Empirical Bayes methods blend Bayesian and frequentist approaches in statistical inference. They use observed data to estimate prior distributions, bridging the gap between classical and Bayesian statistics. This approach is particularly useful for large-scale inference problems.
These methods offer a practical middle ground, combining the flexibility of Bayesian analysis with the data-driven nature of frequentist techniques. By estimating priors from data, Empirical Bayes provides a framework for borrowing strength across related groups or parameters, improving estimation in various fields.
Fundamentals of empirical Bayes
- Empirical Bayes methods combine Bayesian and frequentist approaches in statistical inference
- Utilizes data to estimate prior distributions, bridging the gap between classical and Bayesian statistics
- Plays a crucial role in modern Bayesian analysis, especially for large-scale inference problems
Definition and basic concepts
- Statistical approach uses observed data to estimate parameters of the prior distribution
- Treats hyperparameters of the prior distribution as unknown quantities to be estimated from the data
- Differs from fully Bayesian methods by not specifying a hyperprior on the hyperparameters
- Often applied in situations with multiple related parameters or groups of data
Historical development
- Originated in the 1950s with work by Herbert Robbins on compound decision problems
- Gained popularity in the 1960s and 1970s through contributions of researchers like Bradley Efron and Carl Morris
- Evolved alongside computational advancements, enabling more complex applications
- Influenced development of hierarchical Bayesian models and multilevel modeling techniques
Comparison with other Bayesian approaches
- Fully Bayesian approach specifies priors for all unknown parameters, including hyperparameters
- Empirical Bayes estimates hyperparameters from the data, potentially leading to more objective analysis
- Hierarchical Bayes serves as a middle ground, placing priors on hyperparameters
- Offers computational advantages over fully Bayesian methods, especially for large datasets
- May underestimate uncertainty compared to fully Bayesian approaches
Statistical foundations
- Empirical Bayes combines elements of frequentist and Bayesian statistical paradigms
- Builds upon the framework of Bayesian inference while incorporating data-driven parameter estimation
- Addresses challenges in specifying prior distributions, particularly in complex or high-dimensional problems
Frequentist vs Bayesian perspectives
- Frequentist approach treats parameters as fixed, unknown constants
- Bayesian perspective views parameters as random variables with associated probability distributions
- Empirical Bayes bridges these viewpoints by using data to inform prior distributions
- Retains Bayesian interpretation of results while leveraging frequentist techniques for parameter estimation
- Allows for more flexible modeling in situations where prior information may be limited or uncertain
Role of prior distributions
- Prior distributions represent initial beliefs or knowledge about parameters before observing data
- In empirical Bayes, priors are estimated from the data rather than specified in advance
- Commonly used priors include conjugate priors (beta-binomial, normal-normal)
- Choice of prior family can impact the efficiency and interpretability of the analysis
- Estimated priors serve as a form of regularization, helping to stabilize parameter estimates
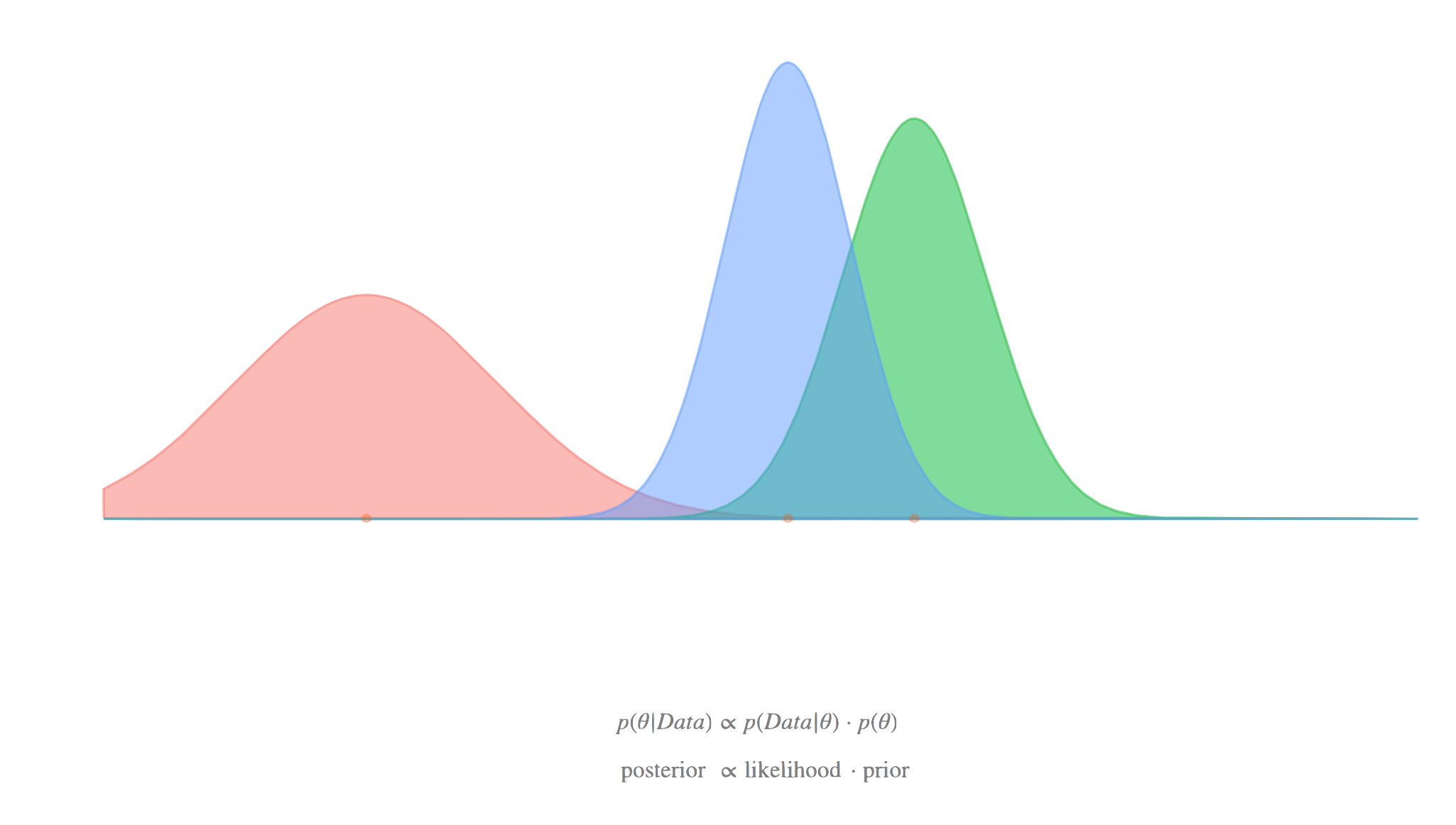
Likelihood and posterior distributions
- Likelihood function represents the probability of observing the data given the parameters
- Posterior distribution combines prior information with the likelihood using Bayes' theorem
- In empirical Bayes, the posterior is calculated using the estimated prior distribution
- Resulting posterior can be used for parameter estimation, hypothesis testing, and prediction
- Interpretation of empirical Bayes posteriors requires careful consideration of the estimation process
Empirical Bayes estimation
- Focuses on methods for estimating hyperparameters of the prior distribution from observed data
- Aims to balance the influence of prior information and observed data in the analysis
- Provides a framework for borrowing strength across related groups or parameters
Maximum likelihood estimation
- Estimates hyperparameters by maximizing the marginal likelihood of the observed data
- Involves integrating out the parameters of interest to obtain the marginal distribution
- Often requires numerical optimization techniques (Newton-Raphson, gradient descent)
- Produces point estimates of hyperparameters, which are then used to define the prior distribution
- Can be computationally intensive for complex models or large datasets
Method of moments
- Equates sample moments with theoretical moments to estimate hyperparameters
- Generally simpler to implement than maximum likelihood estimation
- May be less efficient than maximum likelihood in some cases
- Particularly useful for distributions with easily computed theoretical moments
- Can serve as a starting point for more sophisticated estimation procedures
Hierarchical Bayes connection
- Empirical Bayes can be viewed as an approximation to hierarchical Bayesian models
- Hierarchical models explicitly model the hyperparameter uncertainty
- Empirical Bayes fixes hyperparameters at their estimated values
- Can be extended to multi-level hierarchical structures
- Provides insights into the relationship between empirical Bayes and fully Bayesian approaches
Applications of empirical Bayes
- Empirical Bayes methods find use in various fields of statistics and data analysis
- Particularly valuable in situations involving multiple related parameters or groups
- Offers a balance between fully pooled and unpooled estimates
Small area estimation
- Applies to estimating parameters for subpopulations with limited sample sizes
- Borrows strength across areas to improve precision of estimates
- Used in survey sampling, epidemiology, and official statistics
- Combines direct estimates with model-based predictions
- Accounts for between-area variability while stabilizing within-area estimates
Shrinkage estimation
- Involves pulling individual estimates towards a common mean or target
- Reduces overall estimation error by trading off bias and variance
- James-Stein estimator serves as a classic example of shrinkage in action
- Particularly effective when dealing with many related parameters
- Degree of shrinkage depends on the estimated variability between groups
Multiple testing problems
- Addresses issues arising from simultaneous testing of many hypotheses
- Controls false discovery rate (FDR) or family-wise error rate (FWER)
- Estimates the proportion of true null hypotheses from the data
- Adaptive procedures adjust significance thresholds based on observed p-values
- Improves power compared to traditional multiple comparison corrections (Bonferroni)
Computational methods
- Empirical Bayes often requires sophisticated computational techniques for parameter estimation
- Advancements in computing power have expanded the range of applicable problems
- Focuses on efficient algorithms for handling large-scale data and complex models
EM algorithm
- Iterative method for finding maximum likelihood estimates in incomplete data problems
- Alternates between expectation (E) and maximization (M) steps
- Well-suited for mixture models and latent variable problems in empirical Bayes
- Guarantees increase in likelihood at each iteration, ensuring convergence
- May converge slowly for some problems, requiring acceleration techniques
Variational inference
- Approximates intractable posterior distributions using optimization techniques
- Transforms inference problem into an optimization problem
- Often faster than Markov chain Monte Carlo methods for large-scale problems
- Provides lower bounds on the marginal likelihood, useful for model comparison
- May underestimate posterior variance in some cases
Markov chain Monte Carlo
- Generates samples from the posterior distribution using stochastic simulation
- Includes methods like Metropolis-Hastings and Gibbs sampling
- Allows for flexible modeling and handles complex posterior distributions
- Computationally intensive but provides full posterior inference
- Requires careful assessment of convergence and mixing properties
Advantages and limitations
- Empirical Bayes offers a pragmatic approach to Bayesian inference in many situations
- Understanding its strengths and weaknesses is crucial for appropriate application
Efficiency and simplicity
- Often computationally more efficient than fully Bayesian methods
- Provides a natural way to pool information across related groups or parameters
- Simplifies prior specification by estimating hyperparameters from the data
- Can lead to improved estimation accuracy, especially for small sample sizes
- Facilitates implementation of Bayesian ideas in frequentist frameworks
Potential for bias
- May underestimate uncertainty by treating estimated hyperparameters as fixed
- Can lead to overly confident inferences, particularly for small datasets
- Sensitive to model misspecification, especially in the choice of prior family
- May produce inconsistent estimates in some situations (Neyman-Scott problem)
- Requires careful interpretation of results, considering the estimation process

Uncertainty quantification challenges
- Difficulty in accurately representing uncertainty in hyperparameter estimates
- Standard errors and confidence intervals may not fully capture all sources of variability
- Bootstrapping and other resampling methods can help assess estimation uncertainty
- Hybrid approaches combining empirical Bayes with fully Bayesian analysis exist
- Trade-off between computational simplicity and comprehensive uncertainty quantification
Case studies and examples
- Illustrative applications of empirical Bayes methods in various fields
- Demonstrates practical implementation and interpretation of results
James-Stein estimator
- Classic example of shrinkage estimation in multivariate normal setting
- Improves upon maximum likelihood estimation for three or more means
- Demonstrates paradoxical result of dominating individual estimators
- Connects to empirical Bayes through normal-normal hierarchical model
- Provides insights into the nature of shrinkage and bias-variance trade-off
Baseball batting averages
- Efron and Morris's famous application to estimating player batting averages
- Uses empirical Bayes to improve early-season predictions
- Demonstrates shrinkage of individual player estimates towards overall mean
- Illustrates how empirical Bayes can account for different sample sizes
- Serves as a prototypical example for sports analytics and player performance evaluation
Genomic data analysis
- Application to high-dimensional problems in genetics and molecular biology
- Used for estimating gene expression levels and identifying differentially expressed genes
- Handles multiple testing issues in genome-wide association studies
- Incorporates prior information on gene functions or pathways
- Demonstrates scalability of empirical Bayes methods to large datasets
Advanced topics
- Explores more sophisticated extensions and refinements of empirical Bayes methods
- Addresses limitations and expands applicability to broader classes of problems
Nonparametric empirical Bayes
- Relaxes assumptions about the form of the prior distribution
- Estimates the entire prior distribution from the data
- Includes methods like kernel density estimation and mixture models
- Provides greater flexibility in modeling complex data structures
- Requires careful consideration of identifiability and consistency issues
Empirical Bayes confidence intervals
- Constructs confidence intervals that account for hyperparameter estimation
- Addresses limitations of naive intervals based on estimated priors
- Includes methods like parametric bootstrapping and analytical approximations
- Aims to achieve proper frequentist coverage properties
- Balances Bayesian interpretation with frequentist guarantees
Robustness considerations
- Examines sensitivity of empirical Bayes methods to model misspecification
- Develops techniques for robust estimation of hyperparameters
- Includes methods like M-estimation and trimmed likelihood approaches
- Addresses issues of outliers and heavy-tailed distributions
- Explores trade-offs between efficiency and robustness in empirical Bayes inference
Empirical Bayes in practice
- Focuses on practical aspects of implementing empirical Bayes methods
- Provides guidance on software tools, implementation strategies, and result interpretation
Software tools and packages
- R packages (ebbr, EbayesThresh, limma) for various empirical Bayes applications
- Python libraries (statsmodels, PyMC3) supporting empirical Bayes analysis
- Specialized software for specific domains (INLA for spatial statistics)
- General-purpose Bayesian software (Stan, JAGS) adaptable for empirical Bayes
- Emphasizes importance of understanding underlying algorithms and assumptions
Implementation strategies
- Guidelines for choosing appropriate prior families and estimation methods
- Techniques for handling computational challenges in large-scale problems
- Strategies for model validation and diagnostics in empirical Bayes context
- Approaches for incorporating domain knowledge into the analysis
- Best practices for reproducibility and documentation of empirical Bayes analyses
Interpretation of results
- Framework for understanding empirical Bayes estimates in context of the problem
- Techniques for visualizing and communicating results to stakeholders
- Considerations for assessing practical significance of shrinkage effects
- Methods for comparing empirical Bayes results with alternative approaches
- Guidance on extrapolating findings and generalizing to new situations