NoSQL databases offer diverse solutions for handling big data challenges. Key-value stores, document databases, column-family databases, and graph databases each excel in specific use cases, providing scalability and flexibility beyond traditional relational databases.
Understanding the CAP theorem is crucial when choosing a NoSQL database. It highlights the trade-offs between consistency, availability, and partition tolerance, helping developers select the right database for their specific needs and prioritize system requirements accordingly.
NoSQL Database Types and Characteristics
Types of NoSQL databases
- Key-value stores
- Store data as key-value pairs (e.g., Redis, Amazon DynamoDB, Riak)
- Provide fast and efficient retrieval of values based on keys
- Useful for caching, user session management, and real-time analytics
- Document databases
- Store data as semi-structured documents (JSON, XML)
- Flexible schema allowing for varying document structures (MongoDB, Couchbase, Apache CouchDB)
- Suitable for content management systems, product catalogs, and user profiles
- Column-family databases
- Store data in tables with rows and columns, but columns can vary by row (Apache Cassandra, Apache HBase, Google Bigtable)
- Optimized for high write throughput and fast column-based queries
- Ideal for time-series data, IoT sensor data, and log data
- Graph databases
- Store data as nodes and edges representing entities and relationships (Neo4j, Amazon Neptune, JanusGraph)
- Efficient for traversing and querying complex relationships
- Used in social networks, recommendation engines, and fraud detection

NoSQL vs relational databases
- Advantages of NoSQL databases
- Scalability enables horizontal scaling across multiple servers
- Flexibility supports unstructured and semi-structured data with dynamic schemas
- Performance optimized for specific data access patterns and high throughput
- Distributed architecture built for distributed systems and fault tolerance
- Disadvantages of NoSQL databases
- Lack of standardization with each NoSQL database having its own query language and APIs
- Limited support for complex transactions and may not provide ACID properties
- Eventual consistency prioritizes availability over strong consistency in some NoSQL databases
- Lack of mature tools and ecosystem compared to relational databases
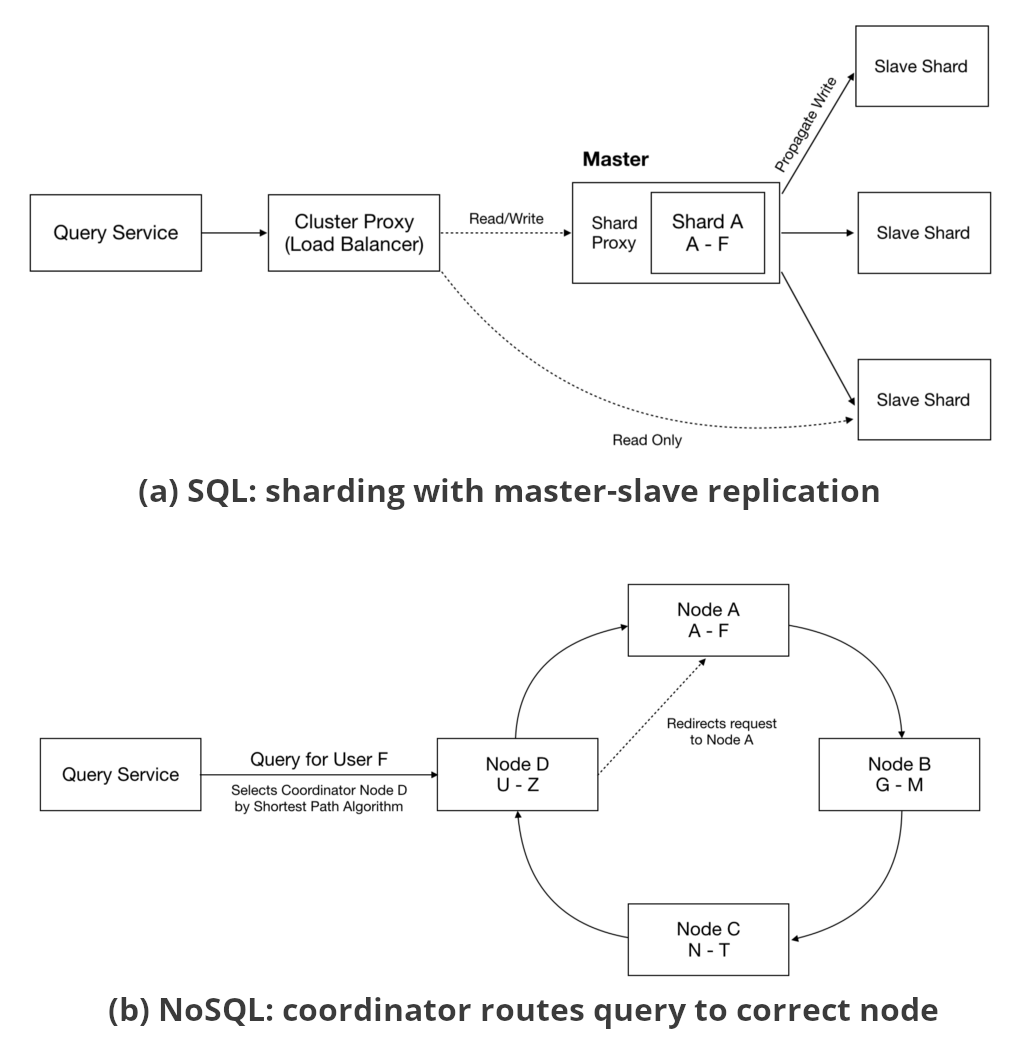
NoSQL Database Use Cases and Design Considerations
Use cases for NoSQL databases
- Key-value stores
- Caching frequently accessed data for quick retrieval
- User session management with fast lookups
- Real-time analytics for aggregating and counting data
- Document databases
- Content management systems for storing and querying semi-structured content
- Product catalogs with varying attributes
- User profiles with flexible schemas
- Column-family databases
- Time-series data storage and analysis of large volumes of time-stamped data
- IoT sensor data handling with high write throughput
- Log data storage and querying for analysis and troubleshooting
- Graph databases
- Social networks modeling and querying complex relationships between users
- Recommendation engines traversing relationships for personalized recommendations
- Fraud detection identifying patterns and connections in fraudulent activities
CAP theorem in NoSQL design
- CAP theorem states a distributed system can only provide two out of three guarantees:
- Consistency: All nodes see the same data at the same time
- Availability: Every request receives a response, without guarantee of the most recent write
- Partition tolerance: The system continues to operate despite network partitions or failures
- NoSQL databases make trade-offs based on CAP theorem
- AP systems (Cassandra) prioritize availability and partition tolerance, sacrificing strong consistency
- CP systems (MongoDB) prioritize consistency and partition tolerance, sacrificing availability during network partitions
- Understanding CAP theorem helps in selecting the appropriate NoSQL database based on specific application requirements
- If strong consistency is critical, a CP system may be preferred
- If high availability is essential and eventual consistency is acceptable, an AP system may be more suitable