Multilingual NLP tackles the challenge of developing systems that work across multiple languages, especially those with limited resources. It's crucial for promoting language equality and enabling access to technology for underrepresented communities.
This topic connects to the broader chapter by exploring how sequence-to-sequence models and machine translation techniques can be adapted for low-resource languages. It highlights strategies like cross-lingual transfer learning and data augmentation to bridge the gap between high and low-resource languages.
Challenges of Multilingual NLP
Language Diversity and Variations
- Multilingual NLP aims to develop NLP systems that can handle multiple languages, particularly low-resource languages with limited available data and resources
- Challenges in multilingual NLP include dealing with language diversity, variations in syntax (word order and sentence structure), morphology (word formation and inflection), and semantics (meaning) across languages
- Language-specific preprocessing and feature engineering are often needed to address these variations effectively
- Examples of language diversity include differences in writing systems (alphabets, characters), word order (Subject-Verb-Object, Subject-Object-Verb), and grammatical features (gender, case marking)
Scarcity of Resources for Low-Resource Languages
- Low-resource languages often lack sufficient labeled data, linguistic resources (dictionaries, corpora), and pre-trained models, making it challenging to build effective NLP systems for these languages
- Addressing the challenges of low-resource languages is crucial for promoting language equality, preserving cultural heritage, and enabling access to information and technologies for underrepresented language communities
- Examples of low-resource languages include Quechua (indigenous language of South America), Yoruba (African language), and Hmong (Asian language)
- Multilingual NLP techniques can help bridge the language divide, facilitate cross-lingual information retrieval and machine translation, and support applications such as sentiment analysis and named entity recognition in multiple languages
Leveraging High-Resource Languages
Cross-Lingual Transfer Learning
- Cross-lingual transfer learning involves leveraging knowledge and resources from high-resource languages (English, Spanish) to improve NLP performance in low-resource languages
- Techniques such as annotation projection and cross-lingual word embeddings enable the transfer of linguistic information from high-resource to low-resource languages
- Annotation projection automatically transfers annotations (part-of-speech tags, named entity labels) from a high-resource language to a low-resource language through parallel corpora or machine translation
- Cross-lingual word embeddings align word vectors from different languages into a shared semantic space, allowing for knowledge transfer and enabling downstream tasks like cross-lingual sentiment analysis or named entity recognition
- Multilingual pre-trained language models, such as mBERT and XLM-R, can be fine-tuned on low-resource languages, leveraging the models' pre-trained knowledge to improve performance on specific NLP tasks
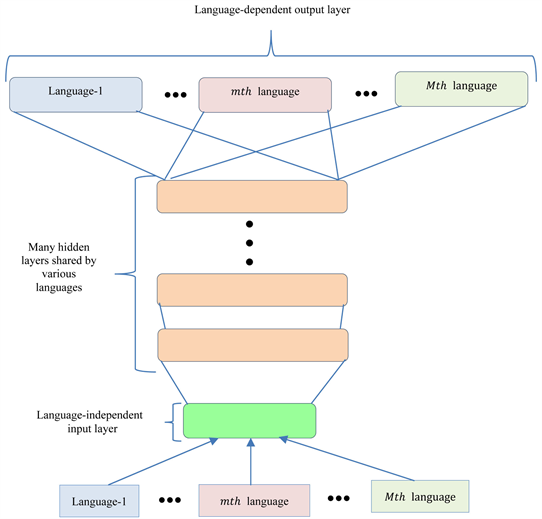
Utilizing Linguistic Resources
- Leveraging linguistic resources, such as bilingual dictionaries, parallel corpora (texts aligned across languages), and typological databases (information about language features), can provide valuable information for improving NLP performance in low-resource languages
- Techniques like zero-shot learning and few-shot learning can be employed to adapt high-resource language models to low-resource languages with minimal or no labeled data
- Zero-shot learning enables the application of models trained on high-resource languages directly to low-resource languages without the need for labeled data in the target language
- Few-shot learning techniques, such as cross-lingual meta-learning and cross-lingual data augmentation, can effectively adapt models to low-resource languages with only a small amount of labeled data
Transfer Learning for Low-Resource NLP
Multilingual Embeddings
- Multilingual embeddings, such as fastText and MUSE, capture semantic similarities across languages and enable knowledge transfer from high-resource to low-resource languages
- These embeddings align word vectors from different languages into a shared semantic space, allowing for cross-lingual comparisons and knowledge transfer
- Examples of multilingual embedding models include fastText (supports 157 languages) and MUSE (Multilingual Unsupervised and Supervised Embeddings)
Pre-trained Multilingual Language Models
- Pre-trained multilingual language models, like mBERT (Multilingual BERT) and XLM-R (Cross-lingual Language Model), can be fine-tuned on low-resource languages with limited labeled data, leveraging the models' pre-trained knowledge to improve performance on downstream tasks
- These models are trained on large amounts of multilingual text data and learn language-agnostic representations that can be transferred to low-resource languages
- Fine-tuning these models on task-specific data in low-resource languages can significantly improve performance compared to training from scratch

Unsupervised Cross-Lingual Representation Learning
- Unsupervised cross-lingual representation learning techniques, such as cross-lingual language model pre-training and unsupervised machine translation, can learn language-agnostic representations without relying on labeled data
- These techniques leverage large amounts of unlabeled multilingual text data to learn shared representations across languages
- Examples include XLM (Cross-lingual Language Model) and MASS (Masked Sequence to Sequence Pre-training)
Data Augmentation for Low-Resource NLP
Monolingual and Cross-Lingual Data Augmentation
- Data augmentation techniques can be used to increase the amount of training data available for low-resource languages, improving the performance of NLP models
- Monolingual data augmentation generates synthetic examples by applying linguistic transformations (word substitution, paraphrasing) to existing monolingual data in the low-resource language
- Cross-lingual data augmentation generates synthetic examples by projecting annotations from high-resource languages to low-resource languages using parallel corpora or cross-lingual word alignments
- Examples of data augmentation techniques include back-translation (translating from the target language to a high-resource language and then back to the target language) and synonym replacement
Unsupervised Data Generation
- Unsupervised data generation techniques, such as back-translation and self-training, can be employed to generate pseudo-labeled data for low-resource languages
- Back-translation involves translating monolingual data from the low-resource language to a high-resource language and then back to the low-resource language, creating synthetic parallel data
- Self-training iteratively trains a model on its own high-confidence predictions on unlabeled data, gradually expanding the labeled dataset
- These techniques can help alleviate the scarcity of labeled data in low-resource settings
Multilingual Data Augmentation Strategies
- Multilingual data augmentation strategies, like multilingual fine-tuning and multilingual multi-task learning, can leverage data from multiple languages to improve performance in low-resource languages
- Multilingual fine-tuning involves fine-tuning a pre-trained multilingual model on labeled data from multiple languages simultaneously
- Multilingual multi-task learning trains a single model to perform multiple tasks across different languages, sharing knowledge and representations
- Data augmentation techniques should be carefully designed to preserve the linguistic properties and maintain the quality of the generated examples to avoid introducing noise or biases