Supervised learning techniques are the backbone of predictive modeling in data mining and machine learning. These methods use labeled data to train algorithms, enabling them to make accurate predictions on new, unseen information.
From linear regression to support vector machines, supervised learning offers a range of tools for tackling classification and regression problems. Understanding these techniques is crucial for anyone looking to harness the power of data-driven decision-making in business and beyond.
Supervised Learning Concepts
Definition and Goal
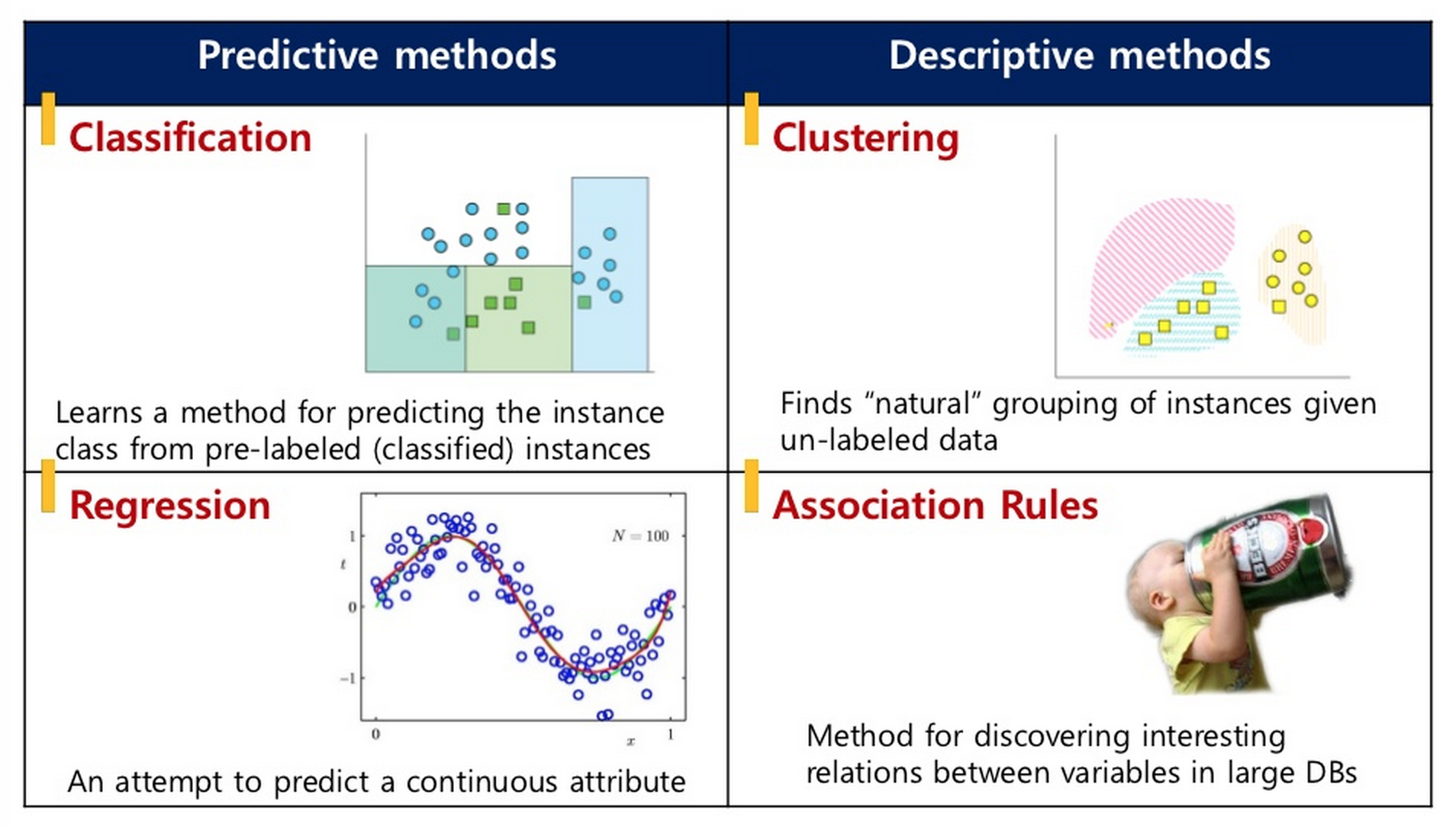
- Supervised learning is a type of machine learning where the algorithm learns from labeled training data to make predictions or decisions on new, unseen data
- The training data consists of input features (X) and corresponding output labels (y)
- The goal is to learn a mapping function f(X) that can predict the correct output for new input data
Applications and Evaluation
- Supervised learning is commonly used for tasks such as:
- Classification (predicting categorical labels such as spam email detection, image classification, sentiment analysis)
- Regression (predicting continuous values such as stock price prediction, customer churn prediction)
- The performance of supervised learning models is typically evaluated using metrics depending on the type of problem:
- Classification metrics: accuracy, precision, recall, F1-score
- Regression metrics: mean squared error, mean absolute error, R-squared
Linear Regression for Prediction
Overview and Equation
- Linear regression is a supervised learning algorithm used for predicting continuous target variables based on one or more input features
- The goal is to find the best-fitting line that minimizes the difference between the predicted and actual values
- Simple linear regression involves a single input feature and a single output variable, while multiple linear regression involves multiple input features
- The equation for a linear regression model is:
- y is the predicted output
- x₁, x₂, ..., xₙ are the input features
- β₀, β₁, β₂, ..., βₙ are the coefficients (weights) learned by the model
Coefficient Estimation and Assumptions
- The coefficients are estimated using optimization techniques such as:
- Ordinary least squares (OLS)
- Gradient descent
- These techniques minimize the sum of squared residuals between the predicted and actual values
- Assumptions of linear regression include:
- Linearity: The relationship between input features and output is linear
- Independence: The observations are independent of each other
- Homoscedasticity: The variance of the residuals is constant across all levels of the input features
- Normality: The residuals are normally distributed
- Violations of these assumptions can affect the model's performance and interpretation
- Regularization techniques such as L1 (Lasso) and L2 (Ridge) can be applied to linear regression to prevent overfitting and handle high-dimensional data
Logistic Regression for Classification
Binary Classification and Logistic Function
- Logistic regression is a supervised learning algorithm used for binary classification problems
- The goal is to predict the probability of an instance belonging to a particular class (usually the positive class denoted as 1)
- Unlike linear regression, which predicts continuous values, logistic regression predicts the probability using the logistic (sigmoid) function
- The logistic function maps the input features to a probability value between 0 and 1, representing the likelihood of the instance belonging to the positive class
Equation and Coefficient Estimation
- The equation for logistic regression is:
- p(y=1|x) is the probability of the instance belonging to the positive class given the input features x₁, x₂, ..., xₙ
- β₀, β₁, β₂, ..., βₙ are the coefficients learned by the model
- The coefficients are estimated using techniques such as:
- Maximum likelihood estimation (MLE)
- Gradient descent
- These techniques maximize the likelihood of observing the training data given the model parameters
- The decision boundary in logistic regression is determined by a threshold probability (usually 0.5)
- Above the threshold, an instance is classified as positive
- Below the threshold, an instance is classified as negative
- Logistic regression can be extended to handle multi-class classification problems using techniques such as one-vs-all (OvA) or softmax regression
Decision Trees and Random Forests
Decision Trees
- Decision trees are a supervised learning algorithm that can be used for both classification and regression tasks
- They create a tree-like model of decisions and their possible consequences based on the input features
- In a decision tree:
- Each internal node represents a feature (attribute)
- Each branch represents a decision rule
- Each leaf node represents an outcome (class label for classification or continuous value for regression)
- The tree is constructed by recursively splitting the data based on the feature that provides the most information gain or reduces the impurity the most, until a stopping criterion is met (maximum depth, minimum samples per leaf)
- Decision trees have the advantage of being interpretable and able to handle both categorical and numerical features
- However, they can be prone to overfitting if not properly regularized

Random Forests
- Random forests are an ensemble learning method that combines multiple decision trees to improve prediction accuracy and reduce overfitting
- In a random forest:
- Multiple decision trees are trained on different subsets of the training data (bootstrap sampling)
- At each split, a random subset of features is considered (feature bagging)
- The final prediction of a random forest is obtained by aggregating the predictions of individual trees:
- For classification: majority voting
- For regression: averaging
- Random forests have the advantage of:
- Reducing overfitting
- Handling high-dimensional data
- Providing feature importance measures
- They are widely used in various domains due to their robustness and good performance
Support Vector Machines for Classification
Optimal Hyperplane and Margin
- Support vector machines (SVMs) are a powerful supervised learning algorithm primarily used for binary classification problems, particularly when dealing with complex, non-linearly separable data
- The goal of an SVM is to find the optimal hyperplane that maximally separates the two classes in the feature space
- The optimal hyperplane maximizes the margin (distance) between the hyperplane and the closest data points from each class (support vectors)
- In linearly separable cases, the SVM finds the hyperplane that perfectly separates the two classes
- In non-linearly separable cases, the SVM transforms the input features into a higher-dimensional space using kernel functions (polynomial, radial basis function) to find a separating hyperplane
Optimization and Decision Function
- The optimization problem in SVMs involves finding the hyperplane that minimizes the classification error while maximizing the margin
- This is formulated as a quadratic programming problem and solved using techniques such as sequential minimal optimization (SMO)
- The decision function of an SVM is determined by the support vectors, which are the data points closest to the hyperplane
- The class prediction for a new instance is based on which side of the hyperplane it falls on
Extensions and Hyperparameter Tuning
- SVMs have the advantage of being effective in high-dimensional spaces, even when the number of features exceeds the number of samples
- They are also robust to outliers and have good generalization performance
- SVMs can be extended to handle multi-class classification problems using techniques such as:
- One-vs-one (OvO)
- One-vs-all (OvA)
- The choice of kernel function and hyperparameters is crucial for the performance of SVMs and often requires careful tuning using techniques such as cross-validation
- Hyperparameters include the regularization parameter C and kernel coefficients