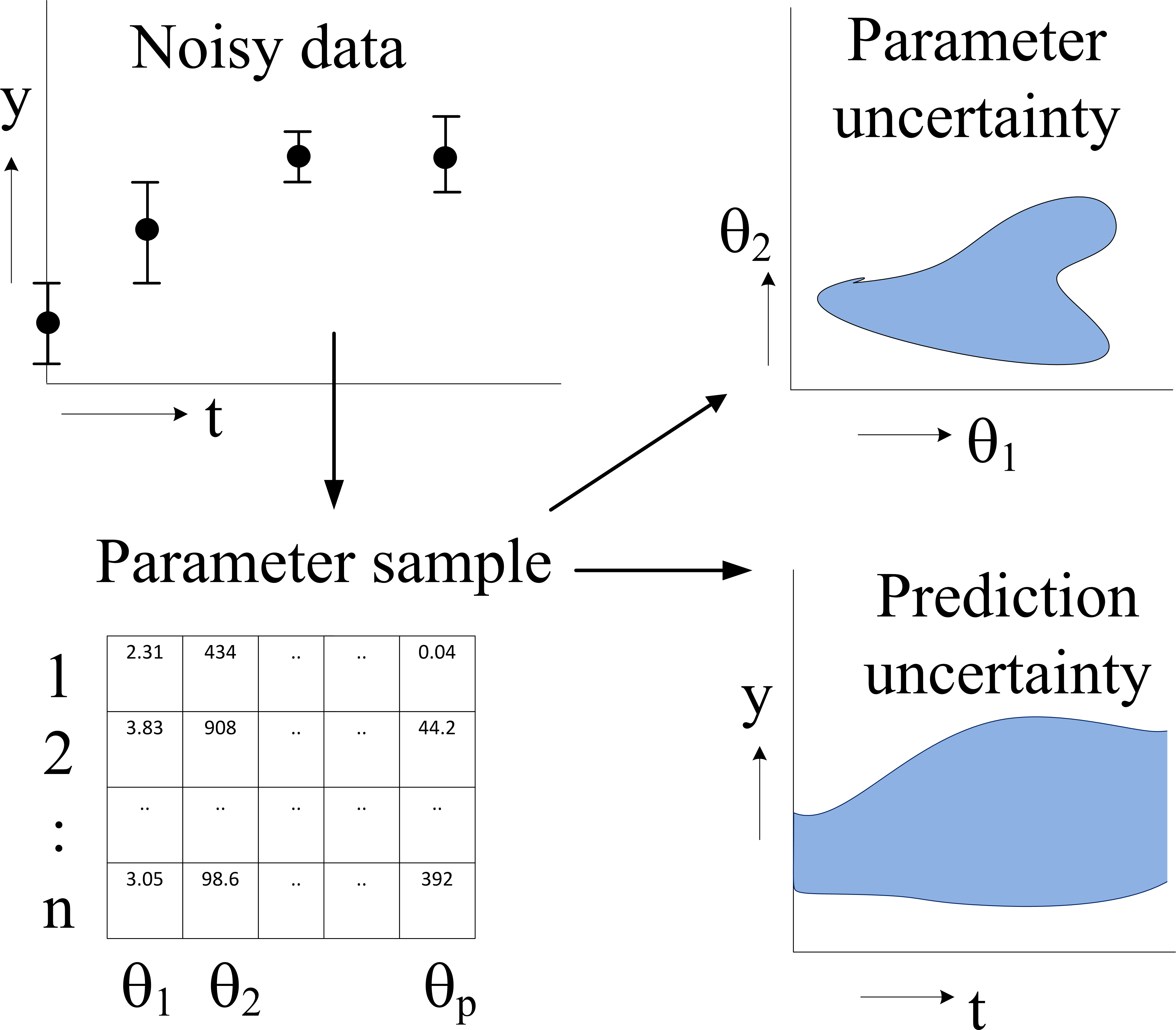
Stan is a powerful tool for Bayesian statistical modeling and inference. It provides a high-level language for specifying complex models and automates posterior distribution computations using advanced sampling algorithms.
Stan's key features include state-of-the-art MCMC methods, automatic differentiation, and built-in diagnostics. It supports a wide range of analyses, from simple regressions to complex hierarchical models, making it versatile for various research fields.
Introduction to Stan
- Stan provides a powerful framework for Bayesian statistical modeling and inference, enabling complex probabilistic computations
- Integrates seamlessly with popular programming languages like R and Python, facilitating adoption in diverse research fields
Stan's role in Bayesian analysis
- Enables specification of complex statistical models using a high-level probabilistic programming language
- Automates the process of deriving posterior distributions through advanced sampling algorithms
- Facilitates efficient parameter estimation and uncertainty quantification in Bayesian models
- Supports a wide range of statistical analyses, from simple linear regressions to complex hierarchical models
Key features of Stan
- Implements state-of-the-art Markov Chain Monte Carlo (MCMC) methods for posterior sampling
- Offers automatic differentiation for efficient gradient-based sampling and optimization
- Provides built-in diagnostics and visualization tools for model checking and validation
- Supports vectorized operations for improved computational efficiency
- Allows for easy extension and customization of statistical models
Stan programming language
- Stan's domain-specific language designed specifically for statistical modeling and Bayesian inference
- Combines elements of probabilistic programming with traditional imperative programming constructs
Syntax basics
- Uses a C-like syntax with semicolons ending statements and curly braces defining blocks
- Employs strong typing system to ensure type safety and catch errors at compile-time
- Supports both forward and reverse-mode automatic differentiation for efficient gradient computations
- Utilizes a block structure to organize different components of a statistical model (data, parameters, model)
Variable declarations
- Requires explicit type declarations for all variables used in the model
- Supports scalar types (
int,real), vector types (vector,row_vector), and matrix types - Allows for constrained variable declarations (lower and upper bounds)
- Enables declaration of local variables within code blocks for improved readability and organization
Model specification
- Utilizes a probabilistic programming paradigm to define statistical models
- Separates model specification into distinct blocks:
data,parameters,transformed parameters, andmodel - Supports both sampling statements and target increments for defining likelihood and prior distributions
- Allows for flexible model construction through user-defined functions and control structures
Probabilistic programming in Stan
- Stan implements a probabilistic programming paradigm, allowing direct specification of statistical models
- Enables seamless integration of prior knowledge and observed data in Bayesian analyses
Prior distributions
- Supports a wide range of built-in probability distributions for specifying prior beliefs
- Allows for hierarchical prior specifications to model complex dependencies between parameters
- Enables the use of informative, weakly informative, and non-informative priors
- Facilitates sensitivity analyses through easy modification of prior distributions
Likelihood functions
- Supports specification of various likelihood functions for different data types and distributions
- Allows for custom likelihood functions through user-defined probability functions
- Enables efficient computation of log-likelihood values for improved numerical stability
- Supports vectorized operations for handling large datasets and improving computational efficiency
Posterior inference
- Automates the process of deriving posterior distributions through MCMC sampling
- Provides various summary statistics and diagnostics for posterior analysis
- Supports generation of posterior predictive samples for model checking and validation
- Enables computation of derived quantities based on posterior samples
Stan's sampling algorithms
- Stan implements advanced MCMC algorithms for efficient posterior sampling
- Offers automatic tuning of sampling parameters for improved performance
Hamiltonian Monte Carlo
- Utilizes Hamiltonian dynamics to propose new states in the Markov chain
- Exploits gradient information to efficiently explore high-dimensional parameter spaces
- Reduces autocorrelation between samples compared to traditional Metropolis-Hastings algorithms
- Requires specification of step size and number of steps for the leapfrog integrator
No-U-Turn Sampler (NUTS)
- Extends Hamiltonian Monte Carlo with adaptive tuning of the number of leapfrog steps
- Automatically selects an appropriate trajectory length to avoid doubling back (hence "No-U-Turn")
- Improves sampling efficiency by adapting to the geometry of the posterior distribution
- Reduces the need for manual tuning of sampling parameters
Data types and structures
- Stan provides a rich set of data types and structures for flexible model specification
- Supports both built-in types and user-defined types for complex data representations
Scalar types
- Includes
intfor integer values andrealfor floating-point numbers - Supports constrained versions of scalar types (lower and upper bounds)
- Allows for efficient vectorized operations on scalar types
- Provides automatic type promotion and conversion in arithmetic operations
Vector and matrix types
- Supports
vectorfor column vectors androw_vectorfor row vectors - Includes
matrixtype for two-dimensional arrays of real numbers - Allows for efficient linear algebra operations on vector and matrix types
- Supports slicing and indexing for easy manipulation of vector and matrix elements
User-defined types
- Enables creation of custom data structures using the
structkeyword - Allows for grouping related variables into a single entity for improved code organization
- Supports nested structures for representing complex hierarchical data
- Facilitates creation of reusable components in Stan programs
Control structures in Stan
- Stan provides various control structures for flexible model specification and computation
- Enables implementation of complex algorithms and custom probability distributions
Loops and conditionals
- Supports
forloops for iterating over ranges or arrays - Includes
whileloops for conditional iteration - Provides
if-elsestatements for conditional execution of code blocks - Allows for nested control structures for complex logic implementation
Functions and subroutines
- Enables definition of user-defined functions for code reuse and modularity
- Supports both void functions (subroutines) and return-value functions
- Allows for recursive function calls with appropriate constraints
- Provides built-in mathematical and statistical functions for common operations
Model diagnostics and evaluation
- Stan offers various tools and techniques for assessing model fit and convergence
- Enables comprehensive model evaluation and refinement
Convergence diagnostics
- Implements the Gelman-Rubin statistic (R-hat) for assessing chain convergence
- Provides effective sample size (ESS) calculations to evaluate sampling efficiency
- Offers trace plots and autocorrelation plots for visual inspection of chain behavior
- Includes divergence diagnostics to identify potential issues with the posterior geometry
Posterior predictive checks
- Supports generation of posterior predictive samples for model validation
- Enables comparison of observed data with replicated data from the posterior predictive distribution
- Facilitates calculation of various discrepancy measures for assessing model fit
- Allows for visualization of posterior predictive distributions for intuitive model evaluation
Stan interfaces
- Stan provides multiple interfaces for different programming environments and use cases
- Enables integration with popular data analysis and visualization tools
RStan vs PyStan
- RStan offers a native R interface for Stan, integrating with R's data structures and functions
- PyStan provides a Python interface, allowing use of Stan models within Python environments
- Both interfaces support similar functionality but differ in syntax and ecosystem integration
- RStan leverages R's statistical capabilities, while PyStan benefits from Python's scientific computing libraries
CmdStan overview
- Provides a command-line interface for running Stan models
- Offers maximum flexibility and control over Stan's compilation and execution
- Supports integration with various build systems and continuous integration pipelines
- Enables easy automation of Stan model fitting and analysis processes
Optimization in Stan
- Stan supports various optimization techniques for point estimation and approximate inference
- Enables efficient parameter estimation for large-scale models and datasets
Maximum likelihood estimation
- Implements optimization algorithms for finding maximum likelihood estimates
- Supports various optimization methods (L-BFGS, BFGS, Newton)
- Allows for constrained optimization through variable transformations
- Provides diagnostics and convergence checks for optimization procedures
Variational inference
- Offers variational inference as an alternative to full MCMC sampling
- Implements automatic differentiation variational inference (ADVI) for efficient approximate posterior inference
- Supports both mean-field and full-rank variational approximations
- Enables faster inference for large-scale models where MCMC may be computationally prohibitive
Advanced Stan techniques
- Stan provides advanced features for handling complex modeling scenarios
- Enables sophisticated statistical analyses and model specifications
Hierarchical models
- Supports specification of multi-level or hierarchical models
- Allows for partial pooling of information across groups or clusters
- Enables efficient parameterization of hierarchical models for improved sampling
- Facilitates analysis of nested data structures and repeated measures designs
Missing data handling
- Provides mechanisms for modeling missing data within the Bayesian framework
- Supports multiple imputation techniques for handling missing values
- Allows for specification of missing data mechanisms (MCAR, MAR, MNAR)
- Enables joint modeling of observed and missing data for improved inference
Stan best practices
- Stan community has developed a set of best practices for efficient and reliable model implementation
- Adhering to these practices can improve model performance and interpretability
Efficient coding strategies
- Encourages vectorization of operations for improved computational efficiency
- Recommends appropriate parameterization to improve sampling efficiency
- Suggests using transformed parameters for derived quantities to reduce redundant computations
- Advises on effective use of constraints and variable transformations
Common pitfalls and solutions
- Addresses issues related to model identifiability and parameter degeneracy
- Provides strategies for dealing with divergent transitions in MCMC sampling
- Offers solutions for improving numerical stability in complex models
- Discusses best practices for prior specification and sensitivity analysis
Stan vs other Bayesian software
- Comparison of Stan with other popular Bayesian modeling tools
- Highlights strengths and limitations of different approaches
Stan vs BUGS/JAGS
- Stan offers more flexible model specification compared to BUGS/JAGS
- Implements more advanced MCMC algorithms (HMC, NUTS) than Gibbs sampling used in BUGS/JAGS
- Provides better support for continuous parameters and non-conjugate models
- Offers improved computational efficiency for complex models and large datasets
Stan vs PyMC
- Both Stan and PyMC support probabilistic programming for Bayesian inference
- Stan provides a compiled language for improved performance, while PyMC offers more flexibility in Python
- Stan's NUTS sampler often achieves better mixing than PyMC's samplers for complex models
- PyMC offers easier integration with Python's scientific computing ecosystem