Deep learning has evolved beyond basic neural networks. Advanced architectures like GANs and transformers push the boundaries of what AI can do, from generating realistic fake data to understanding complex language patterns.
Transfer learning techniques allow us to leverage pre-trained models for new tasks. This approach saves time and resources, making powerful AI more accessible and enabling breakthroughs in various fields like computer vision and natural language processing.
Advanced Neural Network Architectures
Generative Models and Autoencoders
- Generative Adversarial Networks (GANs) consist of two neural networks, a generator and a discriminator, that compete against each other
- The generator learns to create realistic fake data (images, text, etc.) to fool the discriminator
- The discriminator learns to distinguish between real and fake data
- Through this adversarial training process, GANs can generate highly realistic synthetic data (deepfakes, art, music)
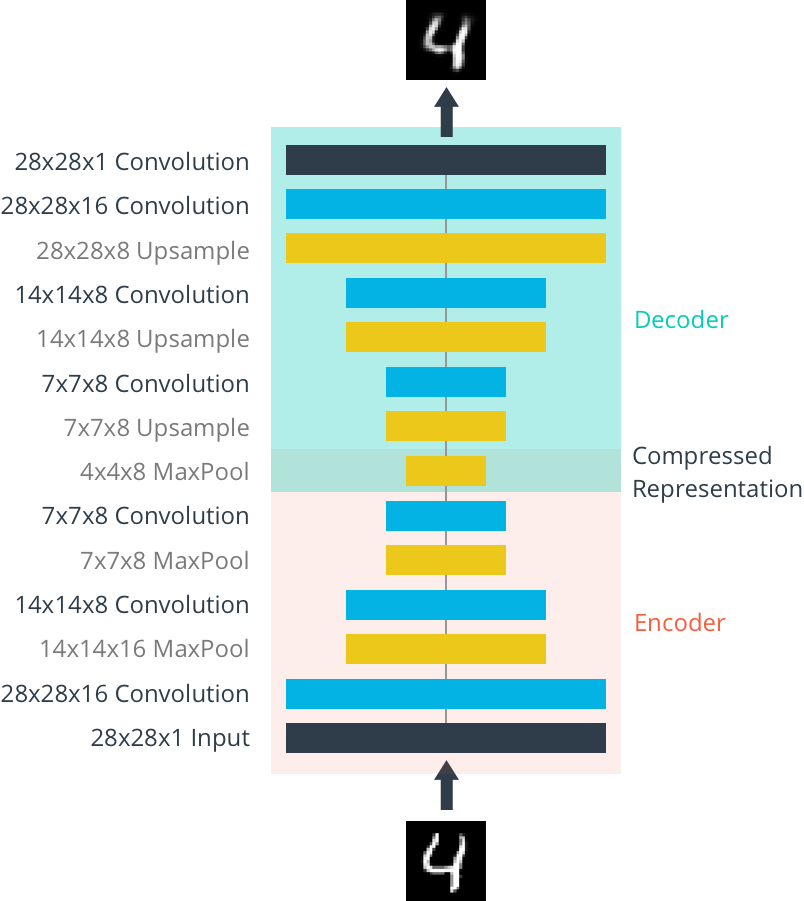
- Autoencoders are neural networks designed to learn efficient data representations by encoding input data into a lower-dimensional latent space and then decoding it back to the original space
- The encoder compresses the input data into a compact representation (bottleneck layer)
- The decoder reconstructs the original data from the compressed representation
- Autoencoders can be used for dimensionality reduction, denoising, and anomaly detection (credit card fraud, manufacturing defects)

Transformer Architecture and Attention Mechanism
- The Transformer architecture, originally designed for natural language processing tasks, relies solely on attention mechanisms to capture dependencies between input and output sequences
- It consists of an encoder and a decoder, each composed of multiple layers of self-attention and feed-forward neural networks
- The self-attention mechanism allows the model to attend to different parts of the input sequence when generating each output element
- Transformers have achieved state-of-the-art performance in tasks such as machine translation, text summarization, and question answering (GPT-3, BERT)
- The Attention Mechanism is a technique that helps neural networks focus on the most relevant parts of the input when making predictions
- It assigns importance weights to different elements of the input sequence based on their relevance to the current output
- Attention can be used in various architectures, including recurrent neural networks (RNNs) and transformers
- Attention has been instrumental in improving the performance of models in tasks such as image captioning, speech recognition, and sentiment analysis (identifying key words and phrases)
Transfer Learning Techniques
Transfer Learning and Fine-tuning
- Transfer Learning is a technique that involves using a pre-trained model, which has already learned features from a large dataset, as a starting point for a new task
- The pre-trained model's weights are used to initialize the new model, which is then fine-tuned on the target task
- Transfer learning can significantly reduce training time and improve performance, especially when the target dataset is small
- It has been successfully applied in various domains, such as computer vision (using pre-trained ImageNet models), natural language processing (using pre-trained language models like BERT), and speech recognition
- Fine-tuning is the process of adapting a pre-trained model to a specific task by training it further on a smaller, task-specific dataset
- The pre-trained model's architecture is typically kept the same, but the final layers may be replaced or modified to suit the target task
- During fine-tuning, the model's weights are updated using backpropagation to minimize the loss on the target task
- Fine-tuning allows the model to learn task-specific features while leveraging the general features learned from the pre-training phase (adapting an ImageNet model for medical image classification)
Pre-trained Models and Their Applications
- Pre-trained Models are neural networks that have been trained on large datasets and can be used as a starting point for various downstream tasks
- These models have learned general features and representations that can be transferred to other tasks, reducing the need for extensive training from scratch
- Popular pre-trained models include ImageNet models (ResNet, Inception) for computer vision, and language models (BERT, GPT) for natural language processing
- Pre-trained models can be used for feature extraction, where the model's intermediate representations are used as input features for other machine learning algorithms (using BERT embeddings for text classification)
- Pre-trained models have been instrumental in advancing the state-of-the-art in various domains and have made deep learning more accessible to researchers and practitioners with limited computational resources
- They have enabled the development of powerful applications such as image and video recognition (facial recognition, autonomous vehicles), natural language understanding (sentiment analysis, chatbots), and speech recognition (virtual assistants, transcription services)
- The availability of pre-trained models has also fostered the creation of model repositories and libraries (TensorFlow Hub, PyTorch Hub) that allow users to easily access and deploy these models for their specific use cases