Measures of the Center of the Data
Central tendency measures tell you what a "typical" value looks like in a dataset. The three main measures are the mean, median, and mode, and each one captures something different. The mean is sensitive to outliers, the median resists them, and the mode highlights the most common value. Knowing when to use each one is a core skill in statistics.
Sample means estimate population means, which matters because you almost never have access to an entire population. Beyond individual measures, the shape of a distribution (unimodal, bimodal, multimodal) tells you how data clusters and whether a single "center" even makes sense.

Measures of Central Tendency

Calculation of Mean and Median
Mean (arithmetic average)
The mean is the sum of all values divided by how many values there are:
- Symbolized as for a sample mean and for a population mean
- Heavily influenced by outliers. For example, if five people earn $40k, $45k, $50k, $55k, and $300k, the mean is $98k, which doesn't represent anyone in the group well.
- Best used when data is roughly symmetric (bell-shaped) with no extreme values pulling it in one direction
Median
The median is the middle value when you arrange all data points in order from smallest to largest.
- If is odd, the median is the single middle value. If is even, take the average of the two middle values.
- Not affected by outliers. In the income example above, the median is $50k, which better represents the group.
- Preferred when data is skewed or contains outliers (income data, home prices, and heavily skewed test score distributions are classic cases)
How to find the median, step by step:
- Sort the dataset from smallest to largest
- Count the number of values ()
- If is odd, the median is the value at position
- If is even, find the two values at positions and , then average them
Sample vs. Population Means
The distinction between sample and population means shows up constantly in statistics, so it's worth being precise about it.
- Sample mean (): Computed from a subset (sample) of the population. It provides an estimate of the population mean and will vary from sample to sample due to sampling variability (sometimes called sampling error, though it's not a "mistake").
- Population mean (): The true average calculated from every member of the population. In practice, is almost always unknown. That's why we collect samples and use to estimate it.
The reason this matters: much of inferential statistics is about quantifying how close is likely to be to .
Weighted Mean
Sometimes not all data points contribute equally. A weighted mean multiplies each value by its weight before summing:
A common example: your course grade. If exams are worth 60% and homework is worth 40%, you wouldn't just average your exam and homework scores equally. You'd weight them by their respective percentages.
Mode and Data Distribution
Mode
The mode is the value that appears most frequently. Unlike the mean and median, the mode works for both numerical and categorical data. If you survey favorite ice cream flavors, "chocolate" might be the mode. For numerical data like test scores, the mode is whichever score shows up most often.
A dataset can have no mode (all values appear equally), one mode, or multiple modes.
Distribution shapes based on modes:
- Unimodal: One clear peak. Data clusters around a single central value. Heights of adult women in a population, for instance, tend to form a single peak.
- Bimodal: Two distinct peaks. This often signals two subgroups mixed together. For example, if you measured the heights of both adult men and adult women in one dataset, you'd likely see two peaks because the groups have different average heights.
- Multimodal: More than two peaks. This suggests several distinct subgroups. Age distributions in a town with a college and a retirement community might show clusters around 20 and around 70.
When you see a bimodal or multimodal distribution, ask yourself why there are multiple peaks. It usually points to meaningful subgroups worth investigating separately.
Data Characteristics and Central Tendency
Choosing the right measure of center depends on the shape and features of your data:
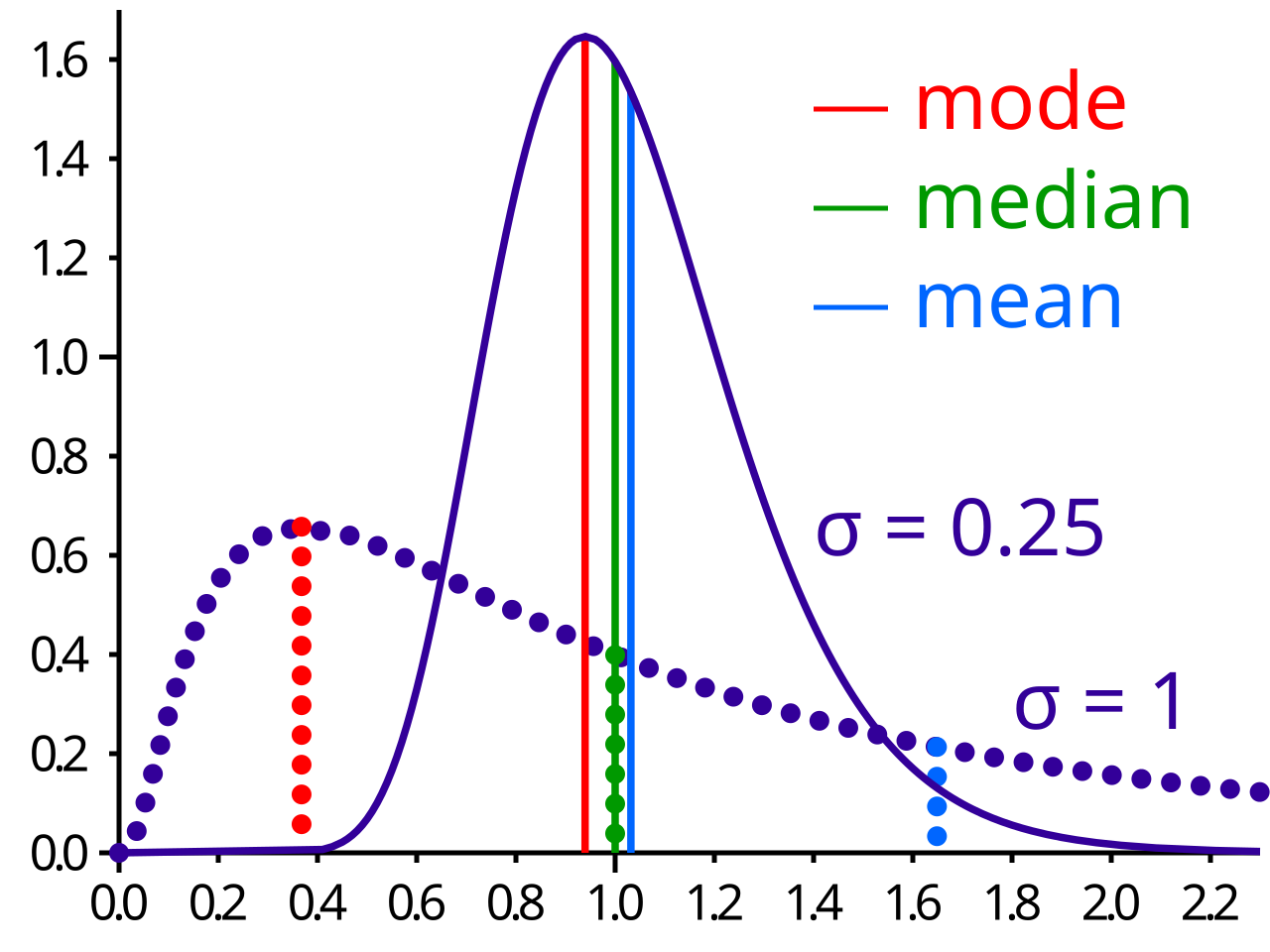
- Symmetry: In a perfectly symmetric distribution, the mean and median are equal. The more skewed the data, the more these two diverge. For right-skewed data, the mean gets pulled higher than the median; for left-skewed data, the mean gets pulled lower.
- Data clustering: If data groups tightly around one value, any measure of center works well. If data clusters around multiple values (bimodal/multimodal), reporting a single mean or median can be misleading.
- Dispersion: How spread out the data is affects how well any single number represents the dataset. Two datasets can have the same mean but very different spreads. Central tendency alone doesn't tell the whole story.
- Frequency distribution: A table or graph showing how often each value occurs. This is your starting point for identifying modes, spotting skewness, and deciding which measure of center to report.
Quick decision rule: If the data is symmetric with no outliers, use the mean. If the data is skewed or has outliers, use the median. Report the mode when you want to identify the most common value, especially with categorical data.