📡Advanced Signal Processing Unit 7 Review
7.1 Probability and random variables
7.1 Probability and random variables
Unit & Topic Study Guides
Fourier Analysis and Transforms
Digital Signal Processing Basics
Spectral Estimation and Analysis
Adaptive Filtering & Signal Enhancement
Multirate Processing & Filter Banks
Time-Frequency and Scale Analysis in ASP
Statistical Signal Processing & Estimation
Compressive Sensing & Sparse Signal Processing
Array Processing and Beamforming
Machine Learning in Signal Processing
Signal Processing for Comms and Networks
Biomedical Signal Processing Applications
Probability and random variables form the backbone of statistical signal processing. They provide the mathematical framework for analyzing signals with unpredictable components, letting you model noise, interference, and other stochastic phenomena that show up in real-world data.
This section covers probability theory foundations, types of random variables and their distributions, expectation and moments, and multivariate random variables.
Probability theory foundations
Probability theory gives you the formal tools to reason about uncertainty. In signal processing, signals are almost always corrupted by noise or other random effects, so you need a rigorous way to describe and manipulate randomness before you can build estimators, detectors, or filters.
Experiments, sample spaces and events
- An experiment is any procedure whose outcome is determined by chance (transmitting a bit over a noisy channel, measuring a voltage).
- The sample space is the set of all possible outcomes of that experiment.
- An event is a subset of . For example, if you roll a die, the event "even number" is the subset .
Axioms of probability
All of probability is built on three axioms (Kolmogorov's axioms):
- Non-negativity: for any event .
- Normalization: .
- Countable additivity: For mutually exclusive events ,
Every probability rule you'll use downstream (complement rule, inclusion-exclusion, etc.) derives from these three.
Conditional probability
Conditional probability captures how the probability of event changes once you know event has occurred:
This is central to signal processing. For instance, you might want the probability that a transmitted symbol was "1" given a particular received voltage. Conditioning on observed data is the starting point for all Bayesian estimation.
Statistical independence
Two events and are statistically independent if knowing one tells you nothing about the other. The formal condition is:
Equivalently, . Independence is a powerful simplifying assumption. In many signal processing models, noise samples are assumed independent of the signal and of each other, which makes joint probabilities factor into products.
Bayes' theorem applications
Bayes' theorem lets you invert a conditional probability:
- is the prior (what you believed before observing data).
- is the likelihood (how probable the observed data is under hypothesis ).
- is the posterior (your updated belief after seeing data).
In signal processing, Bayes' theorem underpins MAP and MMSE estimation, hypothesis testing, and signal detection in noise.
Random variables
A random variable is a function that maps each outcome in to a real number. It bridges the abstract sample space and the numerical quantities you actually compute with. Virtually every signal processing model represents signals, noise, and parameters as random variables.
Discrete vs continuous types
- Discrete random variables take on a countable set of values (e.g., the number of bit errors in a packet).
- Continuous random variables can take any value in an interval (e.g., the amplitude of thermal noise).
The distinction matters because discrete variables use sums and PMFs, while continuous variables use integrals and PDFs.
Probability mass functions (PMFs)
For a discrete random variable , the PMF gives the probability that equals :
Two requirements: for all , and . You use the PMF to compute expectations, probabilities of events, and other statistics for discrete quantities.
Cumulative distribution functions (CDFs)
The CDF works for both discrete and continuous random variables:
- Discrete case:
- Continuous case:
The CDF is always non-decreasing, right-continuous, and satisfies and . It's especially useful for computing probabilities like .
Probability density functions (PDFs)
For a continuous random variable , the PDF is the derivative of the CDF:
The PDF itself is not a probability (it can exceed 1), but integrating it over an interval gives a probability:
Requirements: and .
Joint probability distributions
When you have two or more random variables, their joint distribution describes their simultaneous behavior.
- Discrete: joint PMF
- Continuous: joint PDF , where
Joint distributions are essential for studying how signal components relate to each other, such as the in-phase and quadrature components of a complex baseband signal.
Expectation and moments
Moments summarize the shape of a distribution with a few numbers. The mean tells you where the distribution is centered, the variance tells you how spread out it is, and higher moments capture asymmetry and tail behavior.
Expected value of a random variable
The expected value (mean) of is:
- Discrete:
- Continuous:
The expected value is linear: , regardless of whether and are independent. This linearity property is used constantly in signal processing derivations.
Variance and standard deviation
Variance measures dispersion around the mean:
The second form is often easier to compute. The standard deviation has the same units as , making it more interpretable. In signal processing, variance of noise directly determines signal-to-noise ratio.
Moments and moment-generating functions
The -th moment of is . The -th central moment is . The first moment is the mean; the second central moment is the variance.
The moment-generating function (MGF) compactly encodes all moments:
You recover moments by differentiation: . The MGF uniquely determines the distribution (when it exists in a neighborhood of ), and it's particularly convenient for finding the distribution of sums of independent random variables since .
Characteristic functions
The characteristic function (CF) is the Fourier-domain counterpart of the MGF:
Unlike the MGF, the CF always exists. It uniquely determines the distribution and shares the multiplication property for sums of independent variables. If you're comfortable with Fourier transforms from earlier signal processing courses, the CF will feel natural: it is the Fourier transform of the PDF.
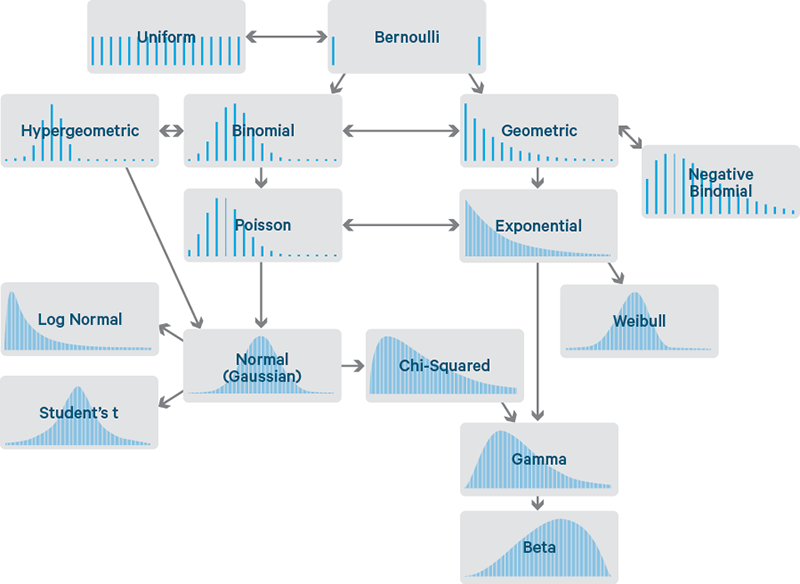
Common discrete distributions
Bernoulli and binomial distributions
A Bernoulli random variable models a single trial: success () with probability , failure () with probability . Mean: . Variance: .
The binomial distribution counts the number of successes in independent Bernoulli trials:
Mean: . Variance: . A typical application is counting bit errors in a block of transmitted bits, each with independent error probability .
Poisson distribution
The Poisson distribution models the count of events in a fixed interval when events occur independently at a constant average rate :
Mean and variance are both . The Poisson distribution also arises as the limit of the binomial when is large and is small with . It's commonly used to model photon counts in optical systems or packet arrivals in networks.
Geometric and negative binomial distributions
The geometric distribution models the number of trials until the first success:
Mean: . Variance: . The geometric distribution is memoryless: .
The negative binomial distribution generalizes this to the number of trials needed for successes. It reduces to the geometric when .
Hypergeometric distribution
The hypergeometric distribution models successes in draws without replacement from a finite population:
where is the population size, is the number of success items, and is the number of draws. Unlike the binomial, trials are dependent because there's no replacement. As with fixed, the hypergeometric converges to the binomial.
Common continuous distributions

Uniform distribution
The uniform distribution on assigns equal density to every point in the interval:
Mean: . Variance: . A common signal processing example: the phase of a carrier with unknown offset is often modeled as uniform on .
Exponential and gamma distributions
The exponential distribution models the waiting time between events in a Poisson process with rate :
Mean: . Variance: . Like the geometric distribution, the exponential is memoryless: .
The gamma distribution with shape and rate generalizes the exponential. It models the waiting time until the -th event in a Poisson process. The exponential is the special case .
Normal (Gaussian) distribution
The Gaussian distribution is the most important distribution in signal processing. Its PDF is:
with mean and variance . Why is it so central?
- Thermal noise in electronic circuits is well-modeled as Gaussian.
- The Central Limit Theorem guarantees that sums of many independent random effects converge to a Gaussian.
- Gaussian distributions are analytically tractable: linear operations on Gaussian variables produce Gaussian variables, and the Gaussian maximizes entropy for a given mean and variance.
The standard normal has and , often denoted .
Beta distribution
The beta distribution is defined on with shape parameters and :
where is the beta function. It's flexible enough to model a wide range of shapes on the unit interval, making it useful as a prior distribution for probabilities in Bayesian estimation.
Chi-square, t, and F distributions
These three distributions arise naturally in statistical inference with Gaussian data:
- Chi-square (): the sum of squares of independent standard normal variables. Used in power spectral analysis and goodness-of-fit tests.
- Student's t (): arises when estimating the mean of a Gaussian population with unknown variance. Heavier tails than the Gaussian; converges to as .
- F-distribution (): the ratio of two independent chi-square variables (each divided by its degrees of freedom). Used in comparing variances and in ANOVA-based signal detection.
Multivariate random variables
Many signal processing problems involve vectors of random variables (e.g., samples of a received signal, array sensor outputs). Multivariate analysis extends single-variable concepts to this vector setting.
Joint probability density functions
For continuous random variables and , the joint PDF satisfies:
This extends to variables with an -fold integral. The joint PDF fully specifies the probabilistic relationship among the variables.
Marginal and conditional distributions
Marginal PDF: Integrate out the variables you don't care about:
Conditional PDF: The distribution of given a specific observed value of :
This is the continuous analog of Bayes' theorem and is the foundation of conditional mean estimators (like the MMSE estimator).
Covariance and correlation coefficient
Covariance measures linear dependence between two random variables:
The correlation coefficient normalizes covariance to :
- : perfect linear relationship.
- : uncorrelated (no linear dependence, but nonlinear dependence may still exist).
For jointly Gaussian variables, uncorrelated does imply independent. This special property is one reason Gaussian models are so convenient.
Linear combinations of random variables
For :
If and are independent, the covariance term drops out. This result generalizes to vectors: for , the covariance matrix transforms as . You'll use this constantly when analyzing linear filters applied to random signals.
Central limit theorem
The Central Limit Theorem (CLT) states that the sum of independent, identically distributed (i.i.d.) random variables, each with mean and variance , converges in distribution to a Gaussian as :
The CLT is the reason Gaussian noise models are so prevalent: any noise process that results from the superposition of many small, independent contributions will be approximately Gaussian, regardless of the distribution of each individual contribution. In practice, the approximation is often quite good for .