Point estimation is a key concept in Bayesian statistics, providing single-value estimates for unknown population parameters. It bridges the gap between sample data and population characteristics, allowing us to make inferences about larger populations from limited data.
Various types of point estimators exist, each with unique properties like unbiasedness, consistency, and efficiency. Maximum likelihood estimation and Bayesian approaches offer powerful frameworks for parameter estimation, while methods of moments provide simpler alternatives in certain scenarios.
Concept of point estimation
- Point estimation forms a crucial component of Bayesian statistics, providing single-value estimates for unknown population parameters
- Bridges the gap between sample data and population characteristics, allowing inferences about larger populations from limited data
Definition and purpose
- Statistical method to calculate a single value (point estimate) that serves as a best guess for an unknown population parameter
- Aims to minimize the difference between the estimated value and the true parameter value
- Utilizes sample data to infer information about the entire population
- Provides a concise summary of the data for decision-making purposes
Types of point estimators
- Sample mean estimates population mean, offering an intuitive measure of central tendency
- Sample variance approximates population variance, quantifying data spread
- Sample proportion estimates population proportion for categorical data
- Maximum likelihood estimators maximize the likelihood function
- Method of moments estimators equate sample moments to population moments
Properties of estimators
- Unbiasedness measures the estimator's tendency to center around the true parameter value
- Consistency ensures the estimator converges to the true value as sample size increases
- Efficiency compares the variance of different estimators, with lower variance indicating higher efficiency
- Robustness evaluates an estimator's performance under deviations from assumed conditions
- Sufficiency determines whether an estimator captures all relevant information from the data
Maximum likelihood estimation
- Maximum likelihood estimation (MLE) serves as a cornerstone method in Bayesian statistics for parameter estimation
- Provides a framework to find parameter values that maximize the probability of observing the given data
Likelihood function
- Mathematical expression representing the probability of observing the data given specific parameter values
- Treats parameters as fixed and data as variable, contrary to probability functions
- Often expressed as the product of individual data point probabilities
- Typically transformed to log-likelihood for computational convenience
- Shapes the posterior distribution in Bayesian analysis when combined with prior information
MLE procedure
- Formulate the likelihood function based on the probability distribution of the data
- Take the logarithm of the likelihood function to simplify calculations
- Differentiate the log-likelihood with respect to the parameters of interest
- Set the derivatives equal to zero and solve for the parameters
- Verify that the solution maximizes (not minimizes) the likelihood function
- Use numerical methods (Newton-Raphson, gradient descent) for complex likelihood functions
Advantages and limitations
- Produces consistent and asymptotically efficient estimators under certain conditions
- Invariant to parameter transformations, allowing flexibility in parameterization
- May lead to biased estimates in small samples or with complex models
- Can be computationally intensive for high-dimensional parameter spaces
- Sensitive to outliers and model misspecification
- Requires specification of the full probability distribution of the data
Bayesian point estimation
- Integrates prior knowledge with observed data to produce posterior-based point estimates
- Provides a probabilistic framework for parameter estimation, accounting for uncertainty
Posterior distribution
- Represents the updated belief about parameter values after observing data
- Calculated using Bayes' theorem, combining prior distribution and likelihood function
- Serves as the foundation for Bayesian inference and decision-making
- Summarizes all available information about the parameters of interest
- Can be analytically derived for conjugate prior-likelihood pairs
- Often requires numerical methods (MCMC) for complex models
Bayesian estimators
- Posterior mean minimizes the expected squared error loss
- Posterior median minimizes the expected absolute error loss
- Posterior mode (MAP estimate) maximizes the posterior density
- Customized estimators can be derived based on specific loss functions
- Incorporate prior information to potentially improve estimation accuracy
- Allow for the inclusion of expert knowledge or historical data in the estimation process
MAP vs posterior mean
- Maximum a posteriori (MAP) estimate corresponds to the mode of the posterior distribution
- Posterior mean represents the expected value of the parameter given the posterior distribution
- MAP often easier to compute, especially for high-dimensional problems
- Posterior mean accounts for the entire posterior distribution, not just its peak
- MAP can be viewed as a regularized version of maximum likelihood estimation
- Choice between MAP and posterior mean depends on the specific problem and loss function
Methods of moments
- Provides an alternative approach to parameter estimation in Bayesian statistics
- Relies on equating sample moments to theoretical population moments
Principle of moments
- Equates sample moments (mean, variance, etc.) to their theoretical counterparts
- Solves resulting equations to obtain parameter estimates
- Utilizes increasingly higher-order moments for more complex distributions
- Provides a computationally simple method for initial parameter estimation
- Can be used to derive starting values for more sophisticated estimation procedures
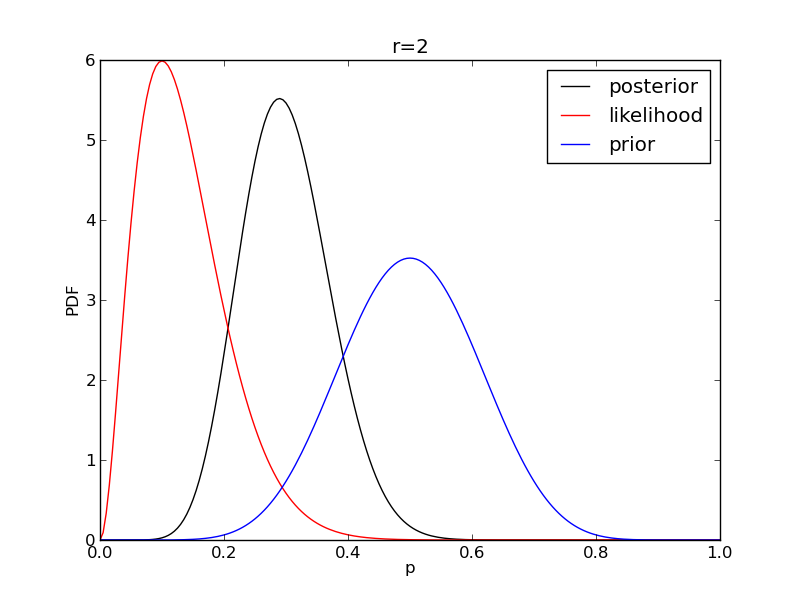
Comparison with MLE
- Generally easier to compute than MLE, especially for complex distributions
- Often less efficient than MLE, particularly for large sample sizes
- May produce estimates outside the parameter space in some cases
- Doesn't require specification of the full probability distribution
- Can be useful when the likelihood function is difficult to formulate or maximize
- Serves as a foundation for generalized method of moments (GMM) in econometrics
Limitations and applications
- May produce biased or inconsistent estimates for some distributions
- Efficiency decreases with higher-order moments due to increased sampling variability
- Sensitive to outliers, especially when using higher-order moments
- Useful for obtaining initial estimates in iterative procedures (EM algorithm)
- Applied in method of simulated moments for complex economic models
- Provides a simple approach for estimating parameters of mixture distributions
Bias and consistency
- Critical concepts in evaluating the quality and reliability of point estimators in Bayesian statistics
- Influence the choice of estimators and interpretation of results in statistical analyses
Bias in point estimation
- Measures the systematic deviation of an estimator from the true parameter value
- Calculated as the difference between the expected value of the estimator and the true parameter
- Positive bias indicates overestimation, negative bias suggests underestimation
- Unbiased estimators have an expected value equal to the true parameter
- Bias can arise from model misspecification, small sample sizes, or inherent properties of the estimator
- Some biased estimators (shrinkage estimators) can outperform unbiased ones in terms of mean squared error
Consistency of estimators
- Describes the convergence of an estimator to the true parameter value as sample size increases
- Weak consistency implies convergence in probability
- Strong consistency requires almost sure convergence
- Consistent estimators become arbitrarily close to the true value with sufficiently large samples
- Ensures that the estimator "learns" from data and improves with more information
- Crucial property for reliable inference in large-sample scenarios
Bias-variance tradeoff
- Balances the competing goals of minimizing bias and reducing variance in estimation
- Total error decomposed into bias squared plus variance
- Unbiased estimators may have high variance, leading to poor overall performance
- Slightly biased estimators with lower variance can yield lower mean squared error
- Regularization techniques (ridge regression, lasso) exploit this tradeoff
- Impacts model complexity decisions in machine learning and statistical modeling
Efficiency and sufficiency
- Key concepts in statistical estimation theory, particularly relevant in Bayesian analysis
- Guide the selection and evaluation of estimators based on their information utilization
Fisher information
- Measures the amount of information a sample provides about an unknown parameter
- Calculated as the negative expected value of the second derivative of the log-likelihood
- Represents the curvature of the log-likelihood function at its maximum
- Inversely related to the variance of efficient estimators
- Plays a crucial role in determining the Cramér-Rao lower bound
- Used in experimental design to maximize information gain
Cramér-Rao lower bound
- Establishes a lower bound on the variance of unbiased estimators
- Calculated as the inverse of the Fisher information
- Provides a benchmark for assessing estimator efficiency
- Estimators achieving this bound are considered fully efficient
- Applies to both frequentist and Bayesian estimation frameworks
- Generalized versions exist for biased estimators and multiparameter scenarios
Sufficient statistics
- Contain all relevant information in the data for estimating a parameter
- Allow for data reduction without loss of information
- Enable construction of minimum variance unbiased estimators (MVUE)
- Play a key role in the factorization theorem and exponential family distributions
- Facilitate conjugate prior selection in Bayesian analysis
- Examples include sample mean for normal distribution mean, sample size and success count for binomial proportion
Robust estimation
- Focuses on developing estimators that perform well under various conditions in Bayesian statistics
- Aims to mitigate the impact of outliers and model misspecification on parameter estimates
Outliers and influential points
- Observations that deviate significantly from the overall pattern of the data
- Can severely impact traditional estimators like sample mean or ordinary least squares
- Identified through various techniques (Cook's distance, leverage, studentized residuals)
- May represent genuine extreme values or result from measurement errors
- Require careful treatment to balance information retention and estimation stability
- Influence the choice between classical and robust estimation methods
M-estimators
- Generalize maximum likelihood estimation to provide robust alternatives
- Minimize a chosen function of the residuals instead of squared residuals
- Include Huber's estimator, which combines L1 and L2 loss functions
- Tukey's biweight function offers another popular choice for robust regression
- Provide a compromise between efficiency and robustness
- Allow for customization of the influence function to control the impact of outliers

Robust vs classical estimators
- Robust estimators sacrifice some efficiency under ideal conditions for better performance with outliers
- Classical estimators (OLS, MLE) often optimal under strict distributional assumptions
- Median absolute deviation (MAD) provides a robust alternative to standard deviation
- Trimmed means offer a simple robust approach to estimating central tendency
- Robust methods particularly useful in exploratory data analysis and model diagnostics
- Choice between robust and classical methods depends on data quality and analysis goals
Asymptotic properties
- Describe the behavior of estimators as sample size approaches infinity in Bayesian statistics
- Provide theoretical justification for the use of certain estimators in large-sample scenarios
Large sample behavior
- Focuses on the convergence of estimators to true parameter values
- Allows for approximations that simplify inference in complex models
- Justifies the use of asymptotic distributions for hypothesis testing and interval estimation
- Enables the derivation of asymptotic standard errors for complicated estimators
- Supports the use of bootstrap methods for inference in large samples
- Guides the development of more efficient computational algorithms for big data analysis
Asymptotic normality
- Many estimators converge in distribution to a normal distribution as sample size increases
- Enables the use of z-tests and t-tests for large-sample inference
- Facilitates the construction of approximate confidence intervals
- Holds for a wide range of estimators under certain regularity conditions
- Central Limit Theorem provides the theoretical foundation for this property
- Allows for the use of normal approximations in Bayesian posterior analysis
Consistency in large samples
- Ensures that estimators converge to the true parameter value as sample size grows
- Weak consistency implies convergence in probability
- Strong consistency requires almost sure convergence
- Provides a minimal requirement for estimators to be useful in large samples
- Allows for the combination of consistent estimators to form new consistent estimators
- Supports the use of plug-in estimators for complex functions of parameters
Interval estimation vs point estimation
- Contrasts two fundamental approaches to parameter estimation in Bayesian statistics
- Highlights the importance of quantifying uncertainty in statistical inference
Confidence intervals
- Provide a range of plausible values for the parameter with a specified confidence level
- Constructed using the sampling distribution of the point estimator
- Interpretation based on repeated sampling: X% of intervals would contain the true parameter
- Width of the interval reflects the precision of the estimate
- Affected by sample size, variability in the data, and chosen confidence level
- Examples include t-intervals for means and Wilson score intervals for proportions
Credible intervals
- Bayesian alternative to confidence intervals, representing a range of probable parameter values
- Derived from the posterior distribution of the parameter
- Direct probabilistic interpretation: X% probability the parameter lies within the interval
- Can be constructed as highest posterior density (HPD) or equal-tailed intervals
- Incorporate prior information, potentially leading to narrower intervals than confidence intervals
- Allow for asymmetric intervals that better reflect the shape of the posterior distribution
Precision and uncertainty
- Interval estimates quantify the uncertainty associated with point estimates
- Narrower intervals indicate higher precision and more reliable estimates
- Wider intervals suggest greater uncertainty, often due to small sample sizes or high variability
- Precision can be improved by increasing sample size or reducing measurement error
- Uncertainty visualization crucial for informed decision-making in statistical analyses
- Bayesian methods provide a natural framework for propagating uncertainty through complex models
Applications in Bayesian analysis
- Demonstrates the practical implementation of point estimation concepts in Bayesian statistical frameworks
- Illustrates how Bayesian principles enhance and modify traditional estimation approaches
Prior selection impact
- Choice of prior distribution significantly influences posterior estimates and credible intervals
- Informative priors incorporate existing knowledge but may bias results if chosen incorrectly
- Non-informative priors attempt to minimize impact on posterior, often used in absence of prior knowledge
- Conjugate priors simplify posterior calculations but may not always represent true prior beliefs
- Hierarchical priors allow for borrowing strength across related parameters or groups
- Sensitivity analysis assesses the robustness of results to different prior specifications
Posterior point estimates
- Derived from the full posterior distribution, incorporating both prior information and data
- Posterior mean minimizes expected squared error loss
- Posterior median provides a robust estimate, minimizing absolute error loss
- Maximum a posteriori (MAP) estimate maximizes the posterior density
- Choice of point estimate depends on the specific loss function and decision problem
- Often accompanied by credible intervals to quantify uncertainty
Decision theory perspective
- Frames point estimation as a decision problem with associated loss functions
- Bayesian estimators minimize expected posterior loss
- Allows for custom loss functions tailored to specific application needs
- Incorporates the costs of over- and under-estimation in the estimation process
- Provides a formal framework for choosing between competing estimators
- Extends naturally to more complex decision problems beyond simple parameter estimation