.
- "No more than 3" means 3 or fewer, so include 3.
- "At most 3" also means 3 or fewer, so include 3.
- "Greater than 3" means strictly more than 3, so do not include 3.
Drawing a quick distribution table with all the values and their probabilities helps you see exactly which values to add. To find the probability that X equals a particular value n, use the notation P(X = n). For a range, add the probabilities of all the values that fit the phrase.
Interpreting Shape, Center, and Spread
Interpreting a probability distribution means describing its shape, center, and spread and using those features to make conclusions about the population.
For shape, you can describe whether the distribution is:
- Symmetric: values are balanced around the center.
- Single-peaked: one clear high point, where one group of values is more likely.
- Double-peaked: two distinct peaks, which can suggest two different groups of values.
- Right-skewed: most values are on the lower end with a long tail to the right.
- Left-skewed: most values are on the higher end with a long tail to the left.
For center and spread, the mean gives a sense of the typical value of the random variable, and the standard deviation describes how spread out the values are. You will learn how to calculate these in the next topic, but for now, name them and connect them to the context. A complete interpretation always uses units and ties back to the specific situation in the problem.
Worked Example
A study found that the probability a person develops a certain type of cancer is 0.01, independent of all other people. The table below shows the probability that exactly that number of people in a group of 10 will develop this type of cancer.
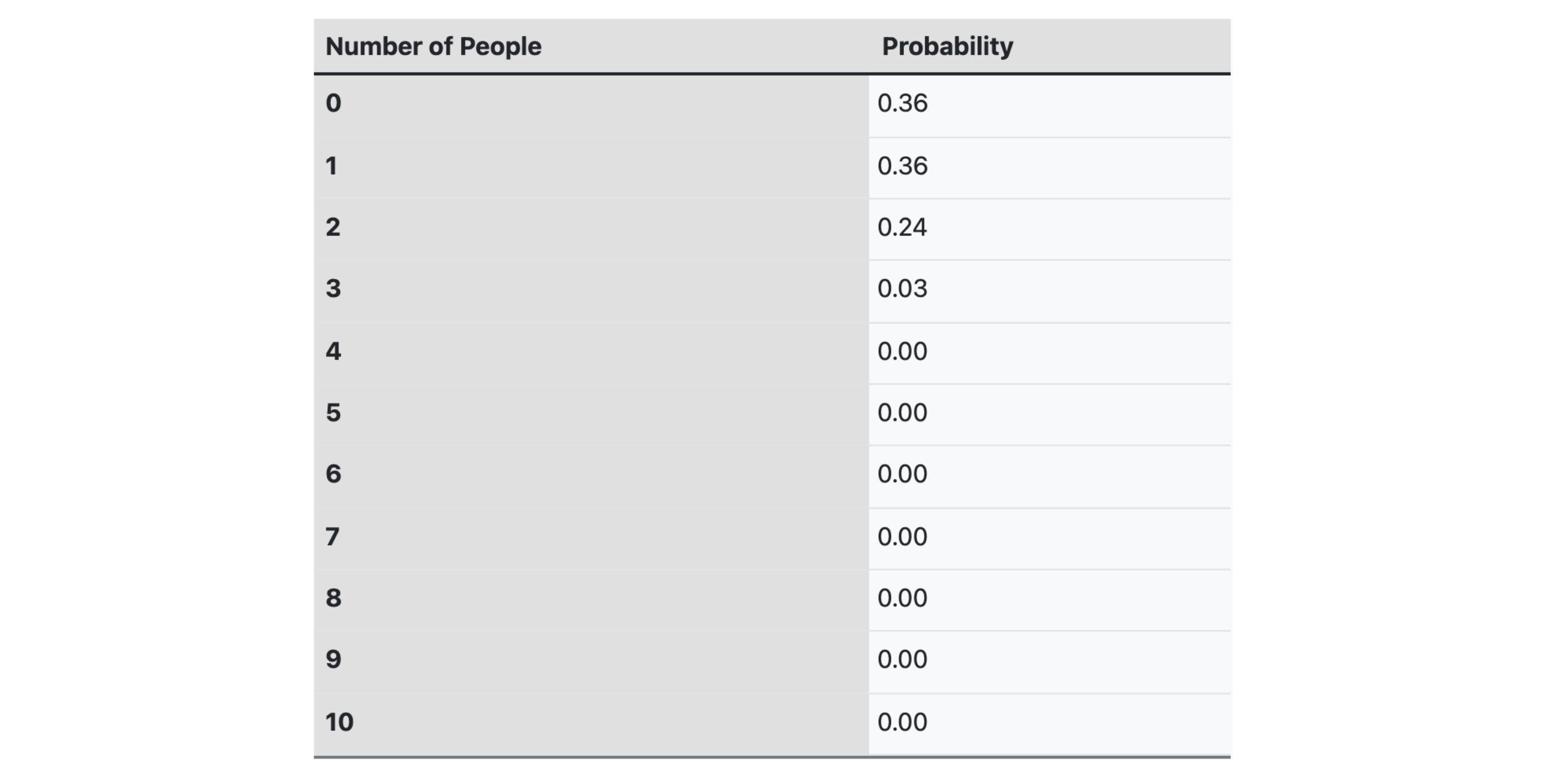
(a) What is the probability that at least 5 of a group of 10 people will develop this type of cancer?
"At least 5" means 5 or more, so add the probabilities for 5 through 10.
P(X ≥ 5) = 0.00 + 0.00 + 0.00 + 0.00 + 0.00 = 0.00
The probability that at least 5 of the 10 people develop this type of cancer is about 0.00.
(b) What is the probability that no more than 3 of a group of 10 people will develop this type of cancer?
"No more than 3" means 3 or fewer, so add the probabilities for 0, 1, 2, and 3.
P(X ≤ 3) = P(X = 0) + P(X = 1) + P(X = 2) + P(X = 3) = 0.36 + 0.36 + 0.24 + 0.03 = 0.99
The probability that no more than 3 of the 10 people develop this type of cancer is 0.99.
(c) What is the probability that at most 2 of a group of 10 people will develop this type of cancer?
"At most 2" means 2 or fewer, so add the probabilities for 0, 1, and 2.
P(X ≤ 2) = P(X = 0) + P(X = 1) + P(X = 2) = 0.36 + 0.36 + 0.24 = 0.96
The probability that at most 2 of the 10 people develop this type of cancer is 0.96.
How to Use This on the AP Statistics Exam
MCQ
- Read tables and histograms carefully and match the phrase in the question to the right values before adding probabilities.
- Use the rule that all probabilities sum to 1. If a single probability is missing, subtract the known ones from 1.
- Use the complement when it saves work. For "at least 5," it can be faster to compute 1 minus P(X ≤ 4) when the table allows it.
Free Response
- Write the probability expression you are using, such as P(X ≤ 3) = P(X = 0) + P(X = 1) + P(X = 2) + P(X = 3), then substitute values, then give the answer.
- Include units and context when you interpret a result, not just a bare number.
- When you describe a distribution, hit shape, center, and spread and tie each to the situation.
Common Trap
- Mixing up strict and inclusive boundaries. "Greater than 3" excludes 3, while "at least 3" includes it. A quick distribution table prevents this mistake.
Common Misconceptions
- Thinking probabilities do not have to add to 1. For any discrete random variable, the probabilities over all possible values must sum to exactly 1. If they do not, something is missing or wrong.
- Confusing "at least" with "greater than." "At least 3" includes 3, but "greater than 3" does not. Always check whether the boundary value belongs in the sum.
- Treating P(X = x) and P(X ≤ x) as the same thing. P(X = x) is the probability of a single value, while P(X ≤ x) is a cumulative probability that adds up everything at or below that value.
- Describing a distribution with only one feature. A complete interpretation covers shape, center, and spread, and connects them to the population in context with units.
- Assuming every distribution is symmetric or bell-shaped. Discrete distributions can be skewed, single-peaked, or double-peaked, so describe what the graph actually shows.
Related AP Statistics Guides
Vocabulary
The following words are mentioned explicitly in the AP® course framework for this topic.Term | Definition |
|---|---|
center | A measure indicating the middle or typical value of a distribution. |
cumulative probability distribution | A representation (as a table or function) showing the probability that a random variable is less than or equal to each of its possible values. |
discrete random variable | A random variable that takes on a countable number of distinct values, often representing counts or categorical outcomes. |
population | The entire group of individuals or items from which a sample is drawn and about which conclusions are to be made. |
probability distribution | A function that describes the likelihood of all possible values of a random variable. |
random process | A process that generates results determined by chance, where the outcome cannot be predicted with certainty in advance. |
random variable | A variable whose value is determined by the outcome of a random phenomenon and can take on different numerical values with associated probabilities. |
shape | The overall form or pattern of a distribution, including characteristics like skewness and modality. |
spread | A measure of how dispersed or variable the outcomes of a probability distribution are, such as range, variance, or standard deviation. |
Frequently Asked Questions
What is a random variable in AP Statistics?
A random variable assigns a numerical value to each outcome of a random process. In AP Statistics, you usually name it with a capital letter, like X, and define exactly what quantity it measures before calculating probabilities.
What is the random variable of interest?
The random variable of interest is the specific quantity you are tracking in the problem, such as the number of successes, the number of people selected, or the sum from rolling dice. Defining it clearly keeps your probability notation and interpretation tied to the context.
What is a probability distribution in AP Stats?
A probability distribution shows every possible value of a random variable and the probability associated with each value. For a discrete random variable, those probabilities must add up to 1.
How can a discrete probability distribution be represented?
A discrete probability distribution can be represented with a table, graph, or function. A cumulative distribution can also show P(X ≤ x), the probability that the random variable is less than or equal to a value.
What does it mean to interpret a probability distribution?
Interpreting a probability distribution means describing its shape, center, and spread, then connecting those features to the population or process in context. A complete interpretation uses units when the variable has units.
What is the common AP Stats mistake with at least and at most?
The common mistake is excluding the boundary value. At least 3 means 3 or more, and at most 3 means 3 or fewer. Greater than 3 excludes 3, so read the wording before adding probabilities.