N-grams are the building blocks of language models, helping predict word sequences. They capture local context by analyzing contiguous word or character groups, with higher-order n-grams providing more context but requiring more data.
Language models use n-grams to estimate word probabilities based on previous words. This approach simplifies modeling by assuming a word's likelihood depends only on its recent history, making it computationally feasible for various NLP tasks.
N-grams for Language Modeling
Understanding N-grams
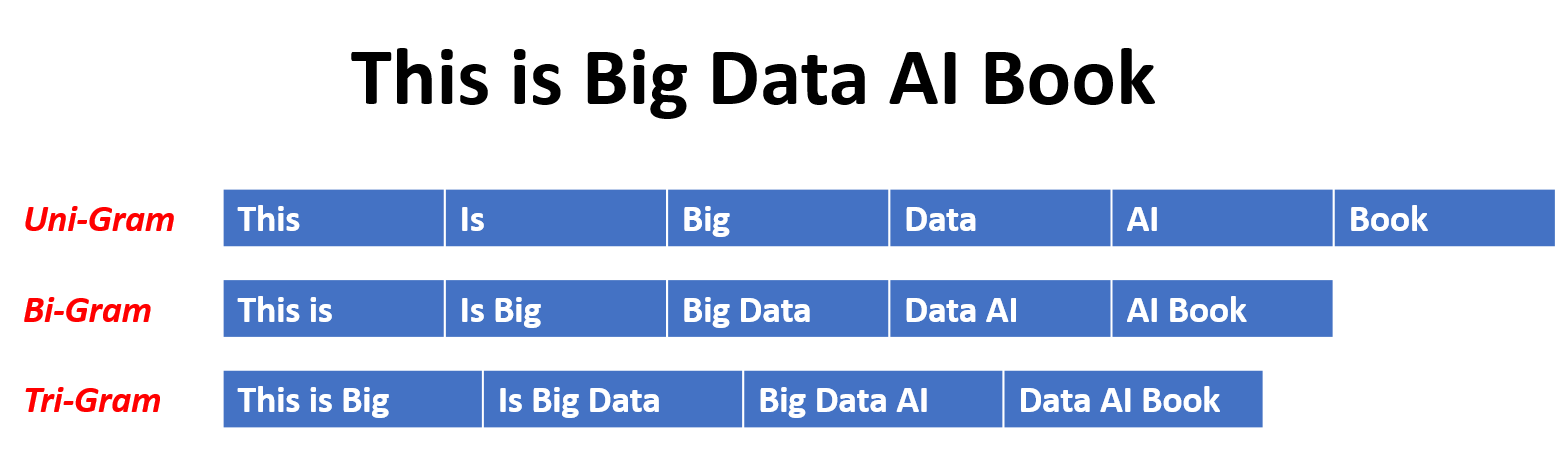
- N-grams represent contiguous sequences of n items (words or characters) extracted from a text corpus
- n is a positive integer that determines the length of the sequence
- Unigrams (1-grams) represent single items (words)
- Bigrams (2-grams) represent pairs of items (phrase)
- Trigrams (3-grams) represent triples of items (sentence fragment)
- N-grams capture the local context and statistical dependencies between words or characters in a language
- They provide information about the likelihood of words or characters appearing together
- Higher-order n-grams (larger n) capture more context but require more training data
Role of N-grams in Language Modeling
- Language models assign probabilities to sequences of words or characters
- They enable the prediction of the likelihood of a given sequence occurring in a language
- Language models are used in various NLP tasks (machine translation, speech recognition, text generation)
- N-gram language models estimate the probability of a word or character given the previous n-1 words or characters
- The estimation is based on the frequency counts of n-grams in the training corpus
- The Markov assumption simplifies language modeling by assuming that the probability of a word depends only on the previous n-1 words, rather than the entire history
- This assumption reduces the complexity of the model and makes it computationally tractable
Training N-gram Models
Counting and Probability Estimation
- Training an n-gram language model involves counting the frequencies of n-grams in a text corpus
- The counts are normalized to obtain probability estimates
- The maximum likelihood estimation (MLE) is a simple method for estimating n-gram probabilities
- MLE divides the count of an n-gram by the count of its prefix (n-1)-gram
- Example:
- Smoothing techniques address the sparsity problem in n-gram models
- Some n-grams may have zero or low counts in the training data, leading to unreliable probability estimates
- Add-one smoothing (Laplace smoothing) adds a small constant (usually 1) to the count of each n-gram to avoid zero probabilities
- Good-Turing smoothing adjusts the counts of low-frequency n-grams based on the count of n-grams with one higher frequency
- Kneser-Ney smoothing considers the contexts in which n-grams occur and assigns higher probabilities to n-grams that appear in diverse contexts
Handling Unseen N-grams
- Backoff and interpolation methods combine probabilities from lower-order n-gram models when higher-order n-grams are not available or have low counts
- Backoff methods recursively fall back to lower-order models until a non-zero probability is found
- Interpolation methods linearly combine the probabilities from different order models
- Smoothing techniques also help in handling unseen n-grams by redistributing probability mass from seen n-grams to unseen ones
- This allows the model to assign non-zero probabilities to unseen sequences
- Smoothing helps in generalization and prevents the model from overfitting to the training data
Applying N-gram Models
Text Generation
- N-gram language models can be used to generate text by iteratively predicting the next word or character based on the previous n-1 words or characters
- The generation process starts with a seed or prompt and continues by sampling words or characters from the conditional probability distribution given by the n-gram model
- The generated text follows the statistical patterns learned from the training corpus
- The quality of the generated text depends on the order of the n-gram model and the diversity of the training data
Sequence Probability Estimation
- The probability of a sequence of words or characters can be estimated by multiplying the conditional probabilities of each word or character given its preceding context
- The chain rule of probability allows the joint probability of a sequence to be decomposed into a product of conditional probabilities
- Example:
- N-gram models can be used to estimate the likelihood of a given sentence or to compare the probabilities of different sentences
- This is useful in tasks like language identification, spell checking, and speech recognition
- The probability estimates can also be used as features in other NLP models
Evaluating N-gram Model Performance
Perplexity
- Perplexity is a commonly used metric to evaluate the quality of a language model in terms of its ability to predict sequences
- Perplexity measures how surprised or confused a language model is by a given test set, with lower perplexity indicating better performance
- It is calculated as the exponential of the average negative log-likelihood of a test set under the language model
- To compute perplexity, the test set is divided into n-grams, and the log-probability of each n-gram is calculated using the trained language model
- The average negative log-likelihood is then computed by summing the log-probabilities and dividing by the total number of words or characters in the test set
- Perplexity provides an intuitive measure of the language model's uncertainty, with lower perplexity indicating better predictive power
Other Evaluation Metrics
- Cross-entropy measures the average number of bits needed to encode each word or character using the model's probability distribution
- Lower cross-entropy indicates better performance and a closer match between the model's predictions and the actual data
- The quality of generated text can be assessed through human evaluation
- Metrics like coherence, fluency, and diversity of the generated samples can be rated by human annotators
- Human evaluation provides a subjective assessment of the model's performance in generating meaningful and coherent text
Limitations of N-gram Models
- N-gram language models have limitations in capturing long-range dependencies
- They rely on the Markov assumption and consider only the local context of n-1 words or characters
- Long-range dependencies and global coherence are not effectively captured by n-gram models
- The number of parameters in an n-gram model grows exponentially with increasing n
- Higher-order models require a large amount of training data to estimate the probabilities reliably
- The sparsity problem becomes more severe for higher-order models, as many n-grams may not be observed in the training data