HDFS architecture is the backbone of Hadoop's distributed storage system. It consists of key components like NameNode, DataNodes, and Secondary NameNode, each playing a crucial role in managing and storing data across a cluster.
HDFS excels at handling large datasets by dividing them into blocks and replicating them across multiple nodes. This approach ensures data reliability, fault tolerance, and efficient read/write operations, making it ideal for big data processing tasks.
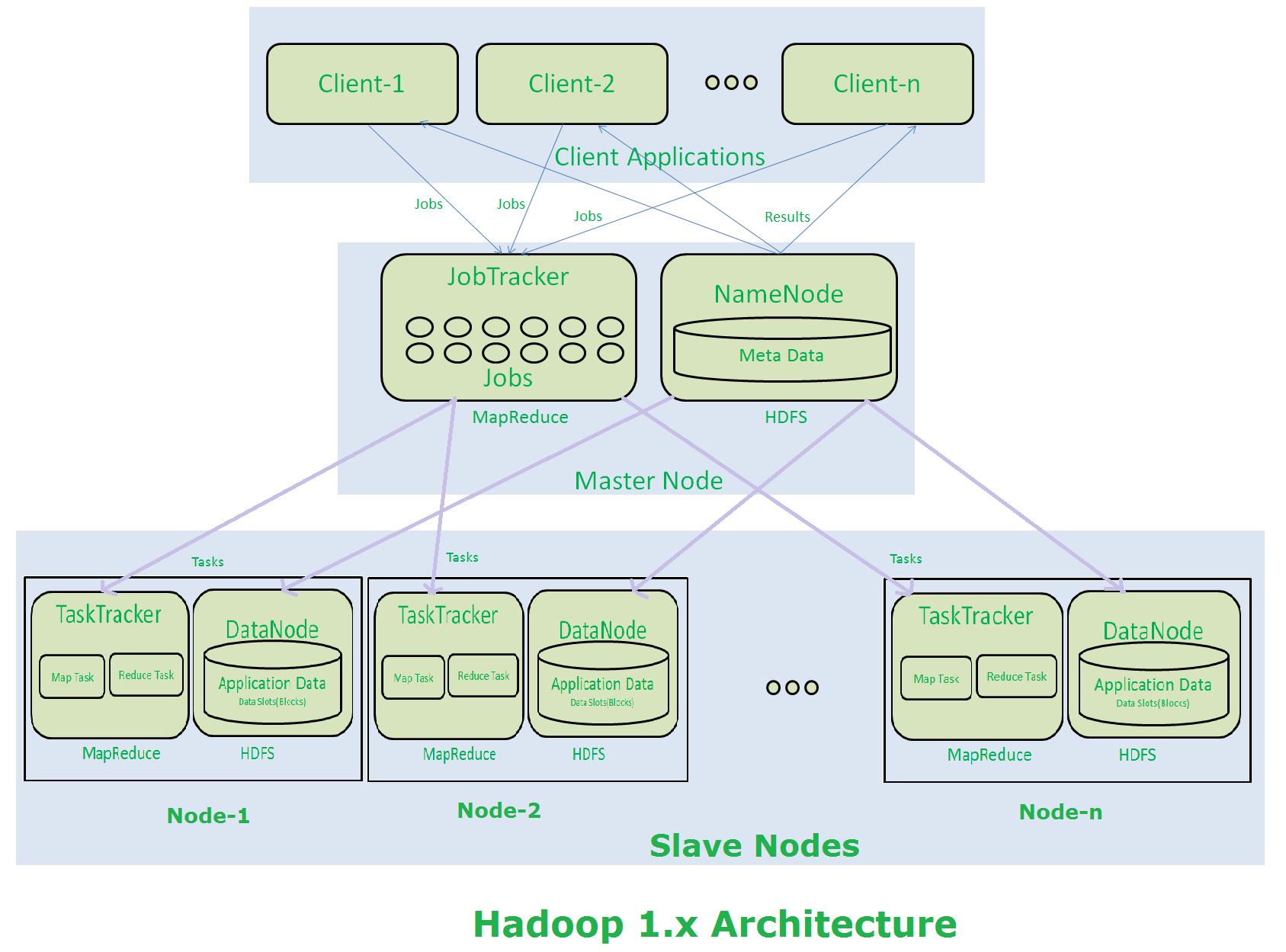
HDFS Architecture and Components
Components of HDFS architecture
- NameNode
- Manages file system namespace and regulates client access to files
- Maintains file system tree and metadata for all files and directories
- Tracks location of data blocks across the cluster (block mapping)
- Receives heartbeats and block reports from DataNodes to monitor their status
- Secondary NameNode
- Performs periodic checkpoints of NameNode's metadata to prevent file system corruption
- Merges NameNode's edit log with FsImage to create a new FsImage, reducing restart time
- Acts as a backup for the NameNode metadata but does not replace the primary NameNode if it fails
- DataNodes
- Store and retrieve data blocks as requested by clients
- Send periodic heartbeats to NameNode to confirm their active status and availability
- Send block reports to NameNode providing information about the data blocks they store
- Serve read and write requests from file system clients for data blocks
Data storage and replication in HDFS
- Divides data into large blocks (typically 128 MB) distributed across the cluster
- Replicates each block on multiple DataNodes (default replication factor of 3)
- Stores replicas on different racks to ensure data availability during rack failures
- Allows for faster data retrieval and fault tolerance
- NameNode maintains a mapping of blocks to DataNodes for efficient data access
- Detects DataNode failures and initiates replication of lost blocks on other DataNodes
- Ensures data remains available even if a DataNode fails or becomes unavailable
- Automatically balances replicas across the cluster to maintain the specified replication factor
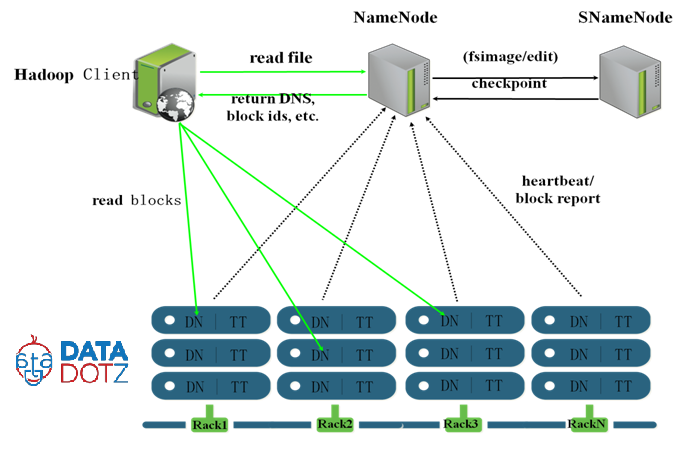
Reading and writing processes in HDFS
-
Reading data from HDFS
- Client contacts NameNode to obtain locations of required data blocks
- NameNode returns addresses of DataNodes hosting the blocks
- Client reads data directly from DataNodes, minimizing network congestion and latency
- If a block is unavailable, client can read from one of its replicas on another DataNode
-
Writing data to HDFS
- Client contacts NameNode to create a new file and allocate data blocks on DataNodes
- NameNode returns addresses of allocated blocks on DataNodes to the client
- Client writes data to DataNodes in a pipeline fashion (data streamed from one DataNode to another)
- DataNodes replicate the blocks based on the specified replication factor
- Once all blocks are written and replicated, client informs NameNode, which commits the file creation
- NameNode updates the file system metadata to reflect the new file and its block locations
HDFS vs traditional file systems
- Scalability
- HDFS scales horizontally by adding commodity hardware (DataNodes) to the cluster
- Traditional file systems limited in scaling beyond the capacity of a single server (vertical scaling)
- Reliability
- HDFS ensures data reliability through block replication across multiple DataNodes
- Accesses data from replicas if a DataNode fails, ensuring high availability
- Traditional file systems rely on expensive hardware (RAID) for fault tolerance, potential single point of failure
- Data Access
- HDFS optimized for large, sequential reads and writes (batch processing workloads)
- Traditional file systems better suited for random access and low-latency operations (databases, interactive applications)
- Metadata Management
- HDFS metadata managed by a single NameNode, can become a bottleneck for large clusters
- Traditional file systems distribute metadata across storage devices, allowing better performance and scalability
- Cost
- HDFS built on commodity hardware, making it cost-effective for storing and processing large datasets
- Traditional file systems often require expensive, specialized hardware for storage and fault tolerance