Least Squares Estimation
Minimizing the Sum of Squared Residuals
The least squares method finds the regression coefficients that make the model's predictions as close to the observed data as possible. It does this by minimizing the sum of squared residuals (SSE), which is the total squared distance between each observed response value and the value the model predicts.
To find the minimum, you take the partial derivative of the SSE with respect to each coefficient, set those derivatives equal to zero, and solve the resulting system of normal equations. The solution gives you the least squares estimates.
A key property: when the classical linear regression assumptions hold, these estimates are BLUE (Best Linear Unbiased Estimators). That means among all estimators that are both linear and unbiased, the least squares estimates have the smallest variance.
Computing Least Squares Estimates
In matrix form, the estimated coefficient vector is:
- is the design matrix, where each row is an observation and each column is a predictor (plus a column of 1s for the intercept).
- is the vector of observed response values.
To get the standard errors of the estimated coefficients, you use the variance-covariance matrix of the estimators:
Here is the unbiased estimate of the error variance, calculated as , where is the number of observations and is the number of estimated coefficients (including the intercept).
The standard error for each coefficient is the square root of the corresponding diagonal element of this matrix. Larger standard errors mean less precision in the estimate, which makes it harder to conclude that the predictor has a real effect.
Coefficient Interpretation
Understanding Coefficient Estimates
Each estimated coefficient represents the expected change in the response variable for a one-unit increase in predictor , holding all other predictors constant (ceteris paribus).
For example, suppose you're modeling salary and the estimated coefficient for years of experience is 2.3 (with salary in thousands of dollars). That means each additional year of experience is associated with a $2,300 increase in expected salary, assuming all other predictors stay the same.
A few things to keep in mind:
- The sign tells you the direction. Positive means the response increases as the predictor increases; negative means it decreases.
- The magnitude depends on the units of measurement. A coefficient of 0.001 for income measured in dollars and a coefficient of 1.0 for income measured in thousands of dollars can represent the same relationship. Always check the units before comparing coefficient sizes across predictors.
Hypothesis Testing and Significance
For each coefficient, you typically test whether the true population parameter equals zero (i.e., the predictor has no linear effect on the response). The steps:
-
Calculate the t-statistic:
-
Find the p-value from the -distribution with degrees of freedom.
-
Compare to your significance level (commonly ).
A large and a small p-value (below ) lead you to reject the null hypothesis, concluding the predictor has a statistically significant linear association with the response. A small and large p-value suggest the predictor may not contribute meaningful information beyond what the other predictors already provide.
Model Goodness of Fit
Coefficient of Determination (R-squared)
R-squared () measures the proportion of total variation in the response that the model explains. It ranges from 0 to 1.
- TSS (Total Sum of Squares): , the total variation in the response around its mean.
- ESS (Explained Sum of Squares): , the variation accounted for by the model.
- SSE (Residual Sum of Squares): , the leftover variation.
An of 0.82, for instance, means the model explains 82% of the variation in the response. You can also interpret as the squared correlation between the observed values and the fitted values .
Adjusted R-squared and Model Selection
One problem with : it never decreases when you add another predictor, even a useless one. Adjusted fixes this by penalizing for the number of predictors:
Adjusted will only increase if a new predictor improves the model more than you'd expect by chance alone. This makes it more appropriate for comparing models with different numbers of predictors.
Neither nor adjusted should be your only criterion for model selection. You should also consider:
- Parsimony: Simpler models are preferred when they explain nearly as much variation.
- Practical significance: A statistically significant predictor might have a tiny real-world effect.
- Interpretability: A model you can explain and defend is often more useful than one that's marginally more accurate.

Regression Assumptions
Key Assumptions
The classical linear regression model relies on four core assumptions:
- Linearity: The expected value of the response is a linear function of the predictors. The model is .
- Independence: Observations are independently sampled, and the error terms are uncorrelated with each other.
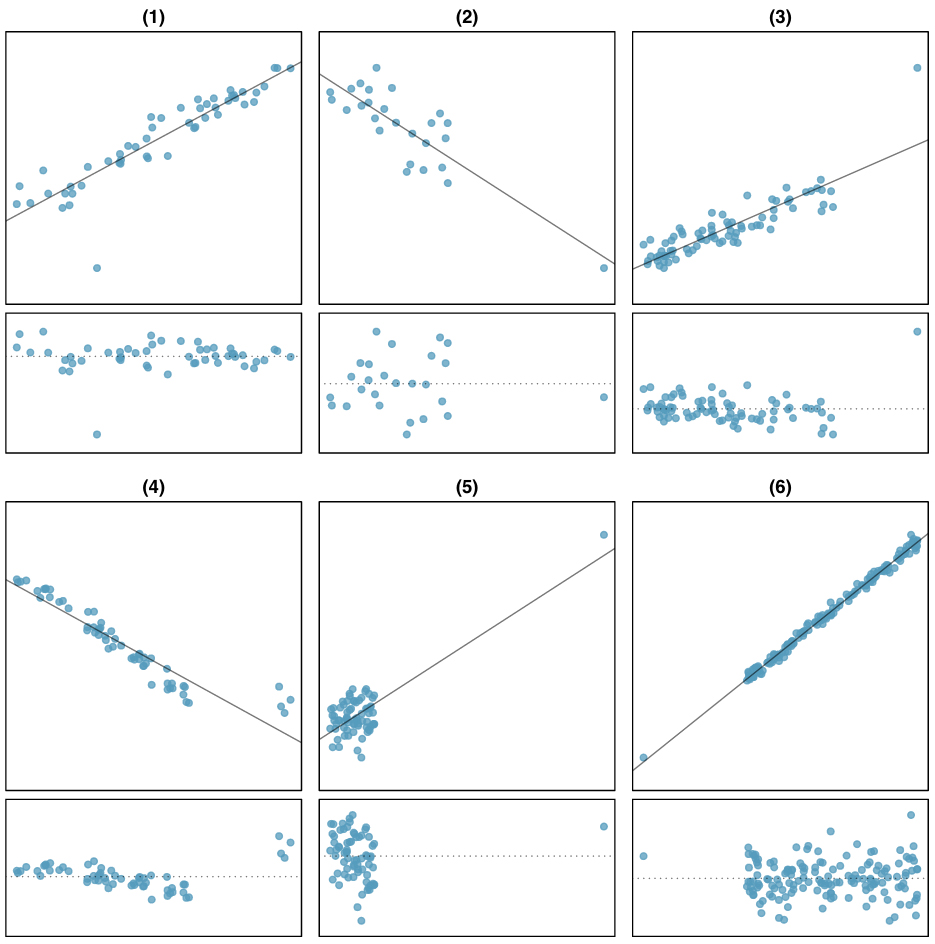
- Homoscedasticity: The variance of the errors is constant across all levels of the predictors. In other words, the spread of the residuals doesn't change as the fitted values change.
- Normality: The errors follow a normal distribution with mean zero and constant variance .
These assumptions are what guarantee the BLUE property and make the t-tests and confidence intervals valid.
Multicollinearity and Influential Observations
Multicollinearity occurs when predictors are highly correlated with each other. This doesn't bias the coefficient estimates, but it inflates their standard errors, making individual coefficients unstable and hard to interpret.
- Detect it using the Variance Inflation Factor (VIF). A common rule of thumb: VIF values above 5 or 10 signal problematic multicollinearity.
- You can also check the correlation matrix of the predictors for high pairwise correlations.
- Possible remedies: remove one of the correlated predictors, combine them into a single variable, or use regularization methods like ridge regression or lasso.
Outliers and influential observations can distort least squares estimates because the method squares the residuals, giving extra weight to points far from the fitted line.
- Outliers have unusually large residuals.
- Influential observations disproportionately affect the estimated coefficients or overall model fit. A point can be influential without being an outlier if it has high leverage (extreme predictor values).
- Use diagnostic tools like residual plots, leverage plots, Cook's distance, and DFFITS to identify these points.
Consequences of Assumption Violations
When assumptions break down, your estimates and inferences can become unreliable. Here's a quick reference for common violations and remedies:
- Non-linearity: Try variable transformations (log, polynomial) or switch to a non-linear model.
- Non-independence: Use robust standard errors or model the correlation structure directly (e.g., time series models for autocorrelated errors).
- Heteroscedasticity: Use weighted least squares (WLS) or heteroscedasticity-robust standard errors.
- Non-normality: With large samples, inference is often still approximately valid due to the Central Limit Theorem. For small samples, consider transforming the response variable or using robust regression methods.