🎲Intro to Statistics Unit 9 Review
9.5 Additional Information and Full Hypothesis Test Examples
9.5 Additional Information and Full Hypothesis Test Examples
Unit & Topic Study Guides
Sampling and Data
Descriptive Statistics
Probability Topics
Discrete Random Variables
Continuous Random Variables
The Normal Distribution
The Central Limit Theorem
Confidence Intervals
Hypothesis Testing: Single Sample
Two-Sample Hypothesis Testing
Chi-Square Distribution
Linear Regression and Correlation
Hypothesis Testing
Significance and p-value interpretation
The level of significance () is the threshold you set before running a test. It represents the probability of committing a Type I error, which means rejecting the null hypothesis when it's actually true.
- Common values: 0.01, 0.05, 0.10
- A smaller makes the test more stringent, meaning you need stronger evidence to reject
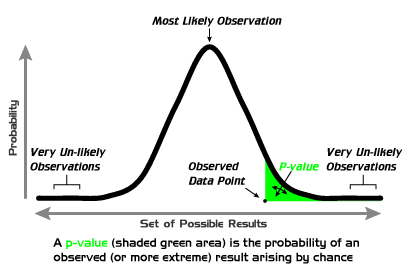
The p-value is calculated after you collect data. It tells you the probability of getting a sample result as extreme as (or more extreme than) what you observed, assuming the null hypothesis is true.
The decision rule is straightforward:
- Reject if p-value <
- Fail to reject if p-value ≥
For example, if you set and your test produces a p-value of 0.02, you reject because 0.02 < 0.05. The sample data is unlikely enough under that you have evidence against it.
One thing that trips people up: "fail to reject" is not the same as "accept." You're never proving is true. You're just saying you didn't find enough evidence against it.
The rejection region is the set of test statistic values that would lead you to reject . It corresponds directly to your chosen .
Types of hypothesis tests
The direction of your alternative hypothesis () determines what kind of test you run.
- Left-tailed test: claims the parameter is less than a specific value
- The critical region sits in the left tail of the distribution
- Example:
- Right-tailed test: claims the parameter is greater than a specific value
- The critical region sits in the right tail
- Example:
- Two-tailed test: claims the parameter is not equal to a specific value
- The critical region is split between both tails, with in each
- Example:
How do you choose? Think about the research question. If you only care whether something is lower (or only whether it's higher), use a one-tailed test. If you care about any difference in either direction, use two-tailed.

Hypothesis testing for proportions
When you're testing a claim about a population proportion, you use a z-test. Here's the full process:
-
State the hypotheses.
- Null hypothesis: (the population proportion equals some claimed value)
- Alternative hypothesis: , , or , depending on the research question
-
Set the significance level () and identify the test type (left-tailed, right-tailed, or two-tailed).
-
Calculate the test statistic using the formula:
- = sample proportion (successes divided by sample size)
- = the proportion claimed in
- = sample size
- The denominator is the standard error, which measures how much typically varies from due to random sampling
-
Find the p-value using the z-score and the standard normal distribution:
- Left-tailed: p-value =
- Right-tailed: p-value =
- Two-tailed: p-value =
-
Make a decision.
- Reject if p-value <
- Fail to reject if p-value ≥
-
Interpret the result in context. Don't just say "reject" or "fail to reject." Translate the conclusion back into the language of the problem.
Worked example: A company claims that 60% of customers prefer their product. You survey 200 people and find that 108 prefer it (). Test at whether the true proportion is less than 0.60.
- , (left-tailed)
- p-value =
- Since 0.0418 < 0.05, reject
- Conclusion: There is sufficient evidence at the 0.05 level to suggest that the true proportion of customers who prefer the product is less than 60%.
Additional Considerations in Hypothesis Testing
A few more concepts that come up alongside hypothesis testing:
- Confidence interval: A range of plausible values for the population parameter. If a 95% confidence interval for doesn't contain , that's consistent with rejecting at . Confidence intervals and hypothesis tests are closely related.
- Statistical power: The probability of correctly rejecting when it's actually false (i.e., detecting a real effect). Power increases with larger sample sizes and larger effect sizes. Low power means you might miss a real difference.
- Effect size: Measures how big the difference is, not just whether it exists. A statistically significant result can have a tiny effect size, which may not matter in practice.
- Degrees of freedom: The number of independent values in a dataset that are free to vary. This concept matters more when you move to t-tests (coming up soon), where degrees of freedom affect the shape of the distribution you use.