Dimensionality reduction techniques go beyond PCA, offering diverse ways to simplify complex data. Linear methods like LDA and ICA, along with non-linear approaches such as t-SNE and UMAP, provide powerful tools for visualizing and analyzing high-dimensional datasets.
Matrix factorization and autoencoders round out the toolkit, enabling interpretable representations and feature learning. These techniques are crucial for tackling the challenges of high-dimensional data in machine learning and statistical prediction.
Linear Techniques
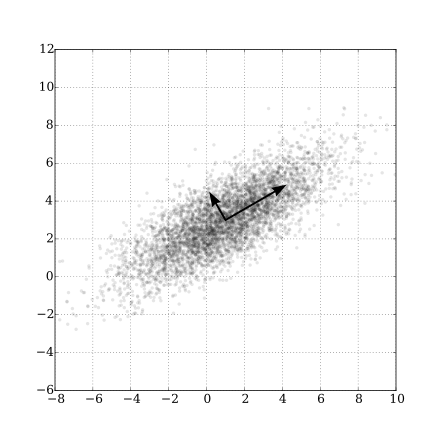
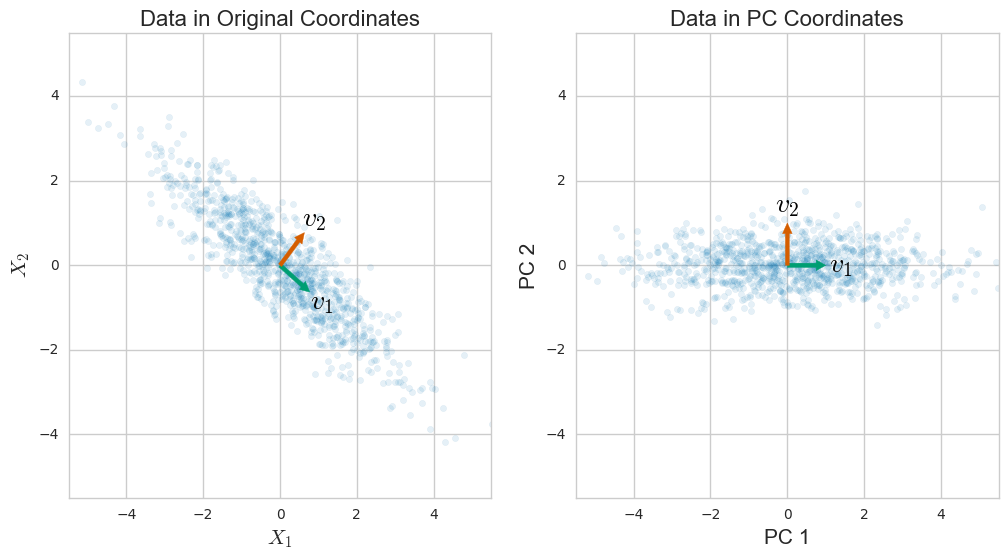
Principal Component Analysis (PCA)
- Unsupervised linear transformation technique reduces dimensionality by projecting data onto lower dimensions
- Finds principal components, which are directions of maximum variance in high-dimensional data
- First principal component captures the most variance possible, followed by second component orthogonal to first, and so on
- Preserves global structure of data while minimizing information loss
- Applications include data compression, visualization, and feature extraction
Linear Discriminant Analysis (LDA) and Factor Analysis
- LDA is supervised dimensionality reduction technique finds linear combinations of features best separates classes
- Maximizes between-class separability while minimizing within-class variability
- Useful for classification tasks and visualizing class separability in lower-dimensional space
- Factor Analysis is similar to PCA but assumes underlying latent factors generate observed variables
- Latent factors are unobserved variables that influence multiple observed variables (stock market returns influenced by economic growth and investor sentiment)
- Goal is to identify and extract these latent factors to understand underlying structure of data
Independent Component Analysis (ICA)
- Separates multivariate signal into additive subcomponents assuming non-Gaussian and statistically independent
- Useful for separating mixed signals into original sources (cocktail party problem: separating individual voices from mixed audio recordings)
- Recovers original signals by maximizing statistical independence between estimated components
- Applications include signal processing, feature extraction, and blind source separation
Non-linear Techniques
t-SNE (t-Distributed Stochastic Neighbor Embedding)
- Non-linear dimensionality reduction technique for visualization of high-dimensional data
- Preserves local structure of data points in high-dimensional space when projecting to lower dimensions
- Calculates probabilities of similarity between data points in original space and lower-dimensional space
- Minimizes Kullback-Leibler divergence between joint probabilities in high and low dimensions to preserve local structure
- Useful for visualizing complex datasets (visualizing clusters in image or text data)
UMAP (Uniform Manifold Approximation and Projection) and Kernel PCA
- UMAP is non-linear dimensionality reduction technique based on manifold learning and topological data analysis
- Assumes data lies on low-dimensional manifold embedded in high-dimensional space
- Constructs weighted graph representing manifold and optimizes low-dimensional representation to preserve graph structure
- More computationally efficient than t-SNE and better preserves global structure of data
- Kernel PCA is non-linear extension of PCA uses kernel trick to map data to higher-dimensional feature space
- Performs PCA in this feature space to capture non-linear relationships in original data
- Choice of kernel function (Gaussian, polynomial) determines type of non-linear transformation applied
Matrix Factorization
Non-negative Matrix Factorization (NMF)
- Dimensionality reduction technique factorizes non-negative matrix into two non-negative matrices
- Approximates original matrix as product of two lower-rank matrices
- Useful when data has inherent non-negativity (image pixels, word counts in documents)
- Generates interpretable parts-based representations of data (facial features in images, topics in text documents)
- Applications include image and audio processing, recommender systems, and topic modeling
Autoencoders
- Neural network architecture learns compressed representation of input data
- Consists of encoder network maps input to lower-dimensional latent space and decoder network reconstructs input from latent representation
- Trained to minimize reconstruction error between original input and reconstructed output
- Latent space represents compressed representation capturing important features of data
- Variations include denoising autoencoders (corrupted input), variational autoencoders (probabilistic latent space), and sparse autoencoders (sparsity constraints on latent representation)
- Applications include dimensionality reduction, feature learning, and anomaly detection