Linear Discriminant Analysis (LDA) and related techniques are powerful tools for classification. They work by finding the best way to separate different groups of data, assuming the groups follow certain patterns. LDA is especially good when the data in each group spreads out in similar ways.
These methods build on basic ideas like normal distributions and Bayes' theorem. They can be tweaked to handle more complex data patterns, like in Quadratic Discriminant Analysis (QDA) or Regularized Discriminant Analysis (RDA). Understanding these techniques helps you choose the right tool for your classification task.
Linear and Quadratic Discriminant Analysis
Linear Discriminant Analysis (LDA)
- Supervised learning technique used for classification tasks assumes classes are linearly separable
- Finds linear combinations of features (discriminant functions) that best separate classes by maximizing between-class variance and minimizing within-class variance
- Assumes all classes have equal covariance matrices and multivariate normal distribution of data within each class
- Computationally efficient and performs well when assumptions are met (multivariate normal distribution, equal covariance matrices)
- Can be used for dimensionality reduction by projecting data onto lower-dimensional space while preserving class separability
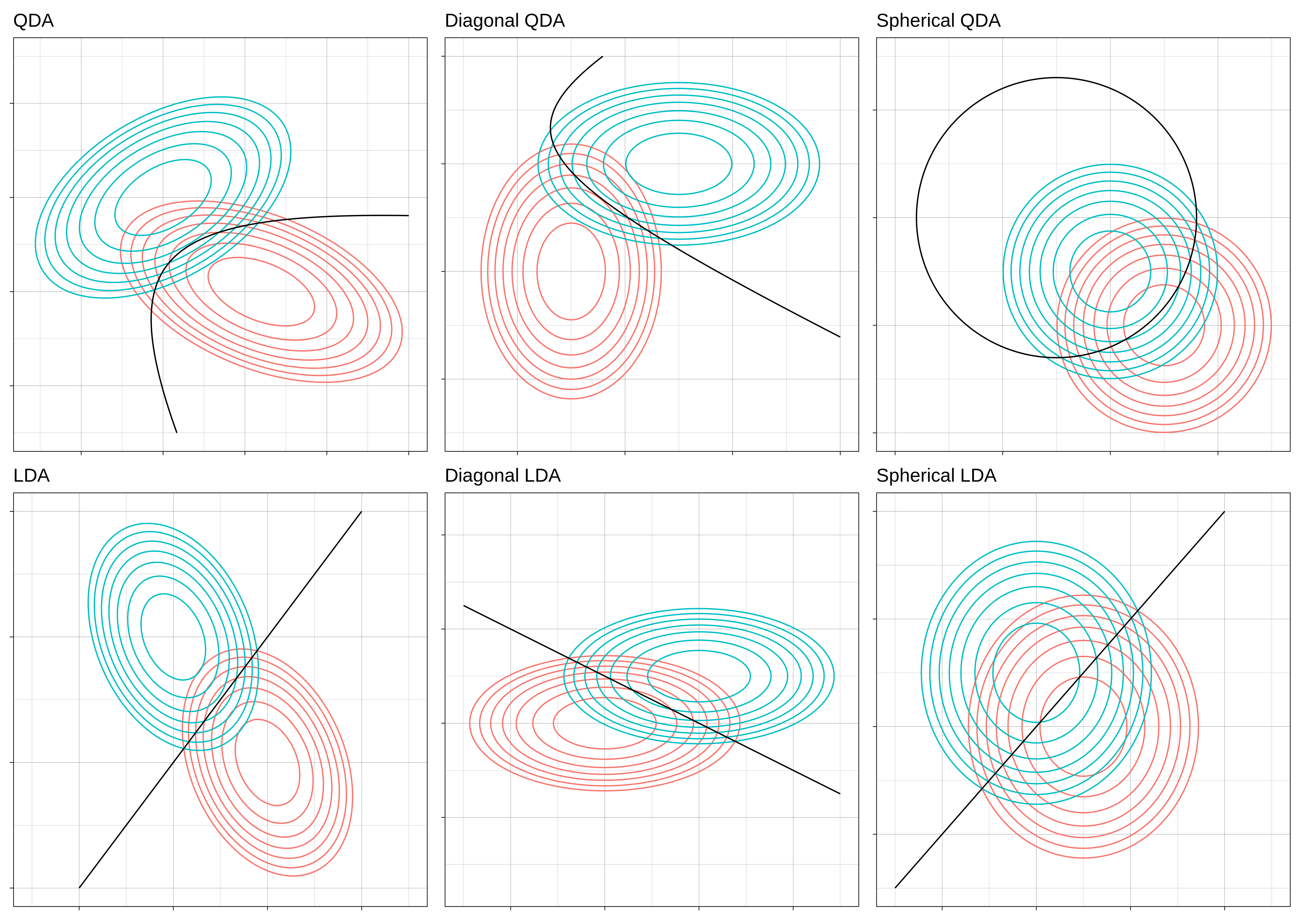
Quadratic Discriminant Analysis (QDA)
- Extension of LDA that allows for non-linear decision boundaries by fitting a quadratic surface to separate classes
- Assumes each class has its own covariance matrix, allowing for more flexibility in capturing class distributions compared to LDA
- Performs better than LDA when classes have different covariance matrices but requires more training data to estimate parameters reliably
- More computationally expensive than LDA due to estimating separate covariance matrices for each class
- Can lead to overfitting if training data is limited or if the number of features is high relative to sample size
Multivariate Normal Distribution and Covariance Matrices
- Probability distribution used to model multivariate continuous data assumes variables are jointly normally distributed
- Characterized by a mean vector and a covariance matrix that captures the relationships between variables
- Covariance matrices in LDA and QDA represent the spread and orientation of data points within each class
- Equal covariance matrices in LDA lead to linear decision boundaries
- Different covariance matrices in QDA allow for quadratic decision boundaries
- Estimating accurate covariance matrices is crucial for the performance of LDA and QDA (requires sufficient training data)
Bayesian Discriminant Analysis
Bayes' Theorem and Discriminant Analysis
- Probabilistic approach to classification based on Bayes' theorem, which relates conditional probabilities
- Computes posterior probabilities of class membership given the observed features using prior probabilities and class-conditional densities
- Assigns an observation to the class with the highest posterior probability, minimizing the expected misclassification cost
- Allows for incorporating prior knowledge about class probabilities and can handle imbalanced datasets
- Provides a principled way to handle uncertainty in class assignments and can output class membership probabilities
Regularized Discriminant Analysis (RDA)
- Combines LDA and QDA by introducing regularization to improve performance and stability, especially when sample size is small relative to the number of features
- Regularization helps to shrink the estimated covariance matrices towards a common matrix, reducing the impact of noise and preventing overfitting
- Controlled by two tuning parameters: (controls the degree of shrinkage towards a common covariance matrix) and (controls the degree of shrinkage towards a diagonal matrix)
- corresponds to QDA, corresponds to LDA
- uses the full covariance matrix, uses a diagonal covariance matrix
- Can be seen as a compromise between the simplicity of LDA and the flexibility of QDA, adapting to the complexity of the data
Related Techniques
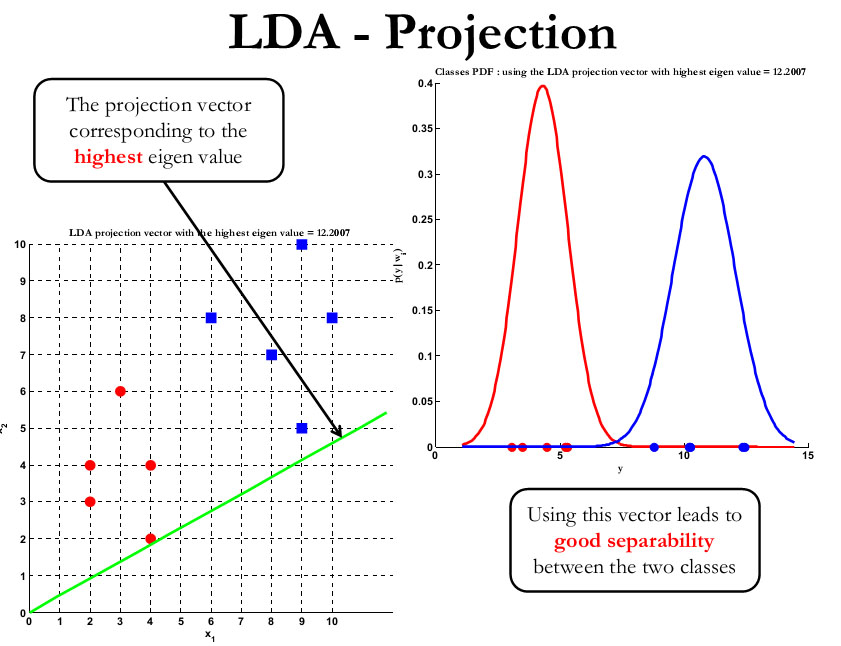
Fisher's Linear Discriminant
- Technique for finding a linear combination of features that maximizes the separation between two classes
- Seeks to find a projection vector that maximizes the ratio of between-class variance to within-class variance (Fisher's criterion)
- The optimal projection vector is given by the eigenvector corresponding to the largest eigenvalue of the matrix , where is the within-class scatter matrix and is the between-class scatter matrix
- Can be extended to multi-class problems by finding multiple discriminant vectors that maximize the separation between all pairs of classes (e.g., one-vs-one or one-vs-rest)
- Closely related to LDA but focuses on finding the most discriminative projection rather than modeling class distributions explicitly
Mahalanobis Distance
- Distance metric that measures the dissimilarity between a point and a distribution, taking into account the correlations between variables
- Defined as , where is a data point, is the mean vector of the distribution, and is the covariance matrix
- Unitless and scale-invariant, allowing for comparison of distances across different feature spaces
- Used in discriminant analysis to classify observations based on their Mahalanobis distances to class centroids (assign to the class with the smallest distance)
- Can be used for outlier detection by identifying points that are far from the main distribution (e.g., points with Mahalanobis distances greater than a certain threshold)