📡Advanced Signal Processing Unit 7 Review
7.4 Maximum likelihood estimation (MLE)
7.4 Maximum likelihood estimation (MLE)
Unit & Topic Study Guides
Fourier Analysis and Transforms
Digital Signal Processing Basics
Spectral Estimation and Analysis
Adaptive Filtering & Signal Enhancement
Multirate Processing & Filter Banks
Time-Frequency and Scale Analysis in ASP
Statistical Signal Processing & Estimation
Compressive Sensing & Sparse Signal Processing
Array Processing and Beamforming
Machine Learning in Signal Processing
Signal Processing for Comms and Networks
Biomedical Signal Processing Applications
Basics of Maximum Likelihood Estimation
Maximum likelihood estimation (MLE) is a method for estimating the parameters of a probability distribution by finding the parameter values that make the observed data most probable. In signal processing, MLE is the go-to framework for extracting unknown quantities from noisy observations, whether you're estimating a carrier frequency, detecting a radar pulse, or classifying a modulation scheme.
The core idea: given a parametric model for your data, construct a function that scores how "likely" each candidate parameter value is, then pick the value that scores highest.
Definition
Given observed data and a parametric family of distributions , the MLE is defined as:
The function , viewed as a function of with fixed, is the likelihood function. Note the subtle but important shift: the density is the same mathematical expression, but now the data are fixed and the parameters vary.
Principles
MLE rests on a straightforward principle: the parameter value that would have generated the observed data with highest probability is the best estimate. To carry this out:
- Write down the joint density (or mass function) of the data given the parameters.
- Treat that expression as a function of the parameters alone.
- Find the parameters that maximize it.
In practice, you almost always work with the log-likelihood instead (covered below), because products turn into sums and the calculus becomes much cleaner.
Assumptions
- The observations are independently and identically distributed (i.i.d.) according to the assumed model. This lets you write the joint likelihood as a product of marginals.
- The parametric form of the distribution is known; only the parameter values are unknown.
- The model is correctly specified, meaning the true data-generating process actually belongs to the assumed family. When this assumption breaks, MLE can still work reasonably well, but its optimality guarantees weaken.
MLE for Parameter Estimation
Single-Parameter Case
For a single unknown parameter , the procedure is direct. Suppose you observe i.i.d. samples from an exponential distribution with unknown rate . The likelihood is:
Taking the log, differentiating with respect to , and setting the result to zero gives , which is just the reciprocal of the sample mean.
Multiple-Parameter Case
When the model has a parameter vector , you maximize the likelihood jointly over all parameters. This means setting the gradient of the log-likelihood to zero:
This yields a system of equations (the score equations) that must be solved simultaneously. For a Gaussian model with unknown mean and variance , for instance, you get the familiar sample mean and sample variance as the joint MLEs.
Properties of MLE Estimators
Three properties make MLE especially attractive for signal processing:
- Consistency: as . With enough data, the estimate converges to the true value.
- Asymptotic efficiency: For large , the MLE achieves the Cramér-Rao lower bound (CRLB). No unbiased estimator can have lower variance in the asymptotic regime.
- Invariance: If is the MLE of , then is the MLE of for any function . This is useful when you estimate one parameterization but need another (e.g., estimating variance but reporting standard deviation).
A common pitfall: MLE is not necessarily unbiased for finite samples. The classic example is the Gaussian variance estimate, which has a bias factor of .
Derivation of MLE
Likelihood Function
For i.i.d. observations , the likelihood factors as:
This product form is a direct consequence of the independence assumption. Each factor scores how well the candidate explains a single observation.
Log-Likelihood Function
Taking the natural logarithm converts the product into a sum:
Because is strictly monotonically increasing, maximizing is equivalent to maximizing . The log-likelihood is almost always preferred because:
- Sums are numerically more stable than products of many small probabilities.
- Exponential-family distributions yield log-likelihoods that are polynomial in the parameters, making differentiation straightforward.
Solving the MLE Equations
Step-by-step procedure for finding the MLE:
- Write the log-likelihood .
- Compute the partial derivatives for each parameter.
- Set all partial derivatives to zero (the score equations).
- Solve the resulting system of equations for .
- Verify that the solution is a maximum (not a minimum or saddle point) by checking the second-order conditions: the Hessian matrix of should be negative definite at the solution.
When the score equations have a closed-form solution, you're done analytically. When they don't, you turn to numerical methods (see below).
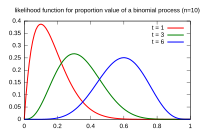
MLE in Signal Processing Applications
Signal Detection
In binary hypothesis testing, you observe and decide between (noise only) and (signal plus noise). The generalized likelihood ratio test (GLRT) uses MLE when the signal parameters are unknown:
You first compute the MLE of the unknown parameters under , plug them back into the likelihood, and compare the ratio to a threshold . This is the standard approach when a pure Neyman-Pearson test isn't available because of unknown parameters.
Signal Parameter Estimation
Estimating parameters like amplitude, frequency, or time delay from noisy observations is a natural MLE problem. For a sinusoid in additive white Gaussian noise (AWGN):
The MLE of frequency reduces to finding the peak of the periodogram (the squared magnitude of the DFT). The MLE of amplitude and phase then follow in closed form once is fixed. This is a good example of how MLE connects to classical spectral analysis.
Signal Classification
For classifying a received signal into one of classes, MLE assigns the observation to the class with the highest likelihood:
This is equivalent to the maximum likelihood classifier. When class priors are equal, it coincides with the MAP (maximum a posteriori) classifier.
Advantages and Limitations of MLE
Advantages
- Asymptotic optimality: Achieves the CRLB for large sample sizes, so you can't do better in terms of variance.
- Invariance: Reparameterize freely without re-deriving the estimator.
- Unified framework: The same methodology applies whether you're estimating one parameter or fifty, for Gaussian or non-Gaussian models.
Limitations
- Model dependence: If the assumed distribution is wrong, the MLE may be biased or inconsistent. There's no free lunch.
- Sensitivity to outliers: Because MLE maximizes the likelihood of all observations, a few extreme outliers can pull the estimate significantly.
- No closed-form solution in many cases: Complex signal models often require iterative numerical optimization, which introduces concerns about convergence and computational cost.
- Finite-sample bias: The asymptotic guarantees don't always hold for small . For short data records (common in radar or communications), MLE performance can fall well short of the CRLB.
MLE vs. Other Estimation Methods
| Method | When to prefer it |
|---|---|
| MLE | Distribution known, large sample size, no strong prior information |
| Least Squares | Linear models, Gaussian noise (where it coincides with MLE), or when you want to avoid distributional assumptions |
| Method of Moments | Quick initial estimates; useful as starting points for iterative MLE |
| Bayesian (MAP/MMSE) | Prior information available; small sample sizes where regularization helps |
In signal processing, Bayesian methods and MLE are often used together: MLE provides the likelihood model, and Bayesian inference adds prior knowledge to improve performance in low-SNR or data-starved scenarios.
Numerical Methods for MLE
When the score equations can't be solved in closed form, you need iterative algorithms.
Newton-Raphson Method
Newton-Raphson uses both the gradient and curvature of the log-likelihood to take intelligent steps toward the maximum:
where is the Hessian matrix of second partial derivatives. This converges quadratically near the solution, but it requires computing and inverting the Hessian at each step, which can be expensive for high-dimensional problems.
A common variant replaces the Hessian with its expected value (the negative Fisher information matrix), giving the Fisher scoring algorithm. This is often more stable because the Fisher information matrix is guaranteed to be positive semi-definite.
Expectation-Maximization (EM) Algorithm
The EM algorithm handles MLE when the data are incomplete or when latent variables are present (e.g., mixture models, hidden Markov models). It iterates between two steps:
-
E-step: Compute the expected log-likelihood of the complete data, using the current parameter estimates and the observed data: where represents the latent/missing data.
-
M-step: Maximize with respect to :
EM is guaranteed to increase the likelihood at each iteration (or leave it unchanged), so it never diverges. The trade-off is that convergence can be slow, and it only guarantees convergence to a local maximum.

Gradient-Based Optimization
Gradient ascent updates parameters in the direction of steepest increase:
where is the step size (learning rate). This is simpler than Newton-Raphson since it avoids the Hessian, but convergence is only linear and can be sensitive to the choice of .
For large-scale problems (large or streaming data), stochastic gradient ascent approximates the full gradient using a subset of the data at each step, trading per-iteration accuracy for computational speed.
Advanced Topics in MLE
Constrained MLE
When parameters must satisfy constraints (e.g., a covariance matrix must be positive definite, or probabilities must sum to one), you solve a constrained optimization problem. Standard approaches include:
- Lagrange multipliers for equality constraints
- Barrier/interior-point methods for inequality constraints
- Reparameterization to eliminate constraints (e.g., optimizing over the Cholesky factor of a covariance matrix instead of the matrix itself)
MLE with Missing Data
Missing data arise frequently in sensor networks (dropped packets), array processing (failed elements), and spectral analysis (non-uniform sampling). The EM algorithm is the standard tool here, treating the missing observations as latent variables and iterating between imputation (E-step) and estimation (M-step).
MLE for Non-Linear Models
Many signal processing models are non-linear in the parameters (e.g., estimating time delays, Doppler shifts, or directions of arrival). The log-likelihood surface for these problems is often multimodal, so:
- Global search methods (grid search, genetic algorithms) may be needed to find a good initialization.
- Local refinement via Gauss-Newton or Levenberg-Marquardt then converges to the nearest peak.
- The computational cost scales with the dimensionality of the parameter space and the number of local optima.
MAP Estimation and Its Relation to MLE
Maximum a posteriori (MAP) estimation incorporates prior information through Bayes' theorem:
MAP reduces to MLE when the prior is uniform (non-informative). In signal processing, MAP is useful when you have physical constraints or prior measurements that should influence the estimate. The prior acts as a regularizer, which can prevent overfitting and improve performance at low SNR.
Practical Considerations
Choice of Initial Values
Iterative MLE algorithms are sensitive to initialization. Strategies that work well in practice:
- Use method of moments estimates as a starting point.
- Perform a coarse grid search over the parameter space to identify the region of the global maximum.
- Run the algorithm from multiple random initializations and keep the solution with the highest log-likelihood.
- Exploit problem structure: for frequency estimation, the FFT peak gives a good initial frequency; for mixture models, k-means clustering provides initial component assignments.
Assessing Convergence
Monitor convergence by tracking the log-likelihood value across iterations. Common stopping criteria:
- The change in log-likelihood falls below a threshold:
- The change in parameter estimates falls below a threshold:
- A maximum number of iterations is reached (as a safety net)
If the log-likelihood decreases at any iteration (for Newton-Raphson or gradient methods), the step size is too large or the Hessian approximation is poor.
Computational Complexity
The cost per iteration depends on the algorithm and model:
- Newton-Raphson: per iteration due to Hessian inversion, where is the number of parameters.
- Gradient ascent: per iteration for computing the gradient over data points.
- EM: Depends heavily on the model; the E-step can be the bottleneck for complex latent-variable models.
For real-time signal processing, computational budget often dictates the choice of algorithm. Approximate or online MLE methods trade statistical efficiency for speed.
Robustness
MLE estimators can break down when the model assumptions are violated. To guard against this:
- Use robust alternatives like M-estimators, which replace the log-likelihood with a less outlier-sensitive loss function (e.g., Huber's loss).
- Apply goodness-of-fit tests (Kolmogorov-Smirnov, chi-squared) to check whether the assumed distribution fits the data.
- Consider model selection criteria (AIC, BIC) to choose among competing models, balancing fit quality against model complexity.