Encoder-decoder architecture is a powerful approach for handling sequence-to-sequence tasks. It uses an encoder to process input data and a decoder to generate output, making it perfect for tasks like translation and summarization.
This architecture shines in its ability to handle variable-length sequences and learn complex mappings. By using recurrent neural networks and techniques like attention, it can capture the essence of input data and generate appropriate outputs.
Encoder-Decoder Architecture
Key Components and Functionality
- Encoder-decoder architecture consists of two main components: encoder and decoder, which work together to process sequential input data and generate sequential output data
- Encoder takes input sequence and processes it to capture essential information, while decoder generates output sequence based on encoded representation
- Encoder and decoder typically implemented using recurrent neural networks (RNNs) or variants, such as Long Short-Term Memory (LSTM) or Gated Recurrent Unit (GRU) networks
- Enables handling of variable-length input and output sequences, making it suitable for tasks like machine translation (English to French), text summarization (news articles to headlines), and speech recognition (audio to text)
Training and Optimization
- Encoder and decoder trained jointly to optimize model's performance on specific task
- Techniques like teacher forcing (providing ground truth output tokens as input to decoder during training) and backpropagation through time (updating weights based on gradients propagated through time steps) used for training
- Objective is to minimize the difference between predicted output sequence and ground truth output sequence, typically using loss functions like cross-entropy or mean squared error
- Regularization techniques (dropout, L1/L2 regularization) and optimization algorithms (Adam, SGD) employed to improve generalization and convergence during training
Encoder: Input Processing and Context Vector
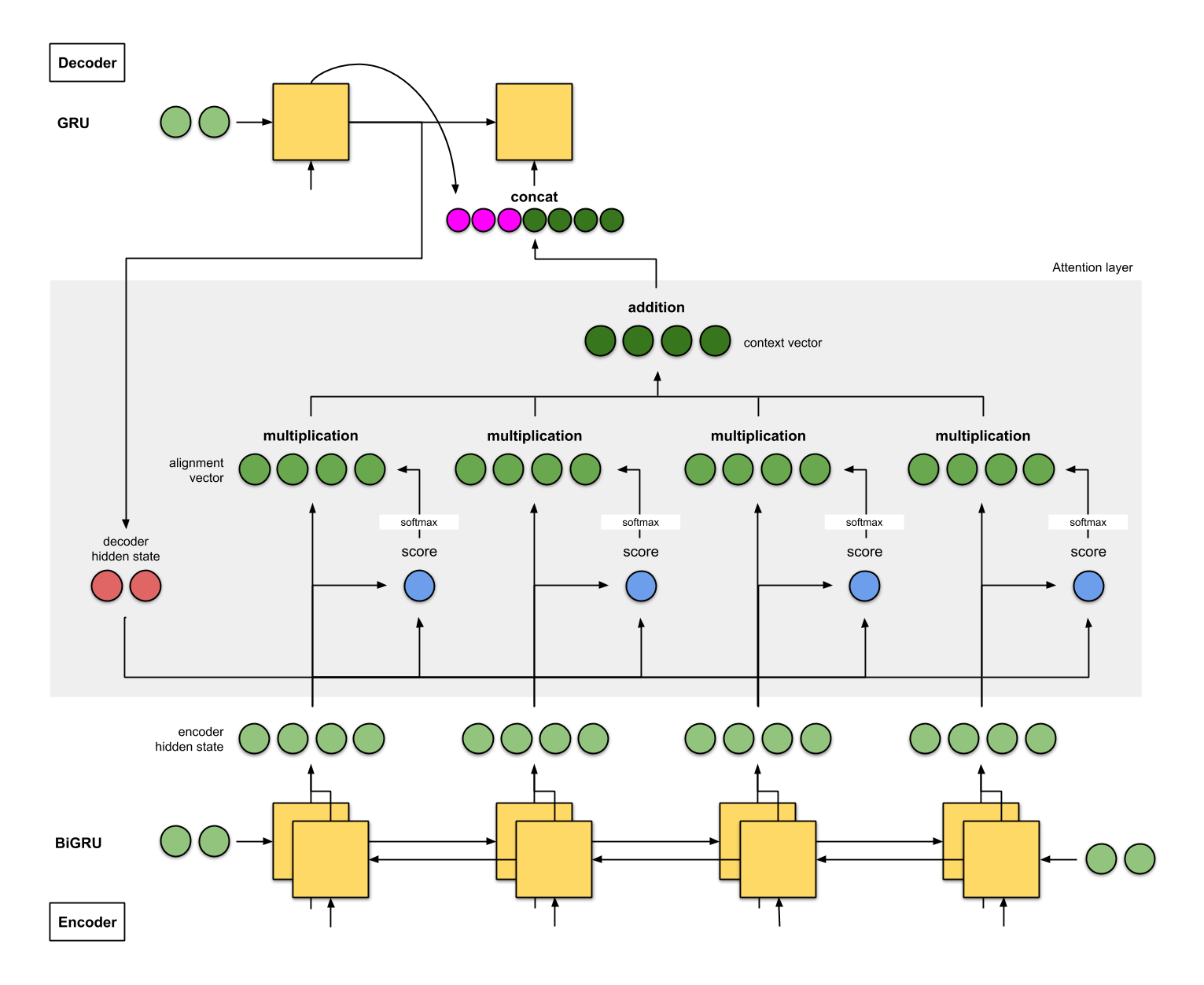
Sequential Input Processing
- Encoder takes input sequence (words, characters, or tokens) and processes it sequentially
- At each time step, encoder reads input token and updates hidden state based on current input and previous hidden state, capturing contextual information up to that point
- Implemented using RNNs (LSTM or GRU) to handle long-term dependencies and mitigate vanishing gradient problem
- Example: In machine translation, encoder processes source language sentence word by word, updating hidden state at each step
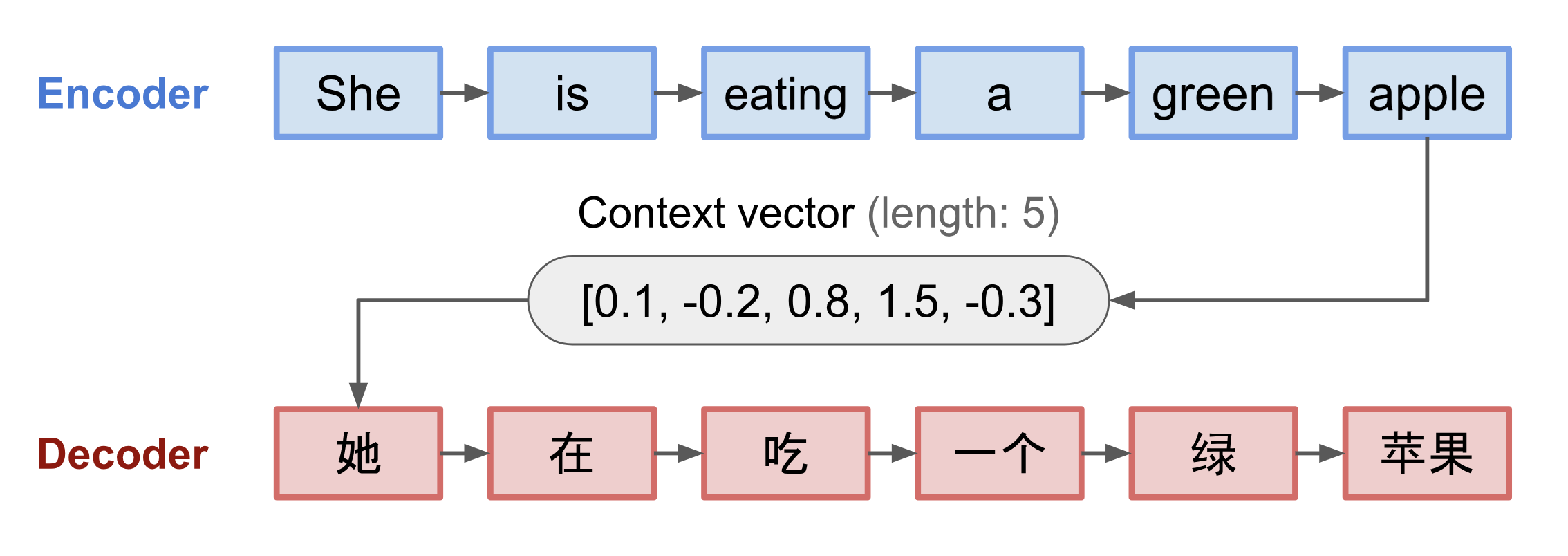
Context Vector Generation
- Final hidden state of encoder, referred to as context vector or thought vector, represents compressed summary of entire input sequence
- Captures essential information from input sequence relevant for generating output sequence
- In some variations (attention mechanisms), encoder may generate sequence of hidden states instead of single context vector, allowing decoder to selectively focus on different parts of input during decoding
- Context vector serves as initial hidden state for decoder, providing it with necessary information to generate output sequence
- Example: In text summarization, context vector encapsulates key information from input article to guide generation of summary
Decoder: Output Sequence Generation
Token-by-Token Generation
- Decoder takes context vector generated by encoder as initial hidden state and generates output sequence token by token
- At each time step, decoder predicts next token in output sequence based on current hidden state and previously generated tokens
- Uses softmax layer to produce probability distribution over possible output tokens at each step, allowing generation of most likely token
- During training, teacher forcing (feeding ground truth output tokens as inputs to decoder) helps learn to generate correct output sequence
- During inference, decoder generates output sequence step by step, using previously generated tokens as inputs to predict next token until stop condition is met (generating end-of-sequence token or reaching maximum sequence length)
Attention Mechanisms
- Decoder can incorporate attention mechanisms to attend to different parts of input sequence at each decoding step
- Attention allows decoder to focus on relevant information from input for generating current output token
- Computes attention weights that indicate importance of each input token for generating current output token
- Attention weights used to compute weighted sum of encoder hidden states, generating context vector specific to current decoding step
- Enables decoder to selectively focus on different parts of input sequence as it generates output, improving performance on tasks like machine translation and text summarization
- Example: In machine translation, attention allows decoder to align each translated word with relevant words in source sentence
Advantages of Encoder-Decoder Architecture
Handling Variable-Length Sequences
- Well-suited for tasks involving mapping input sequences to output sequences (machine translation, text summarization, speech recognition)
- By encoding input sequence into fixed-length context vector, architecture can handle variable-length input sequences and capture essential information
- Decoder's ability to generate variable-length output sequences based on context vector allows for flexible and dynamic output generation
- Example: In speech recognition, encoder can process audio input of varying lengths and decoder can generate text transcriptions of corresponding lengths
Learning Complex Mappings
- Can learn complex mappings between input and output sequences, capturing dependencies and relationships between elements of sequences
- Use of RNNs or variants in encoder and decoder enables capturing and exploiting sequential nature of data
- Architecture can be extended with additional mechanisms (attention) to improve model's ability to focus on relevant parts of input during decoding
- Has achieved state-of-the-art performance on various sequence-to-sequence tasks, demonstrating effectiveness in handling sequential data
- Example: In machine translation, encoder-decoder architecture can learn to map sentences from one language to another, capturing linguistic structures and semantic meanings