Binary Search Tree (BST) Implementation and Analysis
Binary Search Trees (BSTs) organize data in a hierarchical structure that enables efficient searching, insertion, and deletion. Each node has at most two children, with the left subtree containing smaller values and the right subtree containing larger values. This ordering property is what makes BSTs powerful: you can eliminate half the remaining nodes at each step, much like binary search on a sorted array.
BST operations run in time when the tree is balanced, but can degrade to when the tree becomes skewed. Understanding why that happens and how to implement BST operations correctly is central to this unit.
Implementation of BST
A BST is built from nodes, and the tree itself is managed by a class that holds a reference to the root.
Node structure:
- Key stores the node's value (integer, string, or any comparable data type)
- Left pointer references the left child (values smaller than the key)
- Right pointer references the right child (values larger than the key)
BST class:
- Root is a pointer to the root node of the tree. An empty tree has a null root.
Insert Operation
Insertion places a new key in the correct position so the BST property is preserved.
- Start at the root.
- Compare the new key to the current node's key.
- If the new key is less, move to the left child. If greater, move to the right child.
- Repeat until you reach a null pointer.
- Create a new node and attach it at that null position.
For example, inserting 5 into a BST with root 8 and left child 3: you compare 5 to 8 (go left), then compare 5 to 3 (go right), and 3's right child is null, so 5 becomes 3's right child.
Search Operation
Searching follows the same traversal logic as insertion.
- Start at the root.
- Compare the target key to the current node's key.
- If they match, return the node.
- If the target is less, move left. If greater, move right.
- If you reach a null pointer, the key is not in the tree. Return null.
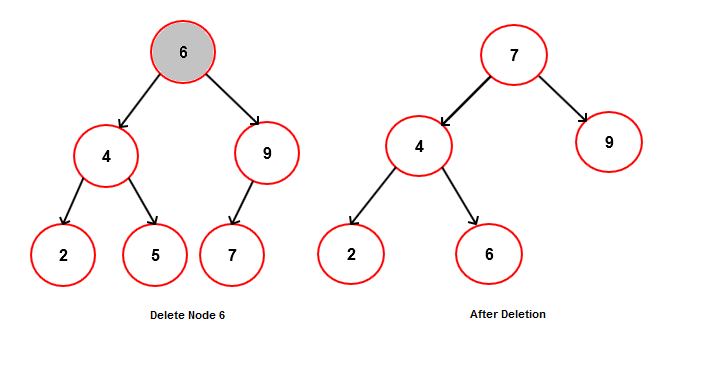
Delete Operation
Deletion is the trickiest operation because removing a node must preserve the BST property. There are three cases:
- No children (leaf node): Simply remove the node by setting its parent's pointer to null.
- One child: Replace the node with its single child by updating the parent's pointer to skip over the deleted node.
- Two children: Find the inorder successor (the smallest node in the right subtree). Copy the successor's key into the node being deleted, then delete the successor node. The successor is guaranteed to have at most one child (no left child), so deleting it falls into case 1 or 2.
The inorder successor works because it's the next-largest value in the tree, so swapping it in preserves the BST ordering. You could also use the inorder predecessor (largest node in the left subtree) with the same logic.
Complexity Analysis of BST Operations
Time complexity:
All three core operations (insert, search, delete) have a time complexity of , where is the height of the tree. The height determines how many comparisons you make in the worst case.
- Balanced BST: , so operations run in . A tree with 1,000,000 nodes would need at most ~20 comparisons.
- Skewed BST: , so operations run in . This happens when you insert already-sorted data (e.g., 1, 2, 3, 4, 5), which produces a tree that looks like a linked list.
Space complexity:
- Storing the tree itself requires space for nodes.
- Recursive implementations add space on the call stack. In a skewed tree, that's stack frames, which could cause a stack overflow for large inputs. Iterative implementations avoid this overhead.
BST vs Other Data Structures
Arrays and linked lists:
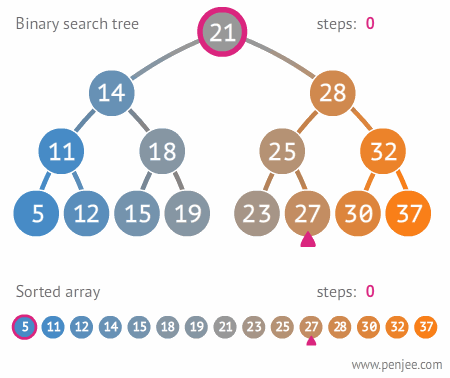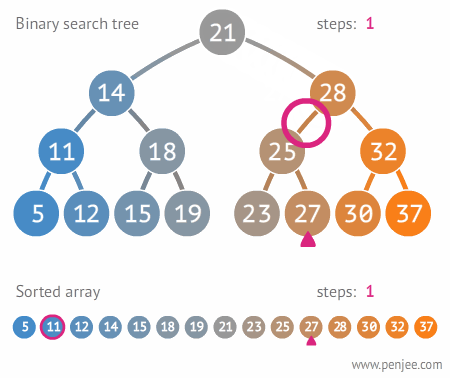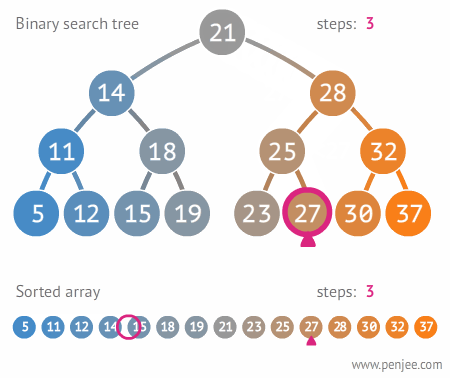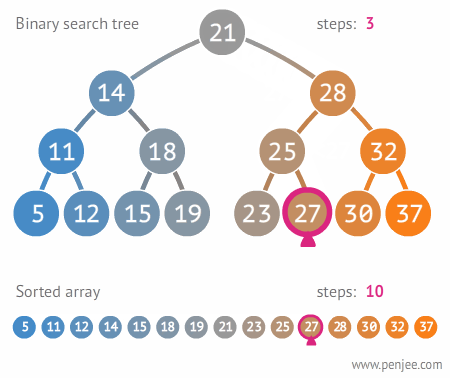
- Searching an unsorted array or linked list takes . A balanced BST cuts that to .
- Insertion at the end of an array or linked list is , but inserting in sorted order costs for arrays (shifting elements). BSTs handle sorted insertion naturally.
- BSTs use more memory per element than arrays because each node stores two pointers in addition to the key.
Hash tables:
- Hash tables offer average time for search, insert, and delete, which is faster than a BST's .
- However, BSTs maintain key ordering. You can do an inorder traversal to get all elements in sorted order, or efficiently answer range queries (e.g., "find all keys between 10 and 50"). Hash tables cannot do this.
Balanced BSTs (AVL trees, Red-Black trees):
- These are BSTs with extra rules that prevent skewing. They guarantee for all operations, eliminating the worst-case problem.
- The tradeoff is added complexity: AVL trees store a balance factor at each node and perform rotations on insert/delete. Red-Black trees store a color bit and have their own rebalancing rules. Both use slightly more space and time per operation to maintain balance.
Advantages and Disadvantages of BSTs
Advantages:
- average-case search, insert, and delete, which is much better than the of arrays and linked lists
- Elements stay ordered by key, enabling inorder traversal (sorted output), range queries, and efficient min/max lookups
- Dynamic size with no need to pre-allocate memory like arrays
Disadvantages:
- Performance depends entirely on tree shape. Inserting sorted data without balancing produces operations, which is no better than a linked list.
- Slower than hash tables when you don't need ordering
- Higher memory overhead than arrays due to storing two pointers per node
When to use a BST:
- You need data in sorted order (e.g., maintaining a sorted list of usernames)
- You need range queries (e.g., finding all students with grades between 80 and 90)
- You need efficient min/max lookups (e.g., a priority-based system)
- You need a symbol table where ordered iteration matters (e.g., a compiler's symbol table)
When to consider alternatives:
- Order doesn't matter and you want the fastest lookups possible: use a hash table (e.g., implementing a cache or dictionary)
- Data is static and won't change: use a sorted array with binary search, which avoids pointer overhead
- You need guaranteed and can't risk skewed input: use a balanced BST like an AVL tree or Red-Black tree