Test of Independence
The chi-square test of independence determines whether two categorical variables are related or if they vary independently of each other. It compares what you actually observe in your data to what you'd expect to see if the two variables had no relationship at all.

Construction of Contingency Tables
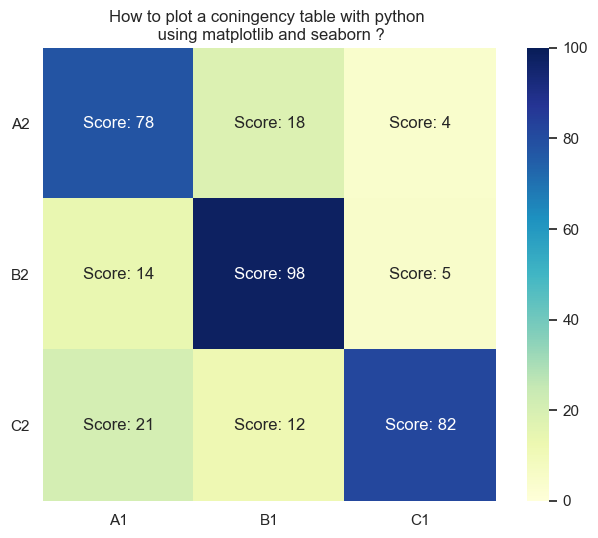
A contingency table (also called a two-way frequency table) organizes data for two categorical variables into rows and columns. Each cell shows the count of observations that fall into that particular combination of categories.
For example, suppose you survey 200 students about gender and preferred study method. Gender (male, female) forms the rows, and study method (alone, group, mixed) forms the columns. A cell might show that 45 females prefer studying in groups.
To build one:
- Identify your two categorical variables.
- List the categories (levels) for each variable along the rows and columns.
- Count how many observations fall into each row-column combination and fill in the cells.
- Add up each row and each column to get the marginal frequencies (the totals along the edges of the table).
- Sum all observations to get the grand total.
The marginal frequencies matter because they're used directly in calculating expected values during the test.
Calculation of the Chi-Square Test Statistic
The test statistic follows a chi-square distribution, which is right-skewed and defined by degrees of freedom equal to , where is the number of rows and is the number of columns.
Step 1: Compute expected frequencies. For each cell, the expected frequency assumes the two variables are independent. The formula is:
The logic here: if the variables are truly independent, the proportion in each cell should just reflect the product of its row and column proportions. You're asking, "If gender doesn't affect study preference at all, how many females should prefer group study based on the overall rates?"
Step 2: Calculate the test statistic.
- = observed frequency in row , column
- = expected frequency in row , column
You compute for every single cell, then add them all up. Squaring the difference ensures that positive and negative deviations don't cancel out, and dividing by scales each contribution relative to how large the expected count is.
A larger value means the observed data deviates more from what independence would predict, which points toward a relationship between the variables.
Determination of Factor Independence
This is where you put it all together into a formal hypothesis test.
- Null hypothesis (): The two categorical variables are independent (no association).
- Alternative hypothesis (): The two categorical variables are dependent (there is an association).
Steps to conduct the test:
- State and .
- Construct the contingency table and compute expected frequencies for every cell. (Check that all expected frequencies are at least 5; if not, the chi-square approximation may not be valid.)
- Calculate the test statistic using the formula above.
- Find degrees of freedom: . For a 2×3 table, that's .
- Choose a significance level (typically ).
- Compare your test statistic to the critical value from the chi-square table, or find the p-value.
Making the decision:
- If critical value (or p-value ): reject . You have evidence that the variables are associated. For instance, if your test statistic is 15.2 and the critical value at and is 7.815, you reject .
- If critical value (or p-value ): fail to reject . There isn't sufficient evidence of a relationship. A test statistic of 3.5 compared to a critical value of 7.815 means you fail to reject.
Keep in mind that larger sample sizes give the test more power to detect real associations. A small sample might miss a genuine relationship simply because there isn't enough data.
Additional Analysis
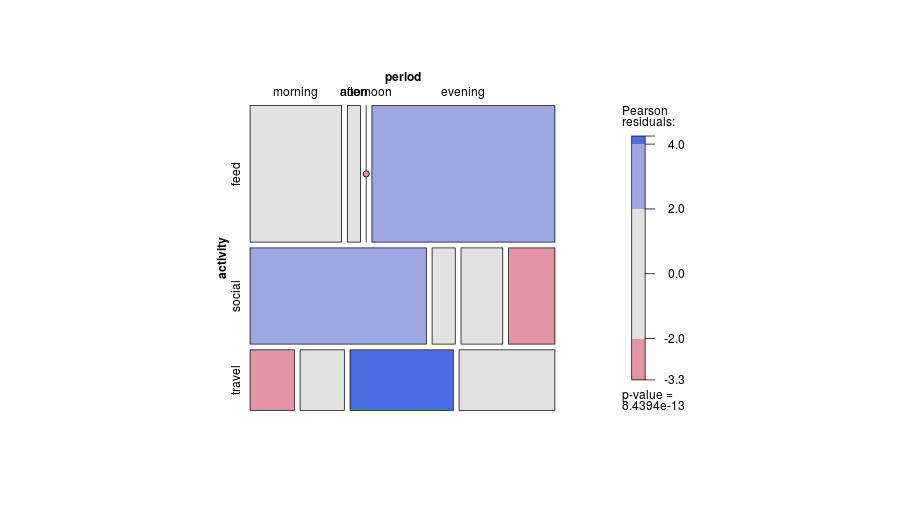
When you reject , the test tells you the variables are associated, but it doesn't tell you where the association is strongest. Standardized residuals help with this. For each cell, the standardized residual is:
Cells with standardized residuals greater than about 2 or less than about are the ones driving the significant result. This is useful for pinpointing which specific category combinations differ most from what independence would predict.