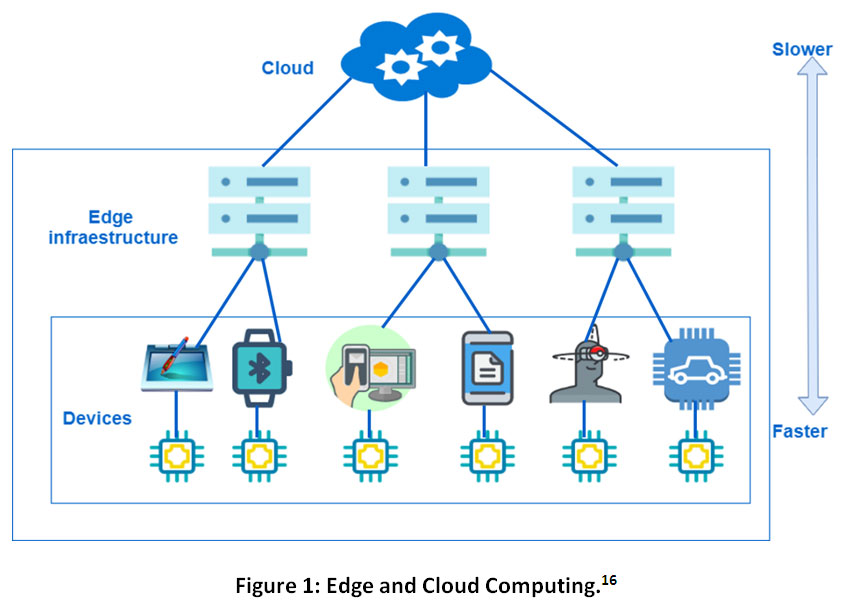
Edge computing and fog analytics are revolutionizing IoT by processing data closer to its source. This approach reduces latency, enhances privacy, and enables real-time decision-making for applications like autonomous vehicles and industrial automation.
These technologies complement cloud computing, creating a multi-layered architecture for IoT. Edge devices handle immediate processing, fog nodes aggregate and preprocess data, while the cloud performs large-scale analysis and storage, optimizing overall system performance and efficiency.
Edge Computing and Fog Analytics in IoT
Edge computing benefits for IoT
- Processes data near the source or "edge" of the network
- Enables real-time processing and decision-making (autonomous vehicles, industrial automation)
- Reduces latency by minimizing data transmission to the cloud (milliseconds vs seconds)
- Enhances data privacy and security by processing sensitive data locally (health monitoring, facial recognition)
- Faster response times for time-critical applications (emergency response systems, robotic surgery)
- Reduces bandwidth consumption and network congestion (smart city sensors, video surveillance)
- Improves scalability by distributing processing across edge devices (smart homes, wearables)
- Enhances reliability by enabling autonomous operation during network disruptions (remote monitoring, disaster response)

Edge vs fog vs cloud computing
- Edge computing performs processing directly on IoT devices or gateways (smart thermostats, industrial sensors)
- Handles immediate data processing and decision-making (machine control, anomaly detection)
- Fog computing extends the cloud closer to edge devices
- Provides an intermediate layer between edge devices and the cloud (gateways, routers)
- Enables data aggregation, preprocessing, and temporary storage (data filtering, compression)
- Supports more complex processing compared to edge computing (machine learning, pattern recognition)
- Cloud computing involves centralized processing and storage in remote data centers (AWS, Azure)
- Offers virtually unlimited resources for large-scale data analysis and long-term storage (big data analytics, data warehousing)
- Enables global access and collaboration (remote monitoring, data sharing)
- Relationship in IoT:
- Edge devices perform local processing and send relevant data to fog nodes
- Fog nodes aggregate, preprocess, and forward data to the cloud
- Cloud performs large-scale data analysis, machine learning, and long-term storage
Fog analytics in IoT processing
- Performs data analysis and processing within the fog layer
- Enables near-real-time insights and decision-making (traffic management, smart grid)
- Reduces the amount of data transmitted to the cloud (data filtering, compression)
- Allows for localized data processing and aggregation (edge analytics, data fusion)
- Predictive maintenance analyzes sensor data to detect anomalies and predict equipment failures (industrial machines, wind turbines)
- Traffic management processes traffic data in real-time to optimize traffic flow and reduce congestion (smart traffic lights, vehicle routing)
- Smart grid analyzes energy consumption data to optimize energy distribution and detect anomalies (load balancing, fraud detection)
- Environmental monitoring processes sensor data to detect environmental changes and trigger alerts (air quality, water pollution)
Challenges of edge and fog computing
- Resource constraints limit processing power, memory, and storage on edge devices
- Requires energy-efficient algorithms and hardware optimization (low-power processors, data compression)
- Data security and privacy concerns arise when ensuring secure data transmission and storage at edge and fog layers
- Requires access control and authentication mechanisms (encryption, secure protocols)
- Heterogeneity and interoperability challenges in managing diverse edge devices and communication protocols
- Requires seamless integration and data exchange between edge, fog, and cloud layers (standardization, middleware)
- Scalability and management difficulties in handling increasing number of connected devices and data volume
- Requires efficient provisioning and management of edge and fog resources (orchestration, load balancing)
- Connectivity and reliability issues when dealing with intermittent or unreliable network connections
- Requires fault tolerance and resilience in edge and fog computing environments (redundancy, failover mechanisms)