Linear vs Non-linear Models
Assumptions and Relationships
Linear models assume that the relationship between predictors and the response variable can be expressed as a weighted sum of the predictors (plus an error term). The "linear" in linear model refers to linearity in the parameters, not necessarily in the predictors themselves. A polynomial regression like is still a linear model because the parameters enter linearly.
Non-linear models, by contrast, have parameters that enter the model in a non-linear way. Think of something like , where appears inside an exponential. These models can capture relationships that no linear-in-parameters specification can represent.
The choice between linear and non-linear models depends on:
- The nature of the underlying data-generating process
- How complex the relationship between predictors and response actually is
- Whether your goal is prediction, inference, or both
Simplicity and Interpretability
Linear models are simpler to estimate, interpret, and communicate. Each coefficient has a direct meaning: a one-unit change in is associated with a change in , holding other predictors constant. Estimation uses closed-form solutions (ordinary least squares), so computation is fast.
Non-linear models require iterative optimization algorithms (like Gauss-Newton or Levenberg-Marquardt), which are more computationally intensive and sensitive to starting values. Their parameters often lack the clean "one-unit change" interpretation that linear coefficients have.
A few practical trade-offs to keep in mind:
- Linear models tend to be more robust to outliers and less prone to overfitting
- Non-linear models are more flexible and can capture a wider range of patterns
- If a linear model fits the data well, adding non-linear complexity rarely pays off
Model Goodness-of-Fit
Goodness-of-Fit Measures
Goodness-of-fit measures quantify how well a model explains the observed data.
R-squared () measures the proportion of variance in the response variable explained by the model:
where is the residual sum of squares and is the total sum of squares. An of 0.85 means the model explains 85% of the variability in the response.
Adjusted R-squared corrects for the number of predictors by penalizing unnecessary complexity:
where is the number of observations and is the number of predictors. This is especially useful when comparing models with different numbers of parameters, because raw will never decrease when you add a predictor, even a useless one.
When comparing a linear and a non-linear model, be cautious with . For non-linear models estimated without an intercept or via maximum likelihood, the standard decomposition may not hold. Adjusted or information criteria are often more reliable comparison tools.
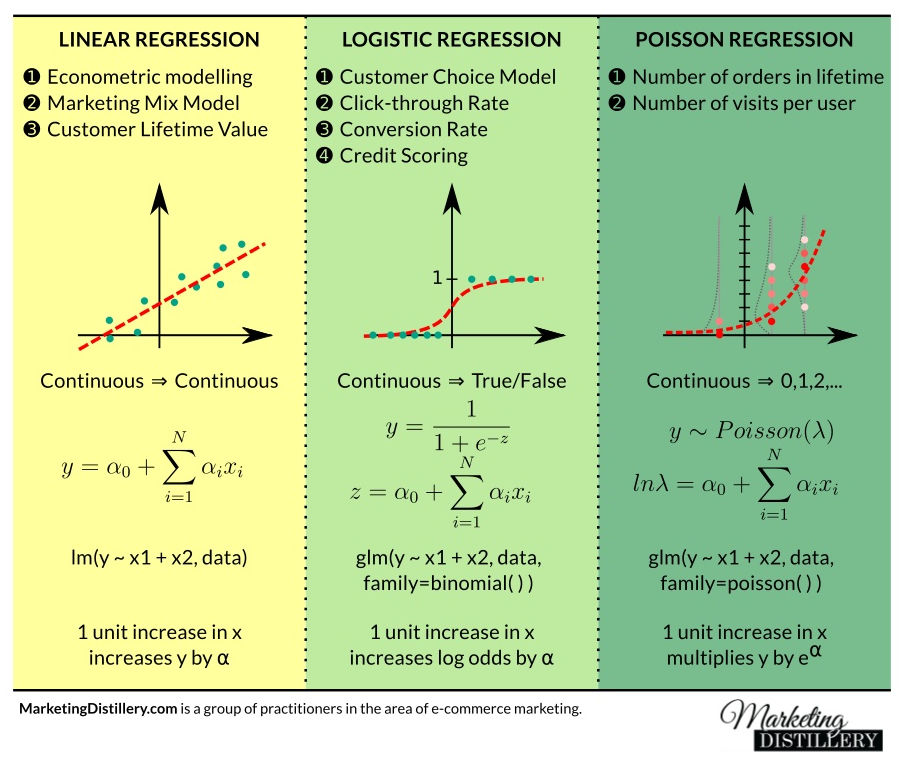
Predictive Performance Metrics
These metrics assess how well a model generalizes to new, unseen data, which is often more important than how well it fits the training data.
- Mean Squared Error (MSE): . Averages the squared prediction errors. Sensitive to large errors because squaring amplifies them.
- Root Mean Squared Error (RMSE): . Same units as the response variable, making it easier to interpret. If your response is in dollars, RMSE is also in dollars.
- Mean Absolute Error (MAE): . Less sensitive to outliers than MSE/RMSE because it doesn't square the errors.
When comparing a linear model to a non-linear alternative, compute these metrics on a held-out test set or via cross-validation. A non-linear model that achieves only marginally better RMSE than a linear model may not be worth the added complexity.
Cross-Validation and Bias-Variance Trade-off
Cross-validation estimates out-of-sample performance without requiring a separate test set.
K-fold cross-validation works in these steps:
- Split the data into roughly equal subsets (folds)
- For each fold , train the model on all data except fold
- Predict the response for the held-out fold and compute the error metric
- Average the error across all folds to get the cross-validated estimate
Common choices are or . Leave-one-out cross-validation (LOOCV) is the special case where , meaning each observation gets its own fold. LOOCV has low bias but can have high variance and is computationally expensive for large datasets.
The bias-variance trade-off is central to model comparison:
- Linear models tend to have higher bias (they may underfit complex patterns) but lower variance (their predictions are stable across different samples)
- Non-linear models tend to have lower bias (they can fit complex patterns) but higher variance (they're more sensitive to the specific training data)
The sweet spot depends on your data. With a small dataset, the variance penalty of a complex non-linear model often outweighs its bias advantage, and a simpler linear model generalizes better.
Complexity vs Interpretability
Model Complexity
Model complexity refers to the number of parameters and the flexibility of the functional form. A simple linear regression with one predictor has two parameters ( and ). A neural network might have thousands.
As complexity increases, the model can capture more intricate patterns. But there's a ceiling: once the model starts fitting noise rather than signal, you've overfit. An overfit model will look great on training data and perform poorly on new data. This is why training-set alone is a misleading guide for model selection.

Model Interpretability
Interpretability is how easily you can understand and communicate what the model is doing.
- In a linear model, you can say: "For every additional year of education, income increases by on average, holding other factors constant." That's a clear, actionable statement.
- In a complex non-linear model, the relationship between a predictor and the response may change depending on the values of other predictors, making such clean statements impossible.
When your audience includes decision-makers, regulators, or non-technical stakeholders, interpretability often matters as much as predictive accuracy.
Parsimony and Overfitting
The principle of parsimony (Occam's razor) says that among models with similar performance, prefer the simpler one. A simpler model is easier to interpret, more robust to new data, and less likely to have overfit.
This doesn't mean always choose the simplest model. It means complexity needs to earn its place by delivering meaningfully better performance. If a non-linear model reduces RMSE by 15% over a linear model on cross-validated data, that complexity is justified. If it reduces RMSE by 1%, it probably isn't.
Model Selection Techniques
Stepwise Selection Methods
Stepwise methods automate predictor selection by iteratively adding or removing variables based on statistical criteria (typically p-values or F-statistics).
- Forward selection: Start with no predictors. At each step, add the predictor that most improves the model (lowest p-value below a threshold). Stop when no remaining predictor meets the threshold.
- Backward elimination: Start with all candidate predictors. At each step, remove the predictor that contributes least (highest p-value above a threshold). Stop when all remaining predictors are significant.
- Stepwise regression: Combines both directions. After adding a predictor, check whether any previously included predictor should now be removed, and vice versa.
These methods are convenient but have well-known limitations: they can be unstable (small changes in data lead to different selected models), they inflate Type I error rates due to multiple testing, and they don't search all possible model subsets. Use them as exploratory tools, not as definitive model selectors.
Regularization Techniques
Regularization controls model complexity by adding a penalty term to the objective function, shrinking coefficients toward zero.
Ridge regression (L2) minimizes:
The penalty shrinks all coefficients toward zero but never sets them exactly to zero. Ridge is useful when you have many correlated predictors.
Lasso regression (L1) minimizes:
The absolute-value penalty can force some coefficients to exactly zero, effectively performing variable selection. This produces sparser, more interpretable models.
The tuning parameter controls the strength of the penalty. When , you get ordinary least squares. As increases, coefficients shrink more aggressively. The optimal is typically chosen via cross-validation.
Information Criteria and Cross-Validation
Information criteria provide a single number that balances fit and complexity, making model comparison straightforward.
- AIC (Akaike Information Criterion): , where is the number of parameters and is the maximized likelihood. Lower AIC is better.
- BIC (Bayesian Information Criterion): . BIC penalizes complexity more heavily than AIC (especially for large ), so it tends to favor simpler models.
AIC and BIC values are only meaningful in comparison to other models fit on the same data. An AIC of 342 by itself tells you nothing; an AIC of 342 vs. 358 for a competing model tells you the first model is preferred.
Cross-validation complements information criteria by directly estimating prediction error. When AIC/BIC and cross-validation agree on the best model, you can be fairly confident in your choice. When they disagree, cross-validation results are generally more trustworthy for prediction-focused problems, while BIC is often preferred when the goal is identifying the "true" model.
The right selection technique depends on your dataset size, the number of candidate models, and whether your priority is prediction or interpretation.