Probability distributions are the backbone of Bayesian statistics, providing a mathematical framework for modeling uncertainty in data. They represent both prior beliefs and updated knowledge based on evidence, allowing us to quantify and reason about uncertainty in a systematic way.
Understanding different types of distributions, their properties, and how to work with them is crucial for effective Bayesian analysis. From discrete to continuous, univariate to multivariate, these distributions form the building blocks for complex statistical models and inference techniques.
Fundamentals of probability distributions
- Probability distributions form the foundation of Bayesian statistics, providing a mathematical framework for modeling uncertainty and variability in data
- In Bayesian analysis, probability distributions represent both prior beliefs and updated knowledge based on observed evidence
Concept of random variables
- Random variables represent quantities with outcomes determined by chance or uncertainty
- Discrete random variables take on countable values (coin flips, number of customers)
- Continuous random variables can take any value within a range (height, temperature)
- Probability distributions describe the likelihood of different outcomes for random variables
Probability mass vs density functions
- Probability mass functions (PMFs) apply to discrete random variables
- PMFs assign probabilities to specific values, summing to 1 across all possible outcomes
- Probability density functions (PDFs) describe continuous random variables
- PDFs represent relative likelihood, with area under the curve equaling 1
- Interpret PDF values as probability densities, not direct probabilities
Cumulative distribution functions
- Cumulative distribution functions (CDFs) apply to both discrete and continuous random variables
- CDFs represent the probability of a random variable being less than or equal to a given value
- For discrete variables, CDF is a step function
- For continuous variables, CDF is a smooth, non-decreasing function
- CDFs range from 0 to 1 and approach these limits as x approaches negative and positive infinity
Types of probability distributions
- Probability distributions in Bayesian statistics model both prior beliefs and likelihood functions
- Understanding different types of distributions helps in selecting appropriate models for various scenarios
Discrete vs continuous distributions
- Discrete distributions model random variables with countable outcomes
- Probability mass functions describe discrete distributions (binomial, Poisson)
- Continuous distributions model random variables with uncountable outcomes
- Probability density functions describe continuous distributions (normal, exponential)
- Some distributions (gamma) can be discrete or continuous depending on parameters
Univariate vs multivariate distributions
- Univariate distributions describe a single random variable
- Univariate distributions represented by single-variable functions (normal distribution)
- Multivariate distributions model multiple random variables simultaneously
- Joint probability distributions describe relationships between variables
- Covariance and correlation capture dependencies in multivariate distributions
Parametric vs nonparametric distributions
- Parametric distributions defined by a fixed number of parameters
- Common parametric distributions include normal (mean, variance) and exponential (rate)
- Nonparametric distributions not constrained by fixed parameter set
- Kernel density estimation creates flexible, data-driven distributions
- Bayesian nonparametric methods (Dirichlet process) allow infinite-dimensional parameter spaces
Common discrete distributions
- Discrete distributions play a crucial role in Bayesian analysis for modeling countable outcomes
- These distributions often serve as likelihood functions or priors in discrete data scenarios
Bernoulli distribution
- Models binary outcomes with probability of success p and failure 1-p
- Probability mass function: for x = 0 or 1
- Mean: , Variance:
- Used in Bayesian inference for binary classification problems
Binomial distribution
- Extends Bernoulli to n independent trials with probability of success p
- Probability mass function: for k = 0, 1, ..., n
- Mean: , Variance:
- Applied in Bayesian analysis of proportions and count data
Poisson distribution
- Models number of events in fixed time or space interval
- Probability mass function: for k = 0, 1, 2, ...
- Mean and variance both equal to rate parameter λ
- Used in Bayesian modeling of rare events and time series data
Geometric distribution
- Models number of trials until first success in Bernoulli trials
- Probability mass function: for k = 1, 2, 3, ...
- Mean: , Variance:
- Applied in Bayesian survival analysis and reliability studies
Common continuous distributions
- Continuous distributions are essential in Bayesian statistics for modeling real-valued data
- These distributions often serve as priors or likelihood functions in continuous data scenarios
Uniform distribution
- Models equal probability over a finite interval [a, b]
- Probability density function: for a ≤ x ≤ b
- Mean: , Variance:
- Often used as noninformative prior in Bayesian inference
Normal distribution
- Bell-shaped distribution defined by mean μ and standard deviation σ
- Probability density function:
- Central Limit Theorem justifies its widespread use in Bayesian modeling
- Conjugate prior for normal likelihood with known variance
Exponential distribution
- Models time between events in Poisson process
- Probability density function: for x ≥ 0
- Mean: , Variance:
- Memoryless property:
Gamma distribution
- Generalizes exponential distribution with shape α and rate β parameters
- Probability density function: for x > 0
- Mean: , Variance:
- Conjugate prior for Poisson and exponential likelihoods
Properties of distributions
- Understanding distribution properties is crucial for effective Bayesian modeling and inference
- These properties help in selecting appropriate priors and interpreting posterior distributions
Moments of distributions
- Moments characterize the shape and behavior of probability distributions
- First moment (mean) represents central tendency
- Second moment relates to spread and variability
- Higher moments describe skewness, kurtosis, and other shape characteristics
- Moment-generating functions uniquely determine probability distributions
Expectation and variance
- Expectation (E[X]) represents average or central value of a distribution
- For discrete distributions:
- For continuous distributions:
- Variance (Var(X)) measures spread or dispersion around the mean
- Calculated as
Skewness and kurtosis
- Skewness measures asymmetry of probability distribution
- Positive skew: right tail longer than left (income distributions)
- Negative skew: left tail longer than right (exam scores)
- Kurtosis quantifies tailedness or peakedness of distribution
- Higher kurtosis indicates heavier tails and sharper peak
- Normal distribution has kurtosis of 3 (mesokurtic)
Multivariate distributions
- Multivariate distributions model relationships between multiple random variables
- Essential for Bayesian analysis of complex systems and high-dimensional data
Joint probability distributions
- Describe simultaneous behavior of multiple random variables
- For discrete variables: gives joint probability
- For continuous variables: represents joint density function
- Correlation and covariance capture linear relationships between variables
- Copulas model complex dependencies in multivariate distributions
Marginal distributions
- Obtained by integrating or summing joint distribution over other variables
- For discrete variables:
- For continuous variables:
- Marginal distributions discard information about relationships between variables
- Used to analyze individual variables in multivariate settings
Conditional distributions
- Describe distribution of one variable given known values of others
- For discrete variables:
- For continuous variables:
- Bayes' theorem relates conditional and marginal distributions
- Crucial in Bayesian inference for updating beliefs given observed data
Transformations of random variables
- Transformations allow manipulation of random variables to create new distributions
- Understanding transformations is essential for deriving sampling distributions and posterior calculations

Linear transformations
- Involve scaling and shifting random variables: Y = aX + b
- Preserve shape of distribution but affect location and scale
- Mean transforms as
- Variance transforms as
- Useful for standardizing variables and creating z-scores
Non-linear transformations
- Involve applying non-linear functions to random variables: Y = g(X)
- Can significantly alter shape and properties of original distribution
- Jacobian determinant required for transforming probability density functions
- Moment-generating functions useful for deriving properties of transformed variables
- Log-normal distribution arises from exponentiating normally distributed variable
Convolution of distributions
- Describes sum of independent random variables
- For discrete variables:
- For continuous variables:
- Convolution theorem simplifies calculations using Fourier transforms
- Central Limit Theorem results from repeated convolutions
Bayesian perspective on distributions
- Bayesian statistics treats parameters as random variables with associated distributions
- This approach allows incorporation of prior knowledge and quantification of parameter uncertainty
Prior distributions
- Represent initial beliefs about parameters before observing data
- Can be informative (based on previous studies) or noninformative (uniform, Jeffreys prior)
- Conjugate priors simplify posterior calculations for certain likelihood functions
- Hierarchical priors model parameter dependencies in complex models
- Elicitation techniques help experts quantify prior beliefs
Likelihood functions
- Describe probability of observed data given model parameters
- Not a probability distribution over parameters, but function of parameters given fixed data
- For independent observations:
- Maximum likelihood estimation finds parameters maximizing likelihood
- In Bayesian inference, likelihood combines with prior to form posterior
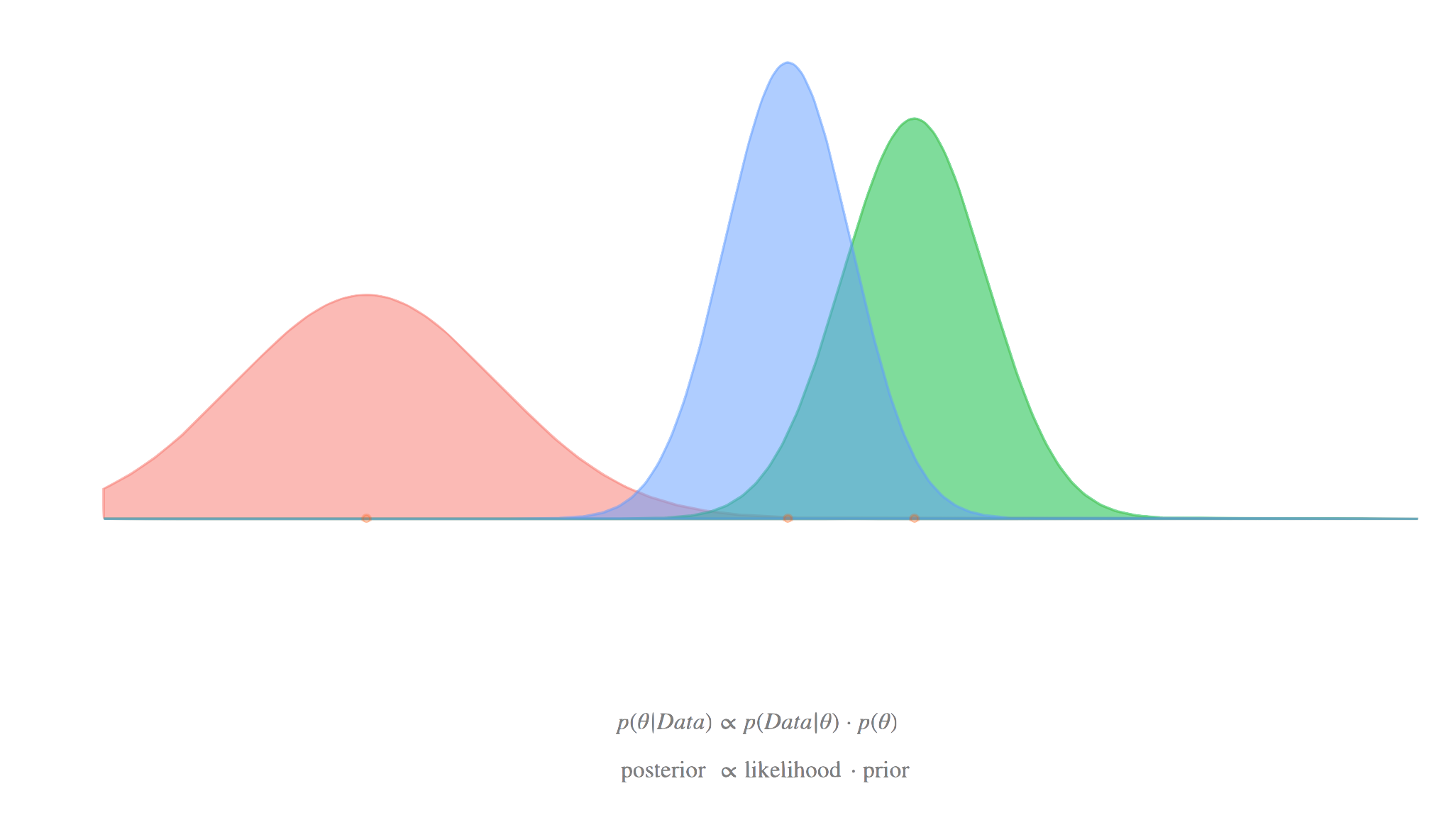
Posterior distributions
- Represent updated beliefs about parameters after observing data
- Calculated using Bayes' theorem:
- Often analytically intractable, requiring numerical approximation methods
- Summarized using point estimates (MAP, posterior mean) and credible intervals
- Posterior predictive distributions used for model checking and prediction
Sampling from distributions
- Sampling techniques are crucial for Bayesian computation and Monte Carlo methods
- These methods allow generation of random variables from complex distributions
Inverse transform sampling
- Generates samples from any distribution with known cumulative distribution function (CDF)
- Steps: generate U ~ Uniform(0,1), compute X = F^(-1)(U) where F is the CDF
- Works well for distributions with analytically invertible CDFs (exponential, Cauchy)
- Efficient for univariate distributions but challenging for multivariate cases
- Forms basis for more advanced sampling methods (copula sampling)
Rejection sampling
- Generates samples from target distribution using proposal distribution
- Steps: sample from proposal, accept/reject based on ratio of target to proposal densities
- Requires knowledge of upper bound on ratio of target to proposal densities
- Efficiency depends on similarity between target and proposal distributions
- Useful for sampling from distributions with complex shapes or truncated domains
Importance sampling
- Estimates properties of target distribution using samples from proposal distribution
- Assigns weights to samples based on ratio of target to proposal densities
- Effective for estimating expectations and normalizing constants
- Self-normalized importance sampling corrects for unknown normalizing constants
- Forms basis for particle filtering methods in sequential Monte Carlo
Applications in Bayesian inference
- Probability distributions play central role in Bayesian modeling and inference
- Understanding distribution properties and relationships is crucial for effective Bayesian analysis
Conjugate priors
- Prior distributions that yield posterior distributions in same family as prior
- Simplify posterior calculations and enable closed-form solutions
- Beta prior conjugate to binomial likelihood for inference on proportions
- Normal-Inverse-Gamma prior conjugate to normal likelihood for unknown mean and variance
- Trade-off between computational convenience and flexibility in prior specification
Hierarchical models
- Model parameters as drawn from higher-level distributions
- Allow sharing of information across groups or subpopulations
- Hyperparameters control overall behavior of lower-level parameters
- Often implemented using normal or Student's t distributions for shrinkage
- Facilitate partial pooling between complete pooling and no pooling extremes
Mixture models
- Represent complex distributions as weighted sum of simpler component distributions
- Gaussian mixture models use weighted sum of normal distributions
- Dirichlet process mixtures allow infinite number of components
- Useful for clustering, density estimation, and modeling heterogeneous populations
- Expectation-Maximization (EM) algorithm commonly used for fitting mixture models