The Bayesian Information Criterion (BIC) is a powerful tool in model selection, balancing model complexity with goodness of fit. It helps prevent overfitting by penalizing models with more parameters, making it widely used across various fields for comparing and selecting the most appropriate models.
BIC combines a likelihood function with a penalty term for model complexity. Its formula, BIC = -2ln(L̂) + kln(n), incorporates the maximized likelihood value, number of parameters, and sample size. Lower BIC values indicate better models, guiding researchers towards parsimonious yet effective explanations of observed data.
Definition of BIC
- Bayesian Information Criterion (BIC) serves as a model selection tool in Bayesian statistics
- Balances model complexity with goodness of fit, penalizing overly complex models
- Aids in choosing the most parsimonious model that adequately explains observed data
Purpose and applications
- Quantifies trade-off between model fit and complexity in statistical modeling
- Helps prevent overfitting by penalizing models with more parameters
- Widely used in various fields (econometrics, psychology, ecology) for model comparison
- Facilitates selection of the most appropriate model from a set of candidate models
Mathematical formulation
- BIC formula combines likelihood function with a penalty term for model complexity
- Expressed as
- represents the maximized value of the likelihood function for the model
- denotes the number of parameters in the model
- signifies the number of observations or sample size
- Lower BIC values indicate better models, balancing fit and simplicity
Components of BIC
- BIC incorporates key elements from Bayesian statistics and information theory
- Reflects the principle of Occam's razor, favoring simpler explanations
- Provides a quantitative measure for model comparison and selection
Likelihood function
- Measures how well the model fits the observed data
- Calculated as the probability of observing the data given the model parameters
- Increases with better model fit, potentially leading to overfitting if used alone
- Represented by in the BIC formula
- Plays a crucial role in determining the overall BIC value
Number of parameters
- Quantifies model complexity by counting free parameters
- Includes regression coefficients, intercepts, and variance terms
- Denoted by in the BIC formula
- Larger values increase the penalty term, discouraging overly complex models
- Helps balance the trade-off between model fit and parsimony
Sample size
- Represented by in the BIC formula
- Influences the strength of the penalty term for model complexity
- Larger sample sizes increase the penalty for additional parameters
- Ensures consistency of BIC as an estimator of model evidence
- Affects the relative importance of model fit versus simplicity in BIC calculation
BIC vs AIC
- Both BIC and Akaike Information Criterion (AIC) serve as model selection tools
- Derive from different theoretical foundations but share similar structures
- Play crucial roles in Bayesian model comparison and frequentist approaches
Similarities and differences
- Both balance model fit with complexity to prevent overfitting
- AIC uses a fixed penalty of 2 for each parameter, while BIC uses
- BIC penalizes complex models more heavily than AIC, especially for large sample sizes
- AIC aims to minimize prediction error, while BIC approximates Bayesian posterior probability
- Both criteria can lead to different model selections, especially with small sample sizes
Strengths and weaknesses
- BIC strengths include consistency in selecting true model as sample size increases
- BIC performs well when the true model exists within the candidate set
- AIC may perform better for prediction tasks and when the true model is complex
- BIC can be overly conservative, potentially missing important predictors in some cases
- Both criteria assume models are nested and may struggle with non-nested model comparisons
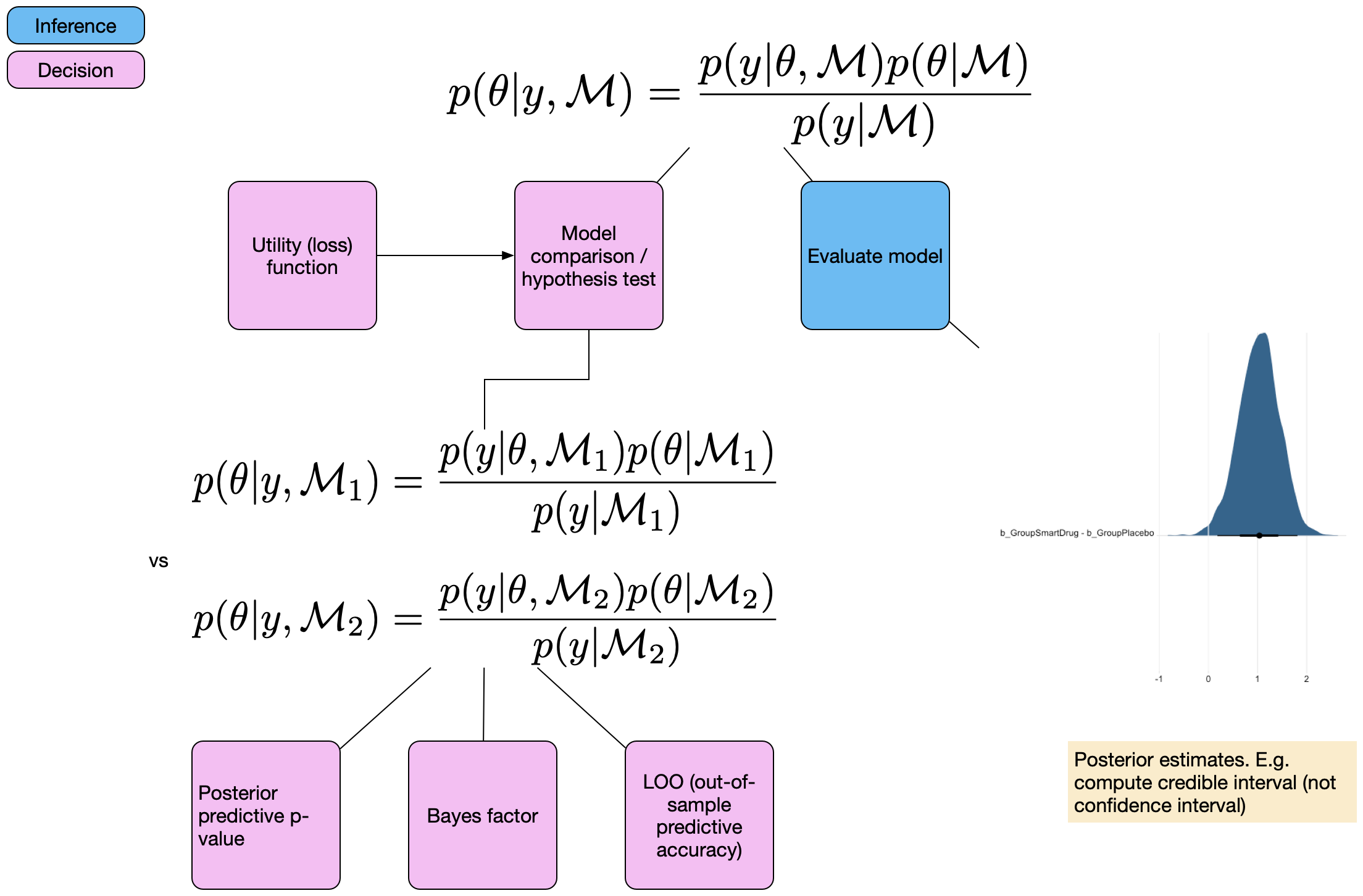
Calculation of BIC
- BIC calculation involves computing likelihood function and penalty term
- Requires estimation of model parameters and determination of sample size
- Can be performed manually or using statistical software packages
Step-by-step process
- Fit candidate models to the data using maximum likelihood estimation
- Calculate the maximized log-likelihood value for each model
- Determine the number of parameters () for each model
- Identify the sample size () of the dataset
- Compute BIC using the formula:
- Compare BIC values across models, selecting the one with the lowest BIC
Examples with different models
- Linear regression: BIC = 150.2 for model with 3 predictors, n = 100
- Logistic regression: BIC = 180.5 for model with 4 predictors, n = 200
- Time series ARIMA(1,1,1): BIC = 220.3 with 3 parameters, n = 150
- Factor analysis: BIC = 300.1 for 2-factor model, 5 observed variables, n = 250
Interpretation of BIC values
- BIC values themselves are not meaningful in isolation
- Interpretation focuses on differences in BIC values between models
- Provides a quantitative measure of relative model performance
Model comparison
- Calculate as the difference between BIC values of two models
- > 10 indicates very strong evidence for the model with lower BIC
- 6 < < 10 suggests strong evidence for the lower BIC model
- 2 < < 6 indicates positive evidence for the lower BIC model
- < 2 suggests weak or no evidence for preferring one model over another
Relative evidence strength
- Approximate Bayes factors can be derived from BIC differences
- provides an estimate of the Bayes factor
- Bayes factors quantify the relative evidence in favor of one model over another
- Interpret Bayes factors using guidelines (1-3: weak, 3-20: positive, 20-150: strong, >150: very strong)
- Use relative evidence strength to make informed decisions about model selection
Limitations of BIC
- BIC, while useful, has several limitations and assumptions
- Understanding these limitations ensures appropriate application and interpretation
- Awareness of potential issues helps researchers use BIC more effectively
Assumptions and violations
- Assumes models are nested, may not be suitable for non-nested model comparisons
- Relies on the assumption that one of the candidate models is the true model
- Assumes independent and identically distributed observations
- May not perform well when the true model is very complex
- Assumes equal prior probabilities for all models, which may not always be realistic
Large sample approximation
- BIC is derived as an asymptotic approximation, assuming large sample sizes
- Performance may be suboptimal for small sample sizes or high-dimensional data
- Can lead to overly conservative model selection with limited data
- May not capture complex relationships in datasets with many variables relative to observations
- Requires careful interpretation when applied to small or moderate sample sizes

BIC in model selection
- BIC plays a crucial role in various model selection procedures
- Facilitates objective comparison of multiple competing models
- Helps researchers choose parsimonious models that explain data well
Bayesian model averaging
- Uses BIC to approximate posterior model probabilities
- Combines predictions from multiple models weighted by their BIC-derived probabilities
- Accounts for model uncertainty in inference and prediction
- Calculates weights as
- Improves predictive performance by incorporating information from multiple models
Variable selection procedures
- Employs BIC to identify important predictors in regression models
- Stepwise selection methods use BIC as a criterion for adding or removing variables
- All-subsets regression compares BIC values across all possible variable combinations
- Lasso and elastic net regularization can be tuned using BIC
- Helps researchers identify parsimonious models with the most relevant predictors
Software implementation
- Various statistical software packages offer BIC calculation and model comparison
- Enables efficient computation of BIC for complex models and large datasets
- Facilitates easy comparison of multiple models using BIC
R packages for BIC
statspackage includes BIC function for linear and generalized linear modelsnlmepackage provides BIC for mixed-effects modelsglmnetpackage allows BIC-based tuning for regularized regression modelsMuMInpackage offers comprehensive model selection tools using BICBMApackage implements Bayesian Model Averaging with BIC approximation
Python libraries for BIC
statsmodelslibrary includes BIC calculation for various statistical modelssklearnprovides BIC for Gaussian Mixture Models and other clustering algorithmspymc3allows BIC computation for Bayesian modelslifelinesoffers BIC for survival analysis modelslinearmodelsincludes BIC for panel data and instrumental variable models
Advanced topics in BIC
- BIC research continues to evolve, addressing limitations and extending applications
- Advanced topics explore BIC's behavior in complex modeling scenarios
- Ongoing developments aim to improve BIC's performance and versatility
BIC for non-nested models
- Extends BIC to compare models that are not hierarchically related
- Involves adjusting the penalty term to account for different model structures
- Uses methods like cross-validation or bootstrapping to estimate effective sample size
- Applies techniques like encompassing models or artificial nesting
- Helps researchers compare fundamentally different model types (linear vs. nonlinear)
Extensions and variations
- Deviance Information Criterion (DIC) extends BIC to hierarchical Bayesian models
- Widely Applicable Information Criterion (WAIC) provides a fully Bayesian approach
- Focused Information Criterion (FIC) adapts BIC for specific prediction tasks
- Conditional AIC (cAIC) modifies BIC for mixed-effects models
- Composite Likelihood BIC (CLBIC) extends BIC to complex dependence structures