Polynomial regression takes linear regression up a notch by adding curved terms. This lets us model wiggly relationships between variables, like how your income might peak in middle age. It's super flexible but can go overboard if we're not careful.
To avoid fitting every little blip in our data, we can use tricks like cross-validation or regularization. We can also try splines, which are like connecting the dots with smooth curves. These tools help us find the sweet spot between too simple and too complex.
Polynomial Regression Models
Polynomial Terms and Model Complexity
- Polynomial regression models extend linear regression by adding polynomial terms of the predictor variables
- Allows modeling non-linear relationships between predictors and the response variable
- Polynomial terms are created by raising each predictor to a power (e.g., , )
- Model complexity increases as higher degree polynomial terms are added
- Higher degree polynomials can fit more complex, non-linear patterns in the data
- Increases the flexibility of the model to capture intricate relationships
- Must be balanced against the risk of overfitting
Quadratic and Cubic Regression
- Quadratic regression includes polynomial terms up to degree 2 for each predictor
- Adds squared terms like , to the model
- Can model relationships where the response increases then decreases (or vice versa) as the predictor changes
- Example: Modeling the relationship between age and income, where income may peak at middle age
- Cubic regression includes polynomial terms up to degree 3
- Adds cubed terms like , in addition to squared terms
- Can capture more complex non-linear patterns with multiple bends or inflection points
- Provides greater flexibility than quadratic regression but with increased complexity
- Example: Modeling the relationship between temperature and crop yield, where yield may have multiple peaks and valleys at different temperature ranges
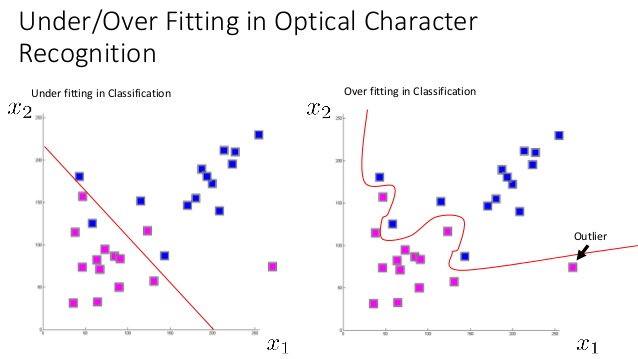
Overfitting and Complexity
Overfitting in Polynomial Regression
- Overfitting occurs when a model is too complex and fits the noise in the training data rather than the underlying pattern
- Model performs well on training data but poorly on new, unseen data
- High degree polynomial terms can lead to overfitting by capturing random fluctuations
- Overfitting can be mitigated by:
- Regularization techniques (e.g., ridge regression, lasso) that penalize large coefficients
- Cross-validation to assess model performance on held-out data and select appropriate complexity
- Limiting the degree of polynomial terms based on domain knowledge or data exploration
Basis Functions and Splines
- Basis functions are a set of functions used to represent the predictor variables in a regression model
- Polynomial terms (e.g., , , ) are a type of basis function
- Other basis functions include trigonometric functions, wavelets, and splines
- Splines are piecewise polynomial functions used to model complex non-linear relationships
- Divide the range of a predictor into segments and fit separate low-degree polynomials in each segment
- Ensure continuity and smoothness at the segment boundaries (knots)
- Examples include cubic splines, B-splines, and natural splines
- Splines provide a flexible way to model non-linear relationships while controlling complexity
- Knot locations and the degree of polynomials can be chosen to balance fit and smoothness
- Regularization can be applied to spline coefficients to prevent overfitting