Elastic Net combines L1 and L2 regularization, offering a sweet spot between Lasso and Ridge regression. It's like having your cake and eating it too - you get feature selection and coefficient shrinkage in one neat package.
This method is super handy when you're dealing with loads of features or correlated predictors. By tweaking the alpha and lambda parameters, you can fine-tune your model to strike the perfect balance between simplicity and accuracy.
Elastic Net and Regularization
Combining L1 and L2 Regularization
- Elastic Net is a regularization technique that linearly combines the L1 (Lasso) and L2 (Ridge) penalties
- Introduces a compromise between the two regularization methods
- Allows for both feature selection (L1) and coefficient shrinkage (L2)
- The combination of L1 and L2 penalties is controlled by the alpha parameter
- Alpha ranges from 0 to 1, where 0 corresponds to pure Ridge regression and 1 corresponds to pure Lasso regression
- Intermediate values of alpha result in a mix of L1 and L2 regularization
- Elastic Net can handle situations where the number of features is larger than the number of observations (high-dimensional data)
Tuning Regularization Strength
- The regularization strength in Elastic Net is determined by the hyperparameter lambda
- Higher values of lambda lead to stronger regularization and more coefficient shrinkage towards zero
- Lower values of lambda result in less regularization and coefficients closer to the ordinary least squares estimates
- Tuning the regularization strength is crucial to balance between model complexity and generalization performance
- Cross-validation techniques (k-fold) are commonly used to select the optimal value of lambda
- The goal is to find the lambda that minimizes the cross-validation error

Preventing Overfitting
- Elastic Net helps prevent overfitting by adding a penalty term to the objective function
- The penalty term discourages the model from assigning large coefficients to features, reducing model complexity
- By controlling the magnitude of coefficients, Elastic Net reduces the impact of irrelevant or noisy features
- The combination of L1 and L2 penalties in Elastic Net provides a balance between feature selection and coefficient shrinkage
- L1 penalty (Lasso) encourages sparsity by setting some coefficients exactly to zero, effectively performing feature selection
- L2 penalty (Ridge) shrinks the coefficients towards zero, reducing their magnitude but keeping all features in the model
Model Selection and Interpretation
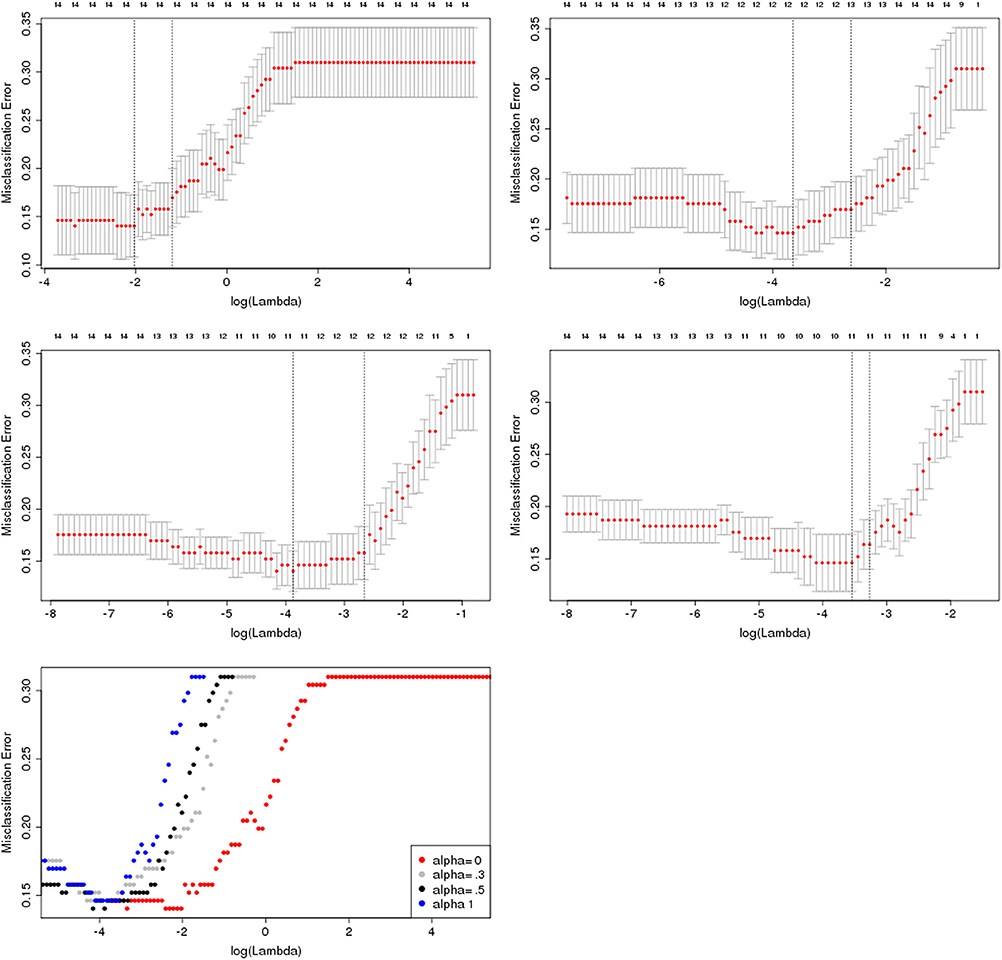
Selecting the Optimal Model
- Model selection involves choosing the best model among different regularization methods (Lasso, Ridge, Elastic Net) and hyperparameter settings
- Compare the performance of models using evaluation metrics such as mean squared error (MSE) or R-squared
- Use cross-validation to estimate the generalization performance of each model
- Consider the trade-off between model complexity and interpretability when selecting the final model
- Simpler models (Lasso) may be preferred if interpretability is a priority
- More complex models (Elastic Net) may be chosen if predictive performance is the main goal
Interpreting Feature Importance
- Regularization methods provide insights into feature importance by examining the magnitude of the coefficients
- Features with larger absolute coefficients are considered more important in the model
- Lasso and Elastic Net can perform feature selection by setting some coefficients exactly to zero, indicating irrelevant features
- Analyze the sign and magnitude of the coefficients to understand the direction and strength of the relationship between features and the target variable
- Positive coefficients indicate a positive relationship, while negative coefficients suggest a negative relationship
- The magnitude of the coefficients represents the impact of each feature on the predicted outcome
Assessing Model Stability
- Evaluate the stability of the selected model across different subsets of the data or different random seeds
- Stable models produce consistent feature importance rankings and coefficient estimates
- Unstable models may have high variability in feature importance and coefficient values
- Use techniques such as bootstrap resampling or permutation tests to assess the robustness of the model
- Bootstrap resampling involves fitting the model on multiple bootstrap samples and examining the variability of the coefficients
- Permutation tests shuffle the target variable to create a null distribution and assess the significance of the observed coefficients
Enhancing Interpretability
- Regularization methods can improve model interpretability by reducing the number of features and focusing on the most important ones
- Lasso and Elastic Net perform feature selection, making the model more interpretable by excluding irrelevant features
- Ridge regression keeps all features in the model but shrinks their coefficients, making it easier to identify the most influential features
- Visualize the coefficients or feature importance scores to gain insights into the model's behavior
- Use bar plots or heatmaps to display the magnitude and direction of the coefficients
- Create partial dependence plots to visualize the relationship between individual features and the predicted outcome
- Communicate the model's interpretability to stakeholders by providing clear explanations of the selected features and their impact on the predictions