Data cleaning is a critical step in predictive analytics, ensuring the accuracy and reliability of business insights. This process involves handling missing values, removing duplicates, correcting inconsistencies, and standardizing formats to create high-quality datasets for analysis.
Effective data cleaning techniques improve model performance and decision-making. By implementing best practices like documentation, iterative processes, and validation, businesses can overcome challenges in big data, real-time cleaning, and domain-specific requirements, leading to more trustworthy predictions.
Types of data cleaning
- Data cleaning forms a crucial foundation for predictive analytics in business, ensuring that models are built on accurate and reliable information
- Effective data cleaning techniques significantly improve the quality of insights and predictions derived from business data
- Proper implementation of data cleaning methods reduces errors in analysis and enhances decision-making processes in various business contexts
Handling missing values
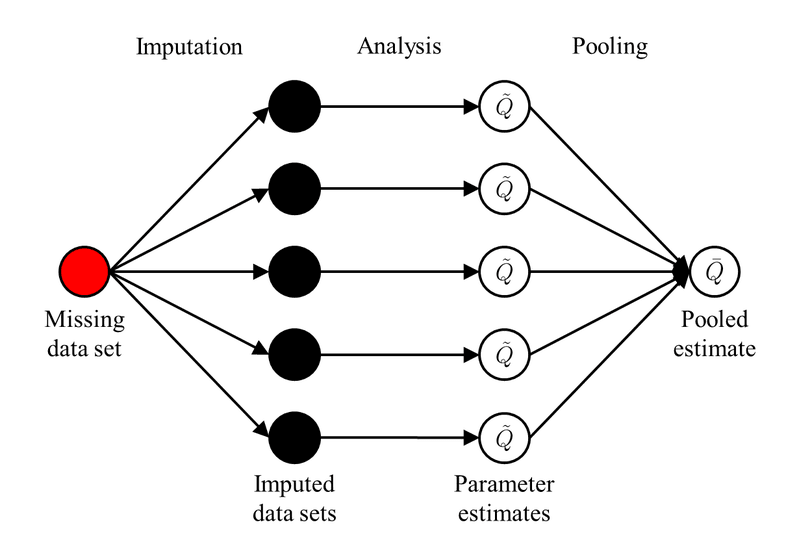
- Identify causes of missing data (data entry errors, sensor malfunctions, non-responses)
- Implement imputation methods to fill gaps (mean imputation, regression imputation, multiple imputation)
- Utilize machine learning algorithms to predict missing values based on other available features
- Consider the impact of missing data on analysis and choose appropriate handling strategies (listwise deletion, pairwise deletion)
Removing duplicates
- Develop criteria for identifying duplicate records in datasets
- Implement fuzzy matching algorithms to detect near-duplicate entries
- Use deterministic record linkage techniques to merge duplicate records
- Preserve original data by creating a separate cleaned dataset without duplicates
Correcting inconsistencies
- Standardize data formats across different sources (date formats, units of measurement)
- Resolve conflicting information within and across datasets
- Implement data validation rules to prevent future inconsistencies
- Use regular expressions to clean and standardize text data (addresses, phone numbers)
Standardizing formats
- Convert all date and time data to a consistent format (ISO 8601)
- Normalize units of measurement across the dataset (metric vs imperial)
- Standardize text case for categorical variables (lowercase, title case)
- Create lookup tables for mapping inconsistent values to standardized formats
Data quality assessment
- Data quality assessment plays a vital role in predictive analytics by ensuring the reliability and accuracy of input data
- Regular quality assessments help identify potential issues early in the analytics process, saving time and resources
- Implementing robust quality assessment practices leads to more trustworthy predictions and business insights
Data profiling techniques
- Conduct column profiling to analyze data types, unique values, and value distributions
- Perform cross-column analysis to identify relationships and dependencies between variables
- Use pattern analysis to detect anomalies and inconsistencies in data structures
- Implement semantic profiling to ensure data aligns with business rules and domain knowledge
Data quality metrics
- Calculate completeness metrics to measure the percentage of non-null values
- Assess accuracy by comparing data values to known reference data or external sources
- Measure consistency across related data elements and different datasets
- Evaluate timeliness to ensure data is up-to-date and relevant for analysis
Identifying outliers
- Apply statistical methods to detect outliers (z-score, interquartile range)
- Utilize machine learning techniques for multivariate outlier detection (isolation forests, local outlier factor)
- Visualize data distributions to identify potential outliers (box plots, scatter plots)
- Distinguish between true outliers and data errors through domain expertise and context analysis
Detecting anomalies
- Implement time series analysis techniques to identify anomalies in sequential data
- Use clustering algorithms to detect points that do not fit into any cluster
- Apply supervised anomaly detection methods when labeled data is available
- Develop custom anomaly detection rules based on business-specific criteria and thresholds
Data transformation
- Data transformation techniques are essential for preparing data for predictive modeling in business contexts
- Proper transformation enhances the performance of machine learning algorithms and improves model interpretability
- Selecting appropriate transformation methods depends on the specific requirements of the predictive task and the nature of the data
Normalization vs standardization
- Normalization scales features to a fixed range (typically 0 to 1) using the formula:
- Standardization transforms features to have zero mean and unit variance:
- Choose normalization when the distribution is not Gaussian or when you need bounded values
- Opt for standardization when comparing features with different scales or when using algorithms sensitive to feature magnitudes (SVM, K-means)
Feature scaling methods
- Apply min-max scaling to bound values within a specific range while preserving zero values
- Use robust scaling to handle outliers by scaling based on median and interquartile range
- Implement maximum absolute scaling to scale features by their maximum absolute value
- Consider quantile transformation for non-linear feature scaling, especially for skewed distributions
Encoding categorical variables
- Utilize one-hot encoding for nominal categorical variables with no inherent order
- Implement ordinal encoding for categorical variables with a clear ranking or order
- Apply target encoding to replace categorical values with the mean of the target variable
- Use binary encoding to represent categorical variables as binary digits, reducing dimensionality
![Handling missing values, Advanced methods for missing values imputation based on similarity learning [PeerJ]](https://storage.googleapis.com/static.prod.fiveable.me/search-images%2F%22Handling_missing_values_in_predictive_analytics%3A_causes_imputation_methods_machine_learning_and_strategies%22-fig-9-2x.jpg)
Handling imbalanced data
- Employ oversampling techniques to increase minority class samples (SMOTE, ADASYN)
- Implement undersampling methods to reduce majority class samples (random undersampling, Tomek links)
- Combine oversampling and undersampling in hybrid approaches (SMOTETomek)
- Adjust class weights in machine learning algorithms to give more importance to minority classes
Data integration
- Data integration is crucial for combining diverse data sources in predictive analytics projects
- Effective integration techniques enable businesses to create comprehensive datasets for more accurate predictions
- Proper data integration practices help overcome challenges related to data silos and inconsistent information across systems
Merging multiple sources
- Identify common keys or attributes across different data sources for joining
- Implement various join types (inner, left, right, full outer) based on the required outcome
- Handle conflicts when merging data with overlapping information
- Consider the temporal aspects of data when integrating time-sensitive information
Resolving schema conflicts
- Map equivalent fields across different schemas to create a unified structure
- Resolve naming conflicts by creating standardized field names
- Handle data type mismatches by converting to compatible formats
- Implement schema evolution techniques to accommodate changes in source data structures over time
Entity resolution techniques
- Develop blocking strategies to reduce the number of comparisons in large datasets
- Implement deterministic matching rules based on exact matches of key attributes
- Use probabilistic matching algorithms to handle uncertain or fuzzy matches
- Apply machine learning-based entity resolution methods for complex matching scenarios
Data reconciliation
- Identify and resolve discrepancies between integrated data sources
- Implement business rules to handle conflicting information
- Use data lineage tracking to understand the origin and transformations of data
- Develop reconciliation reports to document and communicate data integration outcomes
Data reduction
- Data reduction techniques are essential for managing large datasets in predictive analytics applications
- Effective reduction methods help improve model performance and reduce computational resources required
- Choosing appropriate data reduction strategies depends on the specific business problem and available data characteristics
Dimensionality reduction methods
- Apply Principal Component Analysis (PCA) to identify and retain the most important features
- Utilize t-SNE for visualizing high-dimensional data in lower-dimensional space
- Implement autoencoders for non-linear dimensionality reduction in deep learning applications
- Consider Linear Discriminant Analysis (LDA) for supervised dimensionality reduction tasks
Feature selection techniques
- Use filter methods to select features based on statistical measures (correlation, chi-squared test)
- Implement wrapper methods to evaluate feature subsets using model performance (recursive feature elimination)
- Apply embedded methods that combine feature selection with model training (Lasso, Ridge regression)
- Utilize domain expertise to guide feature selection based on business relevance and interpretability
Data sampling strategies
- Implement random sampling to create representative subsets of large datasets
- Use stratified sampling to maintain class distribution in classification problems
- Apply cluster sampling for datasets with natural groupings or hierarchies
- Consider adaptive sampling techniques that adjust sample size based on data complexity
Aggregation methods
- Utilize time-based aggregation for time series data (daily, weekly, monthly summaries)
- Implement spatial aggregation for geographic data (by region, city, or custom boundaries)
- Apply hierarchical aggregation methods for data with natural hierarchies (product categories)
- Use pivot tables and cross-tabulation for summarizing and analyzing multidimensional data
Data cleaning tools
- Selecting appropriate data cleaning tools is crucial for efficient and effective data preparation in predictive analytics
- The choice of tools depends on factors such as data volume, complexity, and team expertise
- Integrating data cleaning tools into existing analytics workflows enhances productivity and ensures consistent data quality
Open-source vs commercial tools
- Evaluate open-source options (OpenRefine, Trifacta Wrangler) for cost-effective data cleaning solutions
- Consider commercial tools (Tableau Prep, Alteryx) for enterprise-grade features and support
- Assess the total cost of ownership, including licensing, training, and maintenance
- Compare community support and documentation available for open-source and commercial tools
Programming languages for cleaning
- Utilize Python libraries (pandas, NumPy) for flexible and customizable data cleaning workflows
- Implement R packages (tidyr, dplyr) for statistical data cleaning and manipulation
- Use SQL for data cleaning tasks directly within databases
- Consider Julia for high-performance data cleaning in large-scale analytics projects
Automated data cleaning platforms
- Explore cloud-based platforms (Google Cloud Dataprep, AWS Glue) for scalable data cleaning
- Implement machine learning-powered cleaning tools (DataRobot, Paxata) for intelligent automation
- Utilize low-code/no-code platforms (Talend Data Preparation) for rapid data cleaning by non-technical users
- Assess the integration capabilities of automated platforms with existing data infrastructure
ETL tools for data cleaning
- Implement traditional ETL tools (Informatica PowerCenter, IBM InfoSphere DataStage) for comprehensive data integration and cleaning
- Utilize modern ELT tools (Fivetran, Stitch) for cloud-based data loading and transformation
- Consider open-source ETL frameworks (Apache NiFi, Talend Open Studio) for customizable data pipelines
- Evaluate real-time ETL tools (Striim, StreamSets) for cleaning streaming data in near real-time
Data cleaning best practices
- Adhering to data cleaning best practices ensures consistency and reliability in predictive analytics projects
- Implementing standardized processes for data cleaning improves collaboration and reproducibility of results
- Regular review and updating of data cleaning practices help businesses adapt to evolving data landscapes
Documentation and versioning
- Create detailed documentation of data cleaning steps and decisions made during the process
- Implement version control systems (Git) to track changes in data cleaning scripts and configurations
- Maintain a data dictionary that explains cleaned variables, their formats, and any transformations applied
- Develop a changelog to record major updates and modifications to the data cleaning pipeline
Iterative cleaning processes
- Implement an iterative approach to data cleaning, refining methods based on feedback and results
- Conduct regular data quality assessments to identify new issues or recurring problems
- Establish feedback loops between data scientists and domain experts to validate cleaning decisions
- Continuously update and improve data cleaning rules based on new insights and changing business requirements
Validation and verification
- Develop a comprehensive set of data validation rules based on business logic and domain knowledge
- Implement automated data quality checks at various stages of the data pipeline
- Conduct manual spot checks and audits to verify the effectiveness of automated cleaning processes
- Use statistical techniques to validate the impact of data cleaning on overall data quality and model performance
Handling sensitive information
- Implement data masking techniques to protect personally identifiable information (PII) during cleaning
- Develop protocols for securely handling and storing sensitive data throughout the cleaning process
- Ensure compliance with data protection regulations (GDPR, CCPA) when cleaning and transforming sensitive data
- Implement role-based access controls to limit exposure of sensitive information during data cleaning activities
Challenges in data cleaning
- Addressing challenges in data cleaning is essential for maintaining data quality in complex business environments
- Overcoming these challenges requires a combination of technical solutions and organizational strategies
- Continuous improvement in data cleaning practices helps businesses stay ahead of evolving data quality issues
Big data cleaning issues
- Develop distributed data cleaning algorithms to handle large-scale datasets efficiently
- Implement parallel processing techniques to speed up cleaning operations on big data platforms
- Address data velocity challenges by integrating real-time cleaning processes into data streams
- Manage data variety issues by developing flexible cleaning pipelines that can handle diverse data types and formats
Real-time data cleaning
- Implement stream processing frameworks (Apache Flink, Apache Kafka) for cleaning data in motion
- Develop low-latency cleaning algorithms that can operate within strict time constraints
- Utilize in-memory computing techniques to accelerate real-time data cleaning operations
- Balance the trade-off between cleaning thoroughness and processing speed in real-time scenarios
Domain-specific cleaning requirements
- Tailor data cleaning approaches to specific industry requirements (healthcare, finance, retail)
- Develop custom cleaning rules and algorithms based on domain-specific data quality standards
- Collaborate with subject matter experts to identify and address unique data quality issues in specialized fields
- Implement industry-specific data validation checks and cleaning procedures
Balancing automation and manual review
- Develop hybrid cleaning approaches that combine automated processes with human oversight
- Implement confidence scoring mechanisms to flag uncertain cleaning decisions for manual review
- Create user-friendly interfaces for data stewards to efficiently review and correct automated cleaning results
- Establish clear guidelines for when manual intervention is necessary in the data cleaning process