Simple linear regression is a powerful tool for analyzing relationships between two variables. It helps predict outcomes and understand how changes in one variable affect another, making it crucial for decision-making in various fields like business, economics, and science.
This method forms the foundation of more complex regression techniques. By mastering simple linear regression, you'll gain insights into model fitting, assumption checking, and result interpretation, setting the stage for advanced regression analysis in future studies.
Simple Linear Regression
Concept and Purpose
- Simple linear regression is a statistical method used to model and analyze the linear relationship between two continuous variables, typically denoted as the independent variable (X) and the dependent variable (Y)
- Identifies the nature and strength of the relationship between X and Y, allowing for predictions of the dependent variable based on the independent variable
- The linear relationship between X and Y is represented by the equation: , where is the y-intercept, is the slope, and is the random error term
- The slope () represents the change in Y for a one-unit increase in X, while the y-intercept () represents the predicted value of Y when X is zero
Assumptions
- Simple linear regression assumes a linear relationship between X and Y
- Independence of observations is required, meaning that the value of one observation does not influence the value of another
- Homoscedasticity assumes constant variance of errors across all levels of the independent variable
- Normality of residuals assumes that the differences between observed and predicted values (residuals) follow a normal distribution
- Violations of these assumptions can lead to biased or inefficient estimates and affect the validity of the model
Slope and Intercept Interpretation
Slope Interpretation
- The slope () represents the change in the dependent variable (Y) for a one-unit increase in the independent variable (X), holding all other factors constant
- The interpretation of the slope depends on the context of the problem and the units of the variables involved
- Example: If X represents years of experience and Y represents salary, a slope of 5,000 would indicate that, on average, an employee's salary increases by $$5,000 for each additional year of experience
- The sign of the slope (positive or negative) indicates the direction of the relationship between X and Y
Intercept Interpretation
- The y-intercept () represents the predicted value of the dependent variable (Y) when the independent variable (X) is zero
- The interpretation of the y-intercept depends on the context of the problem and whether a zero value for X is meaningful
- Example: In the salary example, a y-intercept of 30,000 would indicate that an employee with zero years of experience is expected to have a salary of $$30,000
- In some cases, the y-intercept may not have a practical interpretation if a zero value for X is not possible or meaningful in the context of the problem
Model Fit and Prediction
Goodness of Fit
- The goodness of fit of a simple linear regression model refers to how well the model fits the observed data points
- The coefficient of determination (R²) measures the proportion of variance in the dependent variable that is explained by the independent variable, ranging from 0 to 1
- An R² value close to 1 indicates a strong linear relationship and good model fit, while a value close to 0 suggests a weak relationship and poor model fit
- The adjusted R² accounts for the number of predictors in the model and is useful for comparing models with different numbers of predictors
- Example: An R² value of 0.85 indicates that 85% of the variance in the dependent variable is explained by the independent variable
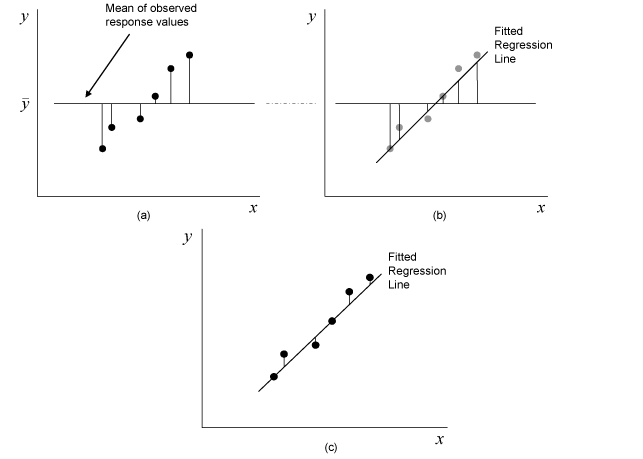
Residual Analysis
- Residual analysis involves examining the differences between the observed and predicted values (residuals) to assess the model's assumptions and identify any patterns or outliers that may affect the model's validity
- Residual plots (residuals vs. fitted values, residuals vs. independent variable) can help identify violations of linearity, homoscedasticity, and independence assumptions
- Example: A residual plot showing a random scatter of points around zero with no discernible pattern suggests that the model's assumptions are met
Predictive Power
- Predictive power refers to the model's ability to accurately predict the dependent variable for new observations
- The standard error of the estimate measures the average distance between the observed values and the predicted values, providing an estimate of the model's predictive accuracy
- Prediction intervals can be constructed to quantify the uncertainty associated with predictions for new observations
- Example: A 95% prediction interval for a new observation indicates that there is a 95% probability that the true value of the dependent variable for that observation falls within the interval
Regression Applications
Problem Identification
- Identifying the dependent and independent variables is the first step in applying simple linear regression to real-world problems
- The dependent variable (Y) is the outcome or response variable that is being predicted or explained
- The independent variable (X) is the predictor or explanatory variable that is used to predict or explain the dependent variable
- Example: In a study of the relationship between advertising expenditure and sales, advertising expenditure would be the independent variable (X), and sales would be the dependent variable (Y)
Data Preparation
- Data collection and preprocessing involve gathering relevant data, handling missing values, and ensuring data quality for analysis
- Data cleaning may involve removing outliers, transforming variables (e.g., log transformation), or addressing multicollinearity (high correlation between independent variables)
- Example: Before fitting a simple linear regression model, missing values in the dataset may need to be imputed using techniques such as mean imputation or regression imputation
Model Fitting and Interpretation
- Fitting the simple linear regression model to the data using statistical software or programming languages (R, Python) enables the estimation of the slope and intercept coefficients
- Interpreting the model coefficients, goodness of fit measures, and statistical significance tests (t-tests for coefficients, F-test for overall model significance) in the context of the problem is crucial for drawing meaningful conclusions
- Assessing the model's assumptions (linearity, independence, homoscedasticity, normality of residuals) is essential to ensure the validity of the conclusions drawn from the model
- Example: A statistically significant positive slope coefficient for advertising expenditure would indicate that increasing advertising expenditure is associated with higher sales
Prediction and Communication
- Using the fitted model to make predictions for new observations and quantifying the uncertainty associated with these predictions (prediction intervals) enables informed decision-making based on the model results
- Communicating the findings, limitations, and implications of the simple linear regression analysis to stakeholders in a clear and concise manner is essential for effective application of the results in real-world settings
- Example: Based on the fitted model, a company may predict that increasing advertising expenditure by 50,000, with a 95% prediction interval of [65,000]