This part focuses on the components in designing an experiment and how to increase the accuracy of the results. Understanding how to avoid bias from the previous sections above relates to experiments, especially when ensuring that the data collected is representative at a population level.
An experiment is a research method that is used to study the relationship between an independent variable (the treatment or intervention being imposed on individuals) and a dependent variable (the response or outcome being measured). In an experiment, the researcher intentionally imposes some treatment or intervention on a group of individuals (the experimental group) and compares their responses to a control group, which does not receive the treatment.
Components of an Experiment
In an experiment, the experimental units are the individuals or objects that are assigned treatments or interventions. These may be people, animals, cells, plants, or other objects of study. When the experimental units are people, they are often referred to as participants or subjects.
The response variables in an experiment are the outcomes that are measured after the treatments have been administered. The response variables are what the researcher is interested in studying and are used to determine the effects of the treatments.
The explanatory variables (also called factors) in an experiment are the variables whose levels are manipulated intentionally by the researcher. The levels or combination of levels of the explanatory variable(s) are called treatments. The explanatory variables are what the researcher is manipulating in order to study the effects on the response variables.

Example
Consider an experiment that is designed to study the effects of different types of exercise on weight loss. In this experiment, the explanatory variable would be the type of exercise (e.g., running, swimming, lifting weights), and the response variable would be the amount of weight loss. The experimental units would be the individuals who are assigned to different treatments (e.g., running, swimming, lifting weights) and who are measured for their weight loss after the treatments have been administered.
By manipulating the levels of the explanatory variable (the type of exercise) and measuring the response variable (the amount of weight loss), the researcher can study the relationship between the two variables and determine whether different types of exercise have different effects on weight loss.
Confounding
Sometimes, experiments don't run smoothly due to the nature of the setup or the way the variables are considered.
For one, a confounding variable in an experiment is a variable that is related to the explanatory variable and influences the response variable, but is not being manipulated or controlled by the researcher. This means that the confounding variable may create a false perception of association between the explanatory variable and the response variable, making it difficult to determine the true effects of the explanatory variable.
For example, consider the same experiment designed to study the effects of different types of exercise on weight loss. If the experimental units are not controlled for factors such as age, diet, and genetics, these variables may act as confounding variables that influence the response variable (weight loss) and may create a false perception of association between the explanatory variable (type of exercise) and the response variable.
To control for confounding variables in an experiment, it is important to carefully design the study to minimize their influence and to use appropriate statistical methods to analyze the data. This may involve using random assignment to control for known confounding variables, using statistical models to adjust for confounding variables, or using matching or stratification techniques to ensure that the experimental groups are similar in terms of known confounding variables.
By controlling for confounding variables, researchers can more accurately determine the true effects of the explanatory variable on the response variable.
Elements of a Well-Designed Experiment
A well-designed experiment should include the following elements:
- Comparisons of at least two treatment groups, one of which could be a control group: In an experiment, it is important to compare the responses of the experimental units to at least two different levels or combinations of levels of the explanatory variable. This allows the researcher to determine the effects of the different treatments on the response variable and to identify any differences between the treatments.
One of the treatment groups may be a control group, which does not receive the treatment and serves as a baseline comparison for the other treatment groups.
- Random assignment/allocation of treatments to experimental units: To ensure that the results of the experiment are not biased, it is important to randomly assign the treatments to the experimental units. This means that each experimental unit has an equal chance of being assigned to any of the treatment groups, and that the treatment groups are similar in terms of known confounding variables.
Random assignment helps to control for these variables and ensures that the results of the experiment are not influenced by other factors.
- Replication (more than one experimental unit in each treatment group): It is important to include more than one experimental unit in each treatment group to ensure that the results are not due to chance or to the characteristics of a single unit.
This allows the researcher to calculate statistical measures such as the mean and standard deviation and to make more accurate and reliable conclusions about the effects of the treatments.
- Control of potential confounding variables where appropriate: To accurately determine the effects of the treatments on the response variable, it is important to control for potential confounding variables that may influence the results of the experiment.
This may involve using random assignment to control for known confounding variables, using statistical models to adjust for confounding variables, or using matching or stratification techniques to ensure that the experimental groups are similar in terms of known confounding variables. By controlling for confounding variables, researchers can more accurately determine the true effects of the explanatory variable on the response variable.
To design experiments properly, start with the most simple elements of an experiment which is the experimental units first, next the treatments, and finally measuring the responses.
- A control group is a collection of experimental units either not given a treatment of interest or given a treatment with an inactive substance (placebo) in order to determine if the treatment of interest has an effect. Control groups help deal with confounding because you remove the chance that an outside influence would affect the results.
- Random assignment to the experimental units is extremely important because you eliminate confounding and large differences between the treatment groups.
- Replication (repeatability) ensures the validity of your data because if you repeatedly get similar responses, that means your conclusion and analysis is accurate.
- Avoiding confounding is vital because if you need to establish causation but can’t identify the effects of the explanatory variables, the experiment data is useless. A placebo is a treatment that has no active ingredient but is otherwise like the other treatments. Sometimes, it won’t make sense for there to be a placebo group. The placebo effect occurs when some subjects in an experiment responded favorably to any treatment, even an inactive one.
Types of Experiments
Blind Experiments
In a double blind experiment, neither the subjects nor those who interact with them and measure the response variable know which treatment a subject receives. This helps avoid confounding and personal bias towards a certain outcome. In a single blind experiment, the subjects don’t know which treatment they are receiving or the people who interact with them and measure the response variable don’t know which subjects are receiving the treatment. In this type, one or the other (subject or administrator) knows, not both.
Completely Randomized Design
In a completely randomized design, the experimental units are assigned to the treatments completely by chance. Assignment of treatment to the groups must be random. The group sizes won’t always be exactly even. This is the simplest statistical design for experiments but when there are clear distinctions or similarities within the chosen experimental units, that’s when you need a more specific experimental design.
Methods for randomly assigning treatments to experimental units in a completely randomized design include using a random number generator, a table of random values, drawing chips without replacement, and the like.
Randomized Block Design
In a randomized complete block design, treatments are assigned completely at random within each block. Blocking is a technique that is used to control for variables that may influence the response variable and that are not being manipulated in the experiment. By dividing the experimental units into blocks based on one or more blocking variables, researchers can ensure that the units within each block are similar to each other with respect to these variables.
For example, consider an experiment that is designed to study the effects of different types of fertilizers on plant growth. If the experimental units are plants, the blocking variable might be the soil type. The researcher could divide the plants into blocks based on soil type, and then assign the treatments (different types of fertilizers) randomly to the plants within each block. This would ensure that the plants within each block are similar in terms of soil type, which is known to influence plant growth.
The figure below shows an example of assigning treatments to block experiments in the context of students and exam results:
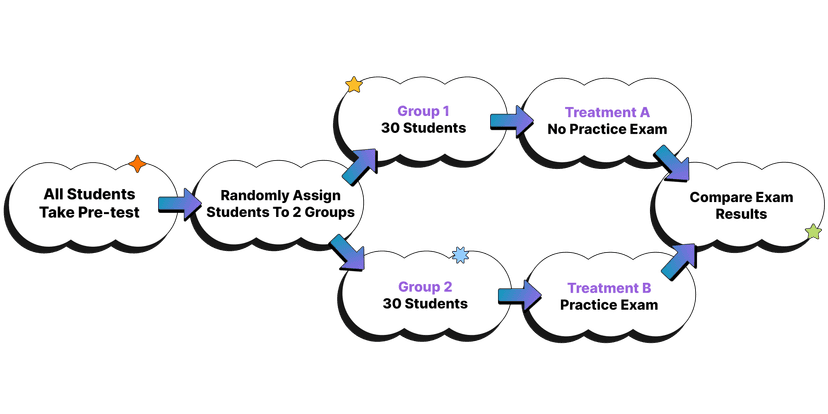
Matched Pairs
A matched pairs design is a special case of a randomized block design, as it involves the use of a blocking variable (the matched pairs) to control for variables that may influence the response variable and that are not being manipulated in the experiment.
A matched pairs design works in which subjects (whether they are people or other objects of study) are arranged in pairs that are matched on relevant factors, such as age, gender, or other characteristics. The pairs may be formed naturally, or they may be created by the researcher.
In a matched pairs design, each pair receives both treatments in a random order, either by randomly assigning one treatment to one member of the pair and the other treatment to the second member of the pair, or by giving each subject both treatments. This allows the researcher to compare the responses of the subjects to the two treatments and to determine the effects of the treatments on the response variable.
It is possible to establish causation with experiments only because treatment is imposed. That’s a major difference between studies and experiments.
Remember: Control what you can, block on what you can’t control, and randomize to create comparable groups. Be careful with combining study lingo with experiments!
🎥 Watch: AP Stats - Experiments and Observational Studies
Vocabulary
The following words are mentioned explicitly in the College Board Course and Exam Description for this topic.
| Term | Definition |
|---|---|
| blocking | A technique that groups experimental units into blocks where units within each block are similar with respect to at least one blocking variable. |
| blocking variable | A variable used to group experimental units into blocks so that natural variability can be separated from differences due to that variable. |
| completely randomized design | An experimental design where treatments are assigned to experimental units completely at random to balance the effects of confounding variables. |
| confounding variable | A variable that is related to the explanatory variable and influences the response variable, potentially creating a false perception of association between them. |
| control group | A group in an experiment that receives no treatment or a standard/baseline treatment, used as a reference for comparison. |
| double-blind experiment | An experiment where neither the subjects nor the members of the research team who interact with them know which treatment a subject is receiving. |
| experimental unit | The participants or subjects to which treatments are assigned in an experiment. |
| explanatory variable | A variable whose values are used to explain or predict corresponding values for the response variable. |
| factor | An explanatory variable in an experiment whose levels are manipulated intentionally. |
| matched pairs design | A special case of a randomized block design where subjects are arranged in pairs matched on relevant factors, and each pair receives both treatments. |
| participant | Human subjects or individuals who are assigned treatments in an experiment. |
| placebo | An inactive substance given to a control group to determine if a treatment of interest has an effect. |
| placebo effect | A response to a placebo that occurs when experimental units react to receiving a treatment, even though the treatment is inactive. |
| random assignment | The process of randomly allocating experimental units to different treatment groups to ensure unbiased distribution and reduce bias. |
| randomized complete block design | An experimental design where treatments are assigned completely at random within each block to control for a blocking variable. |
| replication | The use of multiple experimental units in each treatment group to increase reliability and reduce the effect of random variation. |
| response variable | A variable whose values are being explained or predicted based on the explanatory variable. |
| single-blind experiment | An experiment where subjects do not know which treatment they are receiving, but members of the research team do, or vice versa. |
| treatment | Different conditions assigned to experimental units in an experiment. |
| treatment groups | Distinct groups in an experiment that receive different treatments or conditions being compared. |
Frequently Asked Questions
What's the difference between experimental units and subjects?
Experimental units are the individual things assigned treatments in an experiment—they can be people, animals, plots of land, lab mice, etc. When those units are people, the CED says we usually call them subjects or participants. So “experimental unit” is the general term; “subject/participant” is the specific label when the units are human (VAR-3.A.1). Why it matters: treatments (the manipulated factor levels) are randomly assigned to experimental units, and responses are measured on those same units. Confusing units with measurements (or with groups) can lead to wrong replication counts or misapplied random assignment. On the AP exam you may be asked to identify experimental units (see example Q11 in the CED where the 20 participants are the experimental units). For a quick refresher, check the Topic 3.5 study guide (https://library.fiveable.me/ap-statistics/unit-3/intro-experimental-design/study-guide/gsdVWumN3cEYmXOIVv95). For broader review and practice problems, see the Unit 3 overview (https://library.fiveable.me/ap-statistics/unit-3) and the practice bank (https://library.fiveable.me/practice/ap-statistics).
How do I identify the explanatory variable vs the response variable in an experiment?
Ask: what did the researcher change on purpose, and what did they measure after? The variable the experimenter manipulates (factor)—its levels are the treatments—is the explanatory variable (VAR-3.A.2). The outcome measured after applying treatments is the response variable (VAR-3.A.3). The individuals assigned treatments are the experimental units/subjects (VAR-3.A.1). Quick checklist to identify them: - If it’s deliberately set by the researcher (dose, method, timing, type), it’s the explanatory variable. - If it’s the outcome you record to judge the effect (time to relief, score, blood pressure), it’s the response. - Watch for confounding variables that’re related to the explanatory variable and also affect the response (VAR-3.A.4). Example: “Give students 0, 5, or 10 mg”—dosage = explanatory, test score after = response, students = experimental units. For more on components and design tips, see the Topic 3.5 study guide (https://library.fiveable.me/ap-statistics/unit-3/intro-experimental-design/study-guide/gsdVWumN3cEYmXOIVv95). Need practice? Try problems at (https://library.fiveable.me/practice/ap-statistics).
I'm confused about confounding variables - can someone explain what they are and why they matter?
A confounding variable is a third variable that’s related to your explanatory variable (the treatment) and also affects the response—so it can make it look like the treatment caused an effect when really the confounder did. For example: if you test a new study app (treatment) but all app users are also in a small honors class (confounder = prior ability), any score improvement might be due to ability, not the app. Confounders matter because they threaten causal conclusions; AP experiments must control for them (CED VAR-3.A.4 and VAR-3.B.1d). How you handle them: random assignment helps balance unknown confounders across groups (VAR-3.C.1), blocking or matched pairs control known confounders (VAR-3.C.7–3.C.9), and using control/placebo groups and blinding reduce bias (VAR-3.C.3–3.C.6). On the exam, identify potential confounders and say which design element (randomization, blocking, control) would address them. For a quick review, see the Topic 3.5 study guide (https://library.fiveable.me/ap-statistics/unit-3/intro-experimental-design/study-guide/gsdVWumN3cEYmXOIVv95) and more unit review (https://library.fiveable.me/ap-statistics/unit-3). Practice questions are at (https://library.fiveable.me/practice/ap-statistics).
What are the four main components of a well-designed experiment that I need to memorize?
Memorize these four ingredients—they’re exactly what the CED lists for a well-designed experiment (Topic 3.5): 1. Comparisons—at least two treatment groups (one can be a control or placebo) so you can compare effects. 2. Random assignment—randomly allocate treatments to experimental units to help balance confounding variables. 3. Replication—more than one experimental unit per treatment (larger sample size = more reliable results). 4. Control of confounding variables—keep other factors constant or block/match to prevent false associations. Why it matters: on the exam you’ll need to ID these elements and explain how they reduce bias/allow causal inference (e.g., completely randomized, randomized block, matched pairs, single-blind/double-blind designs). Review the Topic 3.5 study guide for quick examples (https://library.fiveable.me/ap-statistics/unit-3/intro-experimental-design/study-guide/gsdVWumN3cEYmXOIVv95) and practice lots of problems (https://library.fiveable.me/practice/ap-statistics).
When do I use a completely randomized design vs a randomized block design?
Use a completely randomized design (CRD) when you can assign treatments to experimental units purely at random and there’s no clear, important source of variability you want to control. CRDs satisfy the AP requirements: random assignment, comparisons (≥2 treatments), replication, and control—randomization helps balance unknown confounders (CED VAR-3.C.1, VAR-3.B.1–3). Use a randomized block design (RBD) when a known factor (the blocking variable) creates large, predictable variation in the response. First group similar units into blocks (e.g., age groups, classroom, baseline score), then randomly assign all treatments within each block. Blocking separates variability due to that factor from treatment effects, reducing confounding and increasing power (CED VAR-3.C.7–8). Matched pairs is a special RBD for two treatments or “each subject gets both” (VAR-3.C.9). Quick rule: if there’s a big, known source of variability you can block on → use randomized blocks; if not → completely randomized. For more examples and AP-aligned tips, see the Topic 3.5 study guide (https://library.fiveable.me/ap-statistics/unit-3/intro-experimental-design/study-guide/gsdVWumN3cEYmXOIVv95) and practice problems (https://library.fiveable.me/practice/ap-statistics).
How do I randomly assign treatments to experimental units step by step?
Step-by-step for randomly assigning treatments (completely randomized design): 1. Identify your experimental units (subjects) and treatments (factor levels)—e.g., 60 students and 3 dosages (CED VAR-3.A). 2. Decide replication: how many units per treatment (replicate each treatment >1) (CED VAR-3.B). 3. List every unit and give each a unique ID (1–60). 4. Choose a random method: random number generator, table of random digits, or drawing chips without replacement (CED VAR-3.C.2). 5. Use the random method to assign IDs to treatments until each treatment has its planned number of units. Example: generate 60 random numbers, sort IDs by those numbers, then slice into treatment groups of equal size. 6. If blocking/matched pairs are appropriate (to control confounding), form blocks first (units similar on blocking variable) and then randomize treatments within each block (CED VAR-3.C.7–3.9). 7. Implement blinding if possible (single- or double-blind) to reduce placebo or observer effects (CED VAR-3.C.3–3.4). 8. Record assignment procedure so you can justify randomization on the AP exam. For practice and reminders of methods and vocabulary, see the Topic 3.5 study guide (https://library.fiveable.me/ap-statistics/unit-3/intro-experimental-design/study-guide/gsdVWumN3cEYmXOIVv95) and try practice problems (https://library.fiveable.me/practice/ap-statistics).
What's the difference between single-blind and double-blind experiments?
Single-blind vs double-blind is about who’s kept from knowing which treatment each subject gets so bias is reduced. In a single-blind experiment either the subjects don’t know their treatment (common with placebos) or the researchers who interact with subjects don’t know—but not both (CED: VAR-3.C.3). That helps limit placebo effects or subject expectations. In a double-blind experiment neither the subjects nor the research team who interact with them know which treatment a subject receives (CED: VAR-3.C.4). Double-blinding is stronger for controlling bias from both participant expectations and researcher behavior when measuring the response variable. Both designs still need random assignment, replication, and control groups to avoid confounding (VAR-3.B.1). For the AP exam, recognize definitions and be able to identify which is used in a study (Topic 3.5). For a quick refresher, see the Topic 3.5 study guide (https://library.fiveable.me/ap-statistics/unit-3/intro-experimental-design/study-guide/gsdVWumN3cEYmXOIVv95) and try practice problems (https://library.fiveable.me/practice/ap-statistics).
I don't understand the placebo effect - why do we need control groups with placebos?
Placebo effect is when subjects respond just because they think they’re getting a real treatment. That can make a treatment look effective even if it’s not. That’s why experiments need a control group given a placebo (VAR-3.C.5–6): it gives you a baseline to compare the treatment group to, so differences in the response variable can be attributed to the actual treatment, not expectations or other confounding factors. Random assignment and replication help balance other confounders, and single- or double-blinding (VAR-3.C.3–4) reduces bias from subjects or researchers who know the assignment. On the AP exam, you should be able to identify a control/placebo group and explain the placebo effect’s role in ruling out non-treatment causes of change (Topic 3.5). For a quick review, check the Topic 3.5 study guide (https://library.fiveable.me/ap-statistics/unit-3/intro-experimental-design/study-guide/gsdVWumN3cEYmXOIVv95) and try practice problems (https://library.fiveable.me/practice/ap-statistics).
How do I set up a matched pairs design and when should I use it?
Use a matched pairs design when you can pair similar experimental units so the pair-to-pair variability is reduced—especially when each subject can receive both treatments (before/after) or you can match two subjects on key factors (age, gender, baseline score) and give one treatment to each. Matched pairs is a special case of randomized block designs (CED VAR-3.C.9). How to set it up: 1. Choose the blocking variable(s) that make pairs similar (e.g., same baseline score). 2. Form pairs either naturally (same person, before vs. after) or by matching two subjects. 3. Randomly assign which member of each pair gets treatment A or B (or randomly order treatments for within-subject designs). Random assignment, replication, and control of confounders remain required (CED VAR-3.B). 4. Measure the response and analyze differences within pairs. This is commonly tested on the AP exam under experimental-design questions (Topic 3.5). For a quick refresher, see the Topic 3.5 study guide (https://library.fiveable.me/ap-statistics/unit-3/intro-experimental-design/study-guide/gsdVWumN3cEYmXOIVv95) and practice problems (https://library.fiveable.me/practice/ap-statistics).
What's a blocking variable and how is it different from a confounding variable?
A blocking variable is a factor you use intentionally to group experimental units that are similar before you assign treatments—blocks are created so units within each block are alike on that variable (e.g., age groups, sex, baseline disease severity). In a randomized block design you randomize treatments within each block to reduce variability from that blocking variable (CED VAR-3.C.7–8). A confounding variable, by contrast, is an uncontrolled factor that is related to the explanatory variable and also affects the response, so it can create a false impression that the treatment caused the effect (CED VAR-3.A.4). The key difference: blocking is a planned control strategy to account for a known source of variability; confounding is an unwanted mix-up that makes causal interpretation unclear. For more on randomized block and matched-pairs designs, check the Topic 3.5 study guide (https://library.fiveable.me/ap-statistics/unit-3/intro-experimental-design/study-guide/gsdVWumN3cEYmXOIVv95) and practice problems at (https://library.fiveable.me/practice/ap-statistics).
Can someone explain the difference between replication and random assignment?
Replication and random assignment are different but both required for a good experiment (VAR-3.B). Random assignment means you assign treatments to experimental units by chance (using a random number generator, table, chips, etc.) so uncontrolled confounding variables are balanced across groups (VAR-3.C.1–.2). Replication means you have more than one experimental unit in each treatment group—multiple subjects get each treatment so results aren’t based on a single person or fluke (VAR-3.B.1.c). Quick way to remember: random assignment decides who gets which treatment; replication gives you enough subjects per treatment to estimate variability and make results reliable. Both help you attribute differences in the response variable to the treatments rather than to chance or confounding (see Topic 3.5 CED). For more examples and practice, check the Topic 3.5 study guide (https://library.fiveable.me/ap-statistics/unit-3/intro-experimental-design/study-guide/gsdVWumN3cEYmXOIVv95) and more practice problems (https://library.fiveable.me/practice/ap-statistics).
I missed class - what exactly is a treatment in experimental design?
A treatment is the specific condition you give to experimental units—it’s the level or combination of levels of an explanatory variable (factor) that you intentionally set. For example, if the factor is pain-killer dose, treatments might be 0 mg (placebo), 5 mg, and 10 mg. Treatments are what you compare to see effects on a response variable (the outcome you measure). Good experiments have ≥2 treatment groups (often including a control or placebo), use random assignment to put units into treatments, and replicate each treatment on multiple units so differences in the response can be attributed to the treatments rather than confounding variables (CED VAR-3.A, VAR-3.B). On the AP exam you’ll need to identify treatments, experimental units/subjects, and the response when interpreting experiments. For a quick review of these ideas, see the Topic 3.5 study guide (https://library.fiveable.me/ap-statistics/unit-3/intro-experimental-design/study-guide/gsdVWumN3cEYmXOIVv95). For broader unit review and practice questions, check Unit 3 (https://library.fiveable.me/ap-statistics/unit-3) and practice problems (https://library.fiveable.me/practice/ap-statistics).
How do I know if an experiment is properly controlling for confounding variables?
Look for these AP-approved signs that confounding is being controlled: - Random assignment of treatments to experimental units. Randomization tends to balance unknown confounders so differences in the response can be attributed to treatments (CED: VAR-3.B.b, VAR-3.C.1). - A control group or placebo when appropriate so you can compare treatment effects (CED: VAR-3.B.a, VAR-3.C.5–.6). - Blocking or matched pairs if you know a specific confounder (age, sex, baseline score). Blocks group similar units and treatments are randomized within each block (CED: VAR-3.C.7–.9). - Replication: more than one unit per treatment reduces chance findings and helps detect imbalance (CED: VAR-3.B.c). - Blinding (single or double) to prevent placebo or observer effects (CED: VAR-3.C.3–.4). Practically: check the paper/design for random assignment, baseline balance tables (are known confounders similar across groups?), use of blocks/matching, sample sizes per group, and blinding. If these aren’t present, confounding is likely. For a quick topic review, see the Fiveable study guide on Intro to Experimental Design (https://library.fiveable.me/ap-statistics/unit-3/intro-experimental-design/study-guide/gsdVWumN3cEYmXOIVv95) and try practice problems at (https://library.fiveable.me/practice/ap-statistics).
What's the formula or steps for creating a randomized complete block design?
Short answer—steps (use these on the AP exam when asked about randomized complete block designs): 1. Identify the factor and its treatments (explanatory variable = treatments). 2. Pick a blocking variable that creates groups of similar experimental units with respect to a potential confounder (age, baseline score, location, etc.). 3. Form blocks so units within each block are as similar as possible. 4. Within each block, randomly assign every treatment to experimental units (i.e., treatments are assigned completely at random within each block). Ensure each treatment appears in every block if possible. 5. Replicate: have more than one unit per treatment per block (or use many blocks). 6. Include controls/placebo if appropriate and use blinding if feasible. Key AP CED links: this enforces VAR-3.B (random assignment, replication, control) and VAR-3.C.7–3.C.9 (blocking and matched pairs). For a quick topic review see the Fiveable study guide (https://library.fiveable.me/ap-statistics/unit-3/intro-experimental-design/study-guide/gsdVWumN3cEYmXOIVv95); for more unit review/practice see (https://library.fiveable.me/ap-statistics/unit-3) and (https://library.fiveable.me/practice/ap-statistics).
Why do we need at least two treatment groups in an experiment and what counts as a control group?
You need at least two treatment groups so you can make a comparison—that’s how an experiment shows a treatment caused a change instead of the change happening for some other reason (confounding). The AP CED requires “comparisons of at least two treatment groups” in a well-designed experiment (VAR-3.B.1.a). With only one group you can’t tell whether outcomes are due to the treatment, natural variation, or other variables. A control group is a set of experimental units that either receive no treatment or receive an inactive treatment (a placebo) so you can see what happens without the active factor (VAR-3.C.5). Combined with random assignment and replication, the control group helps isolate the explanatory variable’s effect on the response and reveals placebo effects (VAR-3.C.6). For more on designs and examples, check the Topic 3.5 study guide (https://library.fiveable.me/ap-statistics/unit-3/intro-experimental-design/study-guide/gsdVWumN3cEYmXOIVv95) and try practice problems (https://library.fiveable.me/practice/ap-statistics).