Ridge regression adds a penalty term to linear regression, shrinking coefficients towards zero. This L2 regularization technique helps prevent overfitting and handles multicollinearity, striking a balance between model complexity and performance.
The regularization parameter λ controls the strength of shrinkage. As λ increases, coefficients are pulled closer to zero. Cross-validation helps find the optimal λ, balancing bias and variance for better generalization.
Ridge Regression Fundamentals
Overview and Key Concepts
- Ridge regression extends linear regression by adding a penalty term to the ordinary least squares (OLS) objective function
- L2 regularization refers to the specific type of penalty used in ridge regression, which is the sum of squared coefficients multiplied by the regularization parameter
- The penalty term in ridge regression is , where is the regularization parameter and are the regression coefficients
- This penalty term is added to the OLS objective function, resulting in the ridge regression objective:
- The regularization parameter controls the strength of the penalty
- When , ridge regression reduces to OLS
- As , the coefficients are shrunk towards zero
- Shrinkage refers to the effect of the penalty term, which shrinks the regression coefficients towards zero compared to OLS
- This can help prevent overfitting and improve the model's generalization performance
Geometric Interpretation
- Ridge regression can be interpreted as a constrained optimization problem
- The objective is to minimize the RSS (residual sum of squares) subject to a constraint on the L2 norm of the coefficients: , where is a tuning parameter related to
- Geometrically, this constraint corresponds to a circular region in the parameter space
- The ridge regression solution is the point where the RSS contour lines first touch this circular constraint region
- As the constraint becomes tighter (smaller , larger ), the solution is pulled further towards the origin, resulting in greater shrinkage of the coefficients
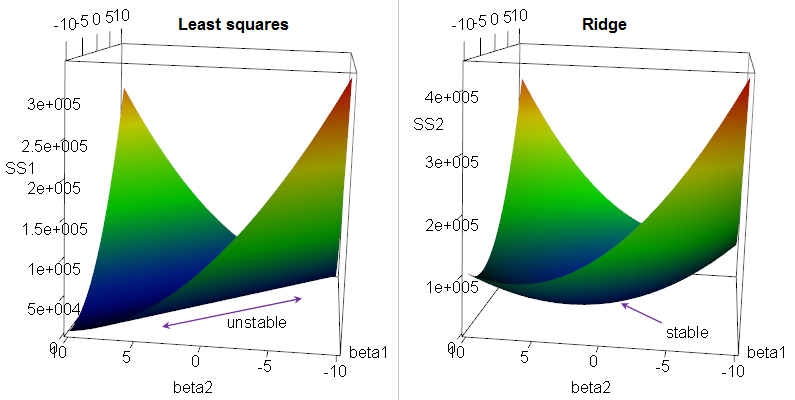
Benefits and Tradeoffs
Bias-Variance Tradeoff
- Ridge regression can improve a model's performance by reducing its variance at the cost of slightly increasing its bias
- The penalty term constrains the coefficients, limiting the model's flexibility and thus reducing variance
- However, this constraint also introduces some bias, as the coefficients are shrunk towards zero and may not match the true underlying values
- The bias-variance tradeoff is controlled by the regularization parameter
- Larger values result in greater shrinkage, lower variance, and higher bias
- Smaller values result in less shrinkage, higher variance, and lower bias
- The optimal value can be selected using techniques like cross-validation to balance bias and variance and minimize the model's expected test error
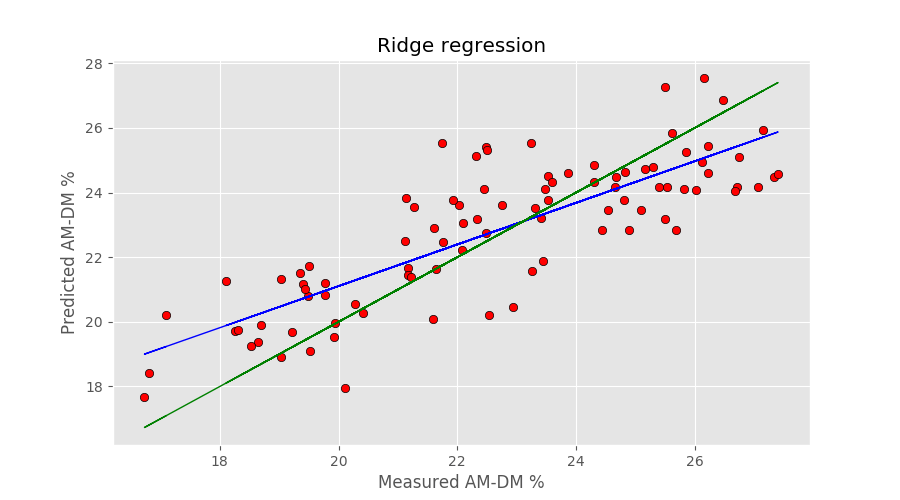
Handling Multicollinearity
- Multicollinearity occurs when predictor variables in a regression model are highly correlated with each other
- This can lead to unstable and unreliable coefficient estimates in OLS
- Ridge regression can effectively handle multicollinearity by shrinking the coefficients of correlated predictors towards each other
- This results in a more stable and interpretable model, as the impact of multicollinearity on the coefficient estimates is reduced
- When predictors are highly correlated, ridge regression tends to assign similar coefficients to them, reflecting their shared contribution to the response variable
Model Selection via Cross-Validation
- Cross-validation is commonly used to select the optimal value of the regularization parameter in ridge regression
- The procedure involves:
- Splitting the data into folds
- For each value in a predefined grid:
- Train ridge regression models on folds and evaluate their performance on the held-out fold
- Repeat this process times, using each fold as the validation set once
- Compute the average performance across the folds
- Select the value that yields the best average performance
- This process helps identify the value that strikes the best balance between bias and variance, optimizing the model's expected performance on new, unseen data
Solving Ridge Regression
Closed-Form Solution
- Ridge regression has a closed-form solution, which can be derived analytically by solving the normal equations with the addition of the penalty term
- The closed-form solution for ridge regression is given by:
where:
- is the matrix of predictor variables
- is the vector of response values
- is the regularization parameter
- is the identity matrix
- Compared to the OLS solution , ridge regression adds the term to the matrix before inversion
- This addition makes the matrix invertible even when is not (e.g., in the presence of perfect multicollinearity)
- The closed-form solution for ridge regression is computationally efficient and numerically stable, even when dealing with high-dimensional data or correlated predictors