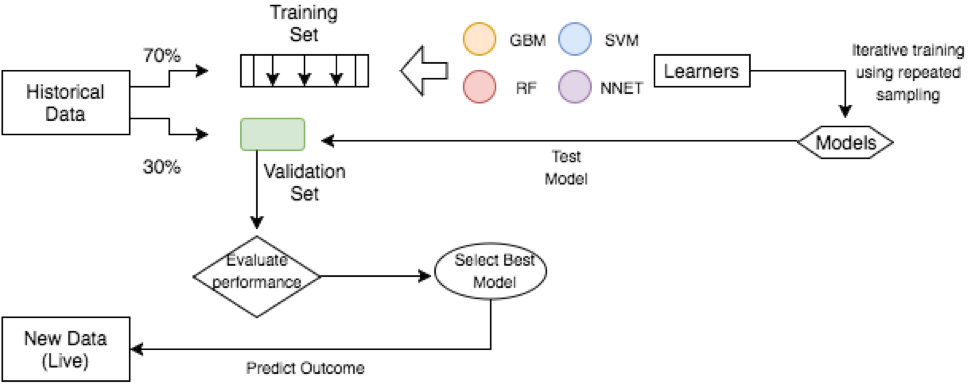
Data splitting is crucial in machine learning. It helps us train models, tune them, and test their real-world performance. By dividing our data into training, validation, and test sets, we can build more robust and reliable models.
This topic connects to the broader chapter by addressing the bias-variance tradeoff. Proper data splitting helps us balance model complexity and generalization, ensuring our models perform well on new, unseen data.
Dataset Partitioning
Training, Validation, and Test Sets
- Datasets are typically divided into three distinct subsets: training set, validation set, and test set to evaluate and optimize machine learning models
- Training set used to train the model, allowing it to learn patterns and relationships in the data (typically 60-80% of the dataset)
- Validation set used to tune hyperparameters and assess model performance during training (typically 10-20% of the dataset)
- Helps prevent overfitting by providing an unbiased evaluation of the model's performance on unseen data
- Allows for model selection and hyperparameter optimization
- Test set used to evaluate the final model's performance on completely unseen data (typically 10-20% of the dataset)
- Provides an unbiased estimate of the model's generalization ability and real-world performance
- Should only be used once the model is fully trained and optimized to avoid data leakage
Holdout Method
- Holdout method is a simple approach to splitting data into training and test sets
- Involves randomly partitioning the dataset into two subsets: a training set and a test set
- Training set used to train the model, while the test set is held out and used to evaluate the model's performance on unseen data
- Provides an unbiased estimate of the model's generalization ability, but may not be optimal for small datasets or when the data distribution is not representative
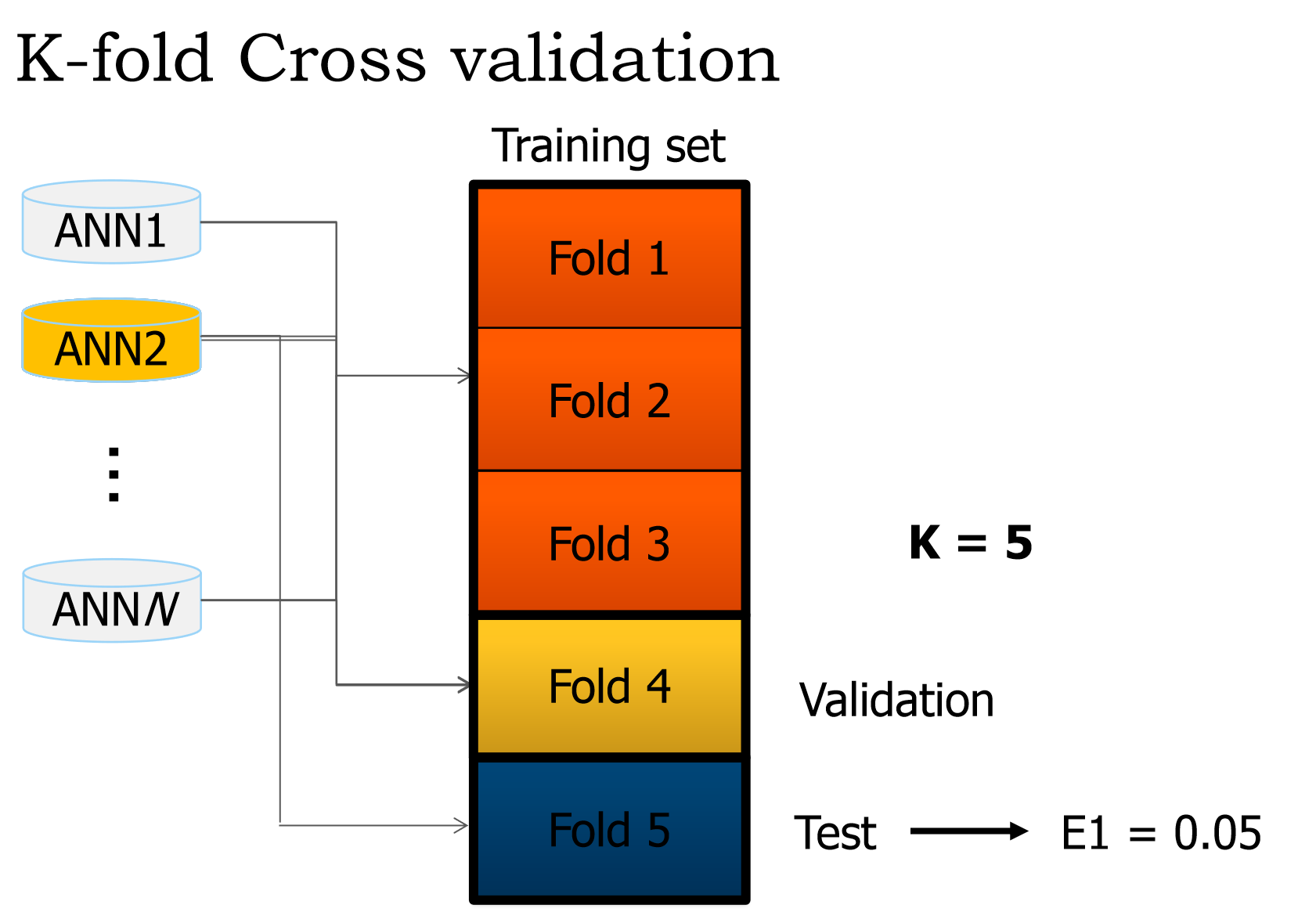
Sampling Techniques
Stratified and Random Sampling
- Stratified sampling ensures that the proportion of each class or category in the original dataset is maintained in the training, validation, and test sets
- Particularly useful when dealing with imbalanced datasets (where one class has significantly more instances than others)
- Helps ensure that the model is exposed to a representative distribution of classes during training and evaluation
- Random sampling involves randomly selecting instances from the dataset without considering their class or category
- Assumes that the data is homogeneous and that the random selection will result in a representative sample
- May not be suitable for imbalanced datasets or when certain classes or categories are underrepresented
Temporal Splitting
- Temporal splitting is used when working with time-series data or datasets where the temporal order is important
- Involves splitting the dataset based on a specific time point or interval
- Data before the split point is used for training, while data after the split point is used for validation and testing
- Ensures that the model is trained on past data and evaluated on future data, mimicking real-world scenarios
- Helps assess the model's ability to make predictions or decisions based on historical data
- Commonly used in applications such as stock price prediction, weather forecasting, and sales forecasting
Data Integrity
Data Leakage
- Data leakage occurs when information from the test set or future unseen data is inadvertently used during the model training process
- Can lead to overly optimistic performance estimates and poor generalization to new data
- Common causes of data leakage include:
- Using the entire dataset for preprocessing or feature selection before splitting into training and test sets
- Improperly handling temporal dependencies in time-series data (using future information to predict past events)
- Incorporating information from the test set during model training or hyperparameter tuning
- To prevent data leakage:
- Ensure that data splitting is performed before any preprocessing, feature selection, or model training steps
- Use techniques like cross-validation to assess model performance and tune hyperparameters
- Be cautious when handling time-series data and ensure that future information is not used to make predictions about the past