🧬Molecular Biology Unit 6 Review
6.1 The genetic code and its properties
6.1 The genetic code and its properties
Unit & Topic Study Guides
Introduction to Molecular Biology
Chemical Foundations of Molecular Biology
Nucleic Acids
DNA Replication and Repair
Transcription and RNA Processing
Translation and Protein Synthesis
Gene Regulation
Molecular Techniques and Tools
Genomics and Bioinformatics
Molecular Evolution and Phylogenetics
Molecular Basis of Disease
The genetic code is the blueprint for protein synthesis, translating DNA into amino acids. It's based on three-letter codons, each specifying an amino acid or signaling the start or end of translation. This universal language of life is crucial for understanding how genes become proteins.
Degeneracy and universality are key features of the genetic code. Multiple codons can code for the same amino acid, providing genetic flexibility. The code is largely consistent across organisms, with some exceptions, supporting the idea of a common ancestor for all life on Earth.
Features of the Genetic Code
Fundamental Principles of the Genetic Code
- Defines translation of nucleotide sequences into amino acid sequences for protein synthesis
- Based on nucleotide triplets called codons specifying particular amino acids or stop signals
- Non-overlapping structure ensures each nucleotide belongs to only one codon
- Unambiguous nature allows each codon to specify only one amino acid or stop signal
- Continuous reading from a fixed starting point without punctuation between codons
- Redundant (degenerate) design allows multiple codons to code for the same amino acid
- Provides buffer against some types of mutations
- Variations in third base often do not alter specified amino acid
- Universal across most living organisms with few exceptions
- Supports theory of common ancestor for all life on Earth
- Exceptions include mitochondria and certain microorganisms with slight codon assignment variations
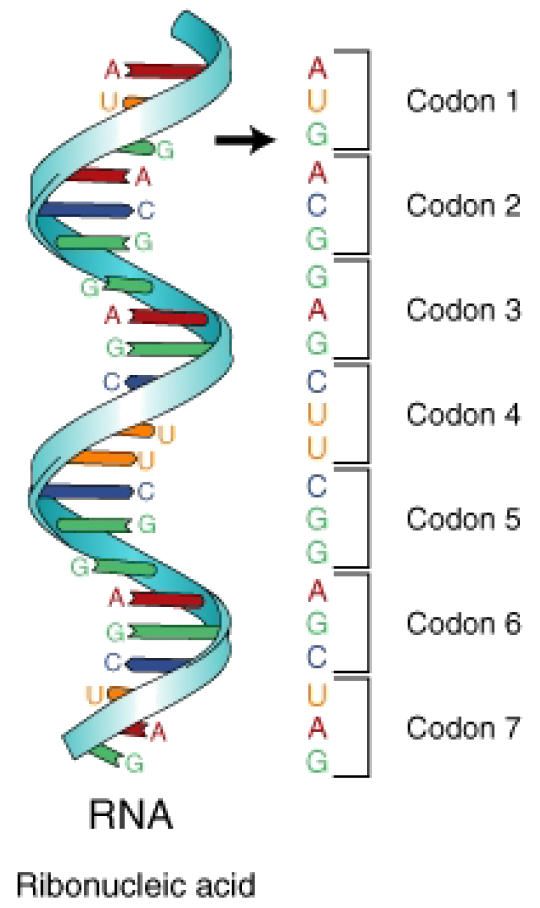
Codon Composition and Structure
- 64 possible codons in standard genetic code
- Formed by combinations of four nucleotide bases (A, U, C, G) in groups of three
- 61 codons code for amino acids
- Three stop codons (UAA, UAG, UGA) signal translation termination
- AUG serves dual role as start codon and methionine codon
Codons and Amino Acids
Codon-Amino Acid Relationship
- Three-nucleotide mRNA sequences correspond to specific amino acids or stop signals
- Mediated by transfer RNA (tRNA) molecules during protein synthesis
- tRNAs possess anticodons complementary to codons
- Each tRNA carries a specific amino acid
- Codon-anticodon interaction occurs in ribosome during translation
- Ensures correct amino acid addition to growing polypeptide chain
- Most amino acids encoded by multiple codons (degenerate code)
- Methionine and tryptophan exceptions with one codon each
- Tyrosine encoded by two codons
- Leucine, serine, and arginine encoded by up to six codons
Role of tRNA in Translation
- Acts as adapter molecule between mRNA and amino acids
- Specific aminoacyl-tRNA synthetases attach correct amino acids to corresponding tRNAs
- Anticodon loop of tRNA base-pairs with mRNA codon in ribosome
- Delivers amino acid to growing polypeptide chain
- Wobble base pairing allows some tRNAs to recognize multiple codons
- Increases efficiency of translation process
Degeneracy and Universality of the Genetic Code

Degeneracy of the Genetic Code
- Multiple codons can specify the same amino acid
- Varying levels of degeneracy among amino acids
- Two codons (tyrosine)
- Four codons (valine, threonine, alanine, glycine)
- Six codons (leucine, serine, arginine)
- Third base often less critical in determining amino acid (wobble hypothesis)
- Provides genetic flexibility and resistance to certain mutations
- Allows for codon bias in different organisms or tissues
- Preference for specific codons among synonymous options
- Can affect translation efficiency and protein folding
Universality of the Genetic Code
- Conserved across most living organisms from bacteria to humans
- Enables horizontal gene transfer between different species
- Allows for expression of genes from one organism in another (recombinant DNA technology)
- Exceptions to universality exist
- Mitochondrial genetic code variations
- Alternative nuclear genetic codes in certain protozoans and fungi
- Implications for evolutionary biology and biotechnology
- Supports endosymbiotic theory for mitochondrial origin
- Challenges in expressing genes across species with different genetic codes
Start and Stop Codons in Protein Synthesis
Function of Start Codons
- AUG initiates protein synthesis
- Codes for methionine in eukaryotes or formylmethionine in prokaryotes
- Establishes reading frame for entire mRNA sequence
- Ensures correct translation of genetic information
- Eukaryotic ribosomes scan mRNA from 5' end until encountering first AUG in appropriate context
- Kozak sequence influences start codon recognition efficiency
- Alternative start codons (GUG, UUG) occasionally used in prokaryotes
- Less efficient than AUG, still translate as methionine
Role of Stop Codons in Translation Termination
- Three stop codons (UAA, UAG, UGA) signal end of protein synthesis
- Do not code for any amino acid
- Trigger binding of release factors when entering ribosome A site
- Release factors initiate translation termination process
- Prevent synthesis of excessively long or non-functional proteins
- Mutations affecting stop codons can have significant consequences
- Premature stop codons lead to truncated proteins
- Read-through mutations result in extended proteins
- Can cause genetic disorders (cystic fibrosis, Duchenne muscular dystrophy)
- Suppressor tRNAs can sometimes read through stop codons
- Natural occurrence in some organisms
- Utilized in certain biotechnology applications