🏭Intro to Industrial Engineering Unit 3 Review
3.1 Fundamentals of Queuing Systems
3.1 Fundamentals of Queuing Systems
Unit & Topic Study Guides
Industrial Engineering: Systems Optimization
Operations Research & Linear Programming
Queuing Theory: Principles and Applications
Inventory Management Fundamentals
Production Planning & Scheduling
Facility Layout & Material Handling
Quality Control and Six Sigma
Ergonomics & Workplace Design
Supply Chain and Logistics Management
Simulation Modeling & Analysis
Project Management for Engineers
Engineering Economics & Cost Analysis
Lean Manufacturing & Continuous Improvement
Automation and Industrial Robotics
Queuing System Components
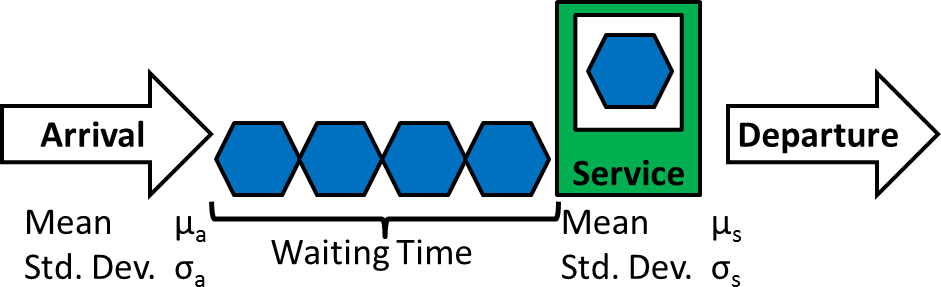
Queuing systems show up everywhere: bank teller lines, hospital waiting rooms, call centers, checkout counters. Each one consists of three core parts: customers who need service, servers who provide it, and a waiting line (queue) that forms when customers arrive faster than they can be served. Understanding how these parts interact is the foundation of queuing theory, which gives you the tools to analyze and improve service operations.
Fundamental Structure and Processes
The arrival process describes how customers enter the system. It's characterized by the arrival rate and the distribution of time between arrivals (inter-arrival time). Most basic models assume arrivals follow a Poisson process, which means customers show up randomly and independently of each other.
The service process describes how long it takes to serve each customer. It's defined by the service time distribution and the number of servers available. For mathematical convenience, service times are often assumed to follow an exponential distribution, though real systems can be more complex.
The queue discipline determines the order customers get served:
- First-Come-First-Served (FCFS): the standard "wait your turn" approach
- Last-Come-First-Served (LCFS): the most recent arrival gets served next (like a stack of papers on a desk)
- Priority-based: certain customer classes get served before others
Queue discipline directly affects both system performance and perceived fairness.
System Capacity and Population
System capacity is the maximum number of customers allowed in the system at once (both those waiting and those being served). Some systems have finite capacity, like a doctor's waiting room with 10 seats, while others are modeled as infinite, meaning there's no hard limit on how many can wait.
Customer population also matters. A finite population model applies when there's a limited pool of potential customers, such as a machine repair shop serving exactly 20 machines. An infinite population model assumes the pool of potential arrivals is essentially unlimited, like customers arriving at a retail store. The distinction changes how you set up and solve the model.
Queuing Notation and Customer Behavior
Kendall's notation provides a shorthand for describing queuing systems in the format A/B/C/K/N:
- A: distribution of inter-arrival times
- B: distribution of service times
- C: number of servers
- K (optional): maximum system capacity
- N (optional): size of the customer population
Common symbols for distributions include M (Markovian/exponential), D (deterministic/constant), G (general), and Ek (Erlang-k). So an M/M/1 system has Poisson arrivals, exponential service times, and one server with unlimited capacity and population.
Real customers don't always behave as neatly as models assume. Three common behaviors complicate analysis:
- Balking: a customer sees a long line and decides not to join at all (you glance at a 30-person restaurant line and leave)
- Reneging: a customer joins the queue but gets impatient and leaves before being served (walking out of a bank after waiting 20 minutes)
- Jockeying: a customer switches from one queue to another that looks shorter (moving to a different checkout lane at the grocery store)
Queuing Model Types
Basic Queuing Models
The M/M/1 model is the simplest and most commonly studied. Its assumptions:
- Arrivals follow a Poisson process (rate )
- Service times are exponentially distributed (rate )
- There is one server
- System capacity and customer population are both infinite
Think of a single bank teller at a small branch. Despite its simplicity, M/M/1 produces powerful insights that generalize to more complex systems.
The M/M/c model extends this to c identical servers working in parallel, all drawing from the same queue. Arrivals and service distributions stay the same. A supermarket with multiple checkout counters is a classic example.
Advanced Queuing Models
- Finite capacity models (M/M/c/K) cap the total number of customers in the system at K. Any customer arriving when the system is full gets turned away. A small clinic waiting room with limited seating fits this model.
- Non-Markovian models relax the exponential assumptions. An M/G/1 model keeps Poisson arrivals but allows any (general) service time distribution. A G/G/c model allows general distributions for both arrivals and service. These require more complex analysis but better represent systems like manufacturing lines with variable processing times.
- Priority queuing models assign different service priorities to different customer classes. An emergency room triage system is the textbook example: critical patients get treated before those with minor injuries, regardless of arrival order.
Specialized Queuing Models
Finite population models (M/M/c/N/N) apply when the customer pool has a fixed size N. As more customers enter the system, fewer remain in the population to generate new arrivals, so the effective arrival rate drops. A machine repair shop with exactly 15 machines is a good example: as more machines break down and enter the repair queue, fewer are running and able to break.
Bulk arrival or bulk service models handle situations where customers arrive or get served in groups rather than one at a time:
- Bulk arrival: a tour bus drops off 40 visitors at a theme park entrance all at once
- Bulk service: an elevator carries 10 passengers up simultaneously
Analyzing Queuing System Elements
Arrival Process Analysis
In a Poisson process, the times between consecutive arrivals (inter-arrival times) follow an exponential distribution. A key property of this distribution is the memoryless property:
This means the probability of waiting another minutes for the next arrival doesn't depend on how long you've already waited. The process has no "memory" of the past.
The arrival rate is the average number of customers arriving per unit time. The probability of exactly arrivals in time is given by the Poisson formula:
Not all systems have Poisson arrivals. Other distributions include:
- Erlang: models arrivals that are more regular (less variable) than Poisson
- Hyperexponential: models arrivals that are more variable than Poisson
Service Process Evaluation
When service times follow an exponential distribution, the probability density function is:
where is the service rate (average number of customers one server can handle per unit time).
For non-exponential service times, common alternatives include:
- Deterministic: every customer takes exactly the same time (like an automated car wash with a fixed 5-minute cycle)
- Erlang: service happens in multiple exponential phases (like a multi-step inspection process)
- General: any arbitrary distribution (complex manufacturing operations)
When you have identical servers, the combined service capacity is:
Queue Discipline Impact
FCFS is the most common discipline and the easiest to analyze mathematically. It feels fair to customers, but it doesn't always optimize overall system performance.
Priority disciplines come in two flavors:
- Preemptive: a high-priority arrival actually interrupts the service of a lower-priority customer (think emergency surgery bumping a scheduled procedure off the operating table mid-prep)
- Non-preemptive: a high-priority arrival moves to the front of the queue but doesn't interrupt whoever is currently being served (VIP ticket holders board next, but the current passenger finishes boarding first)
The choice of discipline affects waiting times across customer classes and can significantly influence both efficiency and customer satisfaction.
Performance Measures for Queuing Systems
Fundamental Relationships
Little's Law is one of the most important results in queuing theory. It relates three quantities:
where is the average number of customers in the system, is the arrival rate, and is the average time a customer spends in the system. This relationship holds remarkably broadly, applying to the queue alone, the service area alone, or the entire system.
Example: If customers/hour and each spends an average of hours (30 minutes) in the system, then customers in the system on average.
System utilization measures how busy the servers are:
where is the number of servers. For the system to be stable (queue doesn't grow without bound), you need .
Example: If customers/hour, customers/hour, and , then . The server is busy 83% of the time.
Queue and System Metrics
For the M/M/1 model, all key metrics can be derived from :
- Average number in queue:
- Average number in system (queue + service):
- Average waiting time in queue:
- Average time in system:
- Probability of customers in system:
- Probability system is empty:
Notice how all of these blow up as approaches 1. A system running at 95% utilization has far longer waits than one at 80%. This nonlinear relationship between utilization and wait times is one of the most important practical takeaways from queuing theory.
Advanced Performance Analysis
Idle time is simply the complement of utilization: if , servers are idle 20% of the time. This matters for capacity planning because you're paying for server time whether it's used or not.
For priority queuing systems, performance measures are calculated separately for each priority class. Higher-priority customers enjoy shorter waits, but at the expense of longer waits for lower-priority classes. The overall system utilization stays the same regardless of discipline.
Sensitivity analysis explores how changes in parameters ripple through the system. For instance, if you double the arrival rate in an M/M/1 system that was at , utilization jumps to 0.8, and the average number in the queue goes from to . That's roughly a 12x increase in queue length from a 2x increase in arrivals.
Cost-benefit analysis ties the math to real decisions. The goal is typically to minimize total cost, which combines:
- Waiting cost: the cost of customers spending time in the system (lost productivity, dissatisfaction)
- Service cost: the cost of running servers (staffing, equipment)
Adding servers reduces waiting costs but increases service costs. The optimal number of servers balances these two competing factors.