One of the neat things about data is that we can get information from it! By examining it closely, we can identify trends, make connections and address problems. This is true in almost every field, from science to history.
One or a few data points may not be enough to create a coherent conclusion—you could be dealing with an outlier, and it's difficult to see trends. With larger data sets (often very large data sets, known as big data), you can establish more comprehensive patterns. However, it is important to note that correlation does not necessarily indicate that a casual relationship exists. A correlation just suggests areas for additional research to understand the exact nature of the relationship between
As the world gets bigger and more interconnected, a vast amount of data becomes more accessible and needs to be tracked.
🔗 Take a look at this visual of global shipping in the year 2012!
To create this graphic, researchers had to track millions of shipments over months. This is just one example of the rapidly-growing need for big data processing.
As the data sets get larger and larger, computers become a necessary tool to help us process it. They can process data faster and with less error than humans. (Imagine sorting through all of that shipping data by hand...). At larger scales, you may even need multiple computers or parallel systems to process all the data involved.
This demand has even led to the creation of server farms, areas where many large computers are housed for the purpose of meeting intense processing needs such as dealing with big data sets. Server farms are often located in large data centers, but they can also be stored in much smaller rooms as well.

When you're working with data sets in a system, you need to consider how scalable the system is. Scalability is the ability of a resource to adapt as the scale of the data it uses increases (or decreases). Although a scalable resource might require, for example, more servers or access points, it won't have to change the basics of how it operates. The more scalable a system is, the more data you can process and store within it.
In terms of data processing, you're only as good as the tools you have to work with. The more powerful your computer is, the better the data processing you'll be able to do.
One of the ways to make processing data easier is through the use of metadata.

Metadata
Metadata is data about data.
It's like the packing label on a box in the mail or the tags on a piece of clothing: it gives you information about the item it's attached to. For example, the metadata for a YouTube video could include the title, creator, description, and tags for the video, as well as when it was uploaded and how large it is.
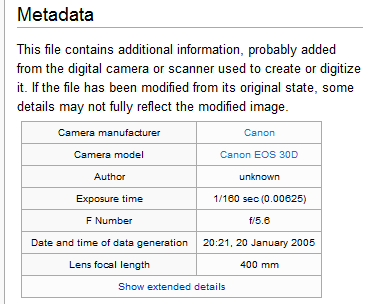
If you change or delete the metadata, it doesn't affect the data itself. For example, if you change the description of a video, you don't affect the video itself.
Metadata is used to help find and organize data: you can use it to sort and group it. It can also provide additional information to help you use your data more effectively. For example, metadata that tells you when a video was uploaded or a post was made can help you decide whether or not the information you're looking at is outdated.
Problems Collecting and Processing Data
Regardless of how large they are, data sets can be challenging to deal with. Fortunately, computers can help us deal with some of these issues.
For example, data may not be uniform due to its collection process.
Imagine you made a Google Survey to find out what class people like the most at your school. You create a form that looks like this:
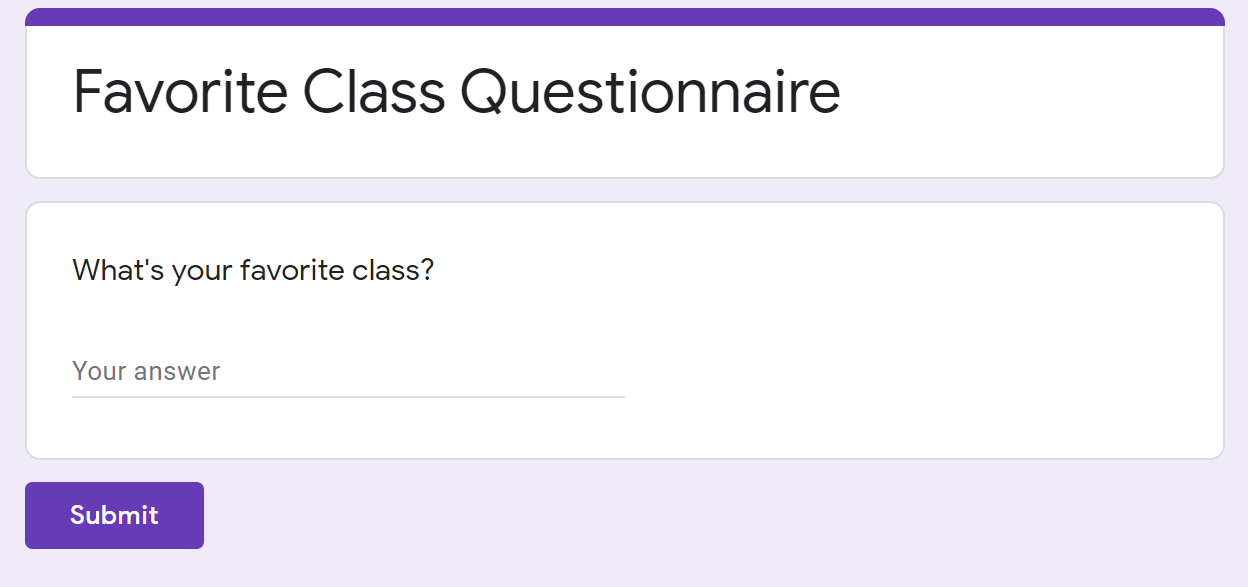
Looking at the results, you see that a lot of people say AP Computer Science Principles is their favorite class! However, they don't all choose to say it the same way.

...the list goes on. This lack of uniformity could make it very difficult to work with your data, especially if you're potentially looking at hundreds of entries.
You might also run into this uniformity issue if you're compiling data from many different resources, where formatting standards may be a little different. For example, let's say you're working with a friend to track what time of day people find the most productive, but you're writing down results using 12 hour time while they're using 24 hour time. (Probably just to be difficult.)
The way that computers deal with this is through a process known as cleaning data. This process makes data uniform by eliminating all of these differences. Cleaning data can also help flag or remove invalid and incomplete data.
Data Biases
Data sets may be biased for a variety of reasons.
Taking the favorite class questionnaire as an example, there are many ways in which bias could sneak in:
- People have to take the initiative to fill out this form, which means they're more likely to have strong opinions about the topic when compared to the rest of the population. People who don't really have a favorite class or don't care about school in general won't be all that represented in the study, skewing results for your school overall.
- This survey just looks at one school, which could also bias results. Your AP Comp Sci teacher might just be a really good teacher, for example, so people might like the class for the teacher rather than the subject.
- The context of your survey might also impact results. The results you get if you post this survey in your AP Comp Sci class could be completely different from the results you'd get if you posted it in a Basketball group chat.
- Data can also be biased on societal lines such as race and gender.
Just collecting more data won't make this problem go away by itself; you need to identify potential biases in your data and take steps to correct them, such as surveying people from different schools or classes.
Vocabulary
The following words are mentioned explicitly in the College Board Course and Exam Description for this topic.Term | Definition |
|---|---|
bias | Prejudice or systematic error in computing innovations that can result from algorithms or data, reflecting existing human prejudices. |
causal relationship | A relationship where one variable directly causes changes in another variable, as opposed to merely being correlated. |
conclusion | A judgment or decision reached by analyzing and interpreting data from one or more sources. |
correlation | A relationship between two variables in data where changes in one variable are associated with changes in another. |
data | Information represented in a form that can be processed by a program, such as numbers, text, or records. |
data cleaning | The process of making data uniform and consistent without changing their meaning, such as standardizing abbreviations, spellings, and capitalizations. |
data set | A collection of related data values organized for processing and analysis. |
data sources | Origins or locations from which data are collected or obtained. |
facts | Specific pieces of information or observations that form the basis of data. |
incomplete data | Data sets that are missing required information or values. |
information | The collection of facts and patterns extracted from data that provides meaning and insight. |
invalid data | Data that does not meet required standards or formats and cannot be properly processed. |
metadata | Data that describes other data, such as the date of creation or file size of an image, used for finding, organizing, and managing information. |
parallel systems | Computing systems that process data simultaneously across multiple processors or computers to handle large data sets efficiently. |
pattern | Regularities or recurring structures that emerge from data when processed and analyzed using programs. |
primary data | The main data itself, which remains unchanged even if its associated metadata is modified or deleted. |
scalability | The ability of a solution to maintain or improve performance as the problem size or computational resources increase. |
trends | General directions or tendencies in data over time or across categories. |
variable | A named container in a program that stores a value which can be changed through assignment. |
Frequently Asked Questions
How do I extract useful information from a data set for my AP project?
Start by asking what question you want the data to answer—trends, correlations, or a specific problem. Then: - Inspect and clean the data (data cleaning): fix typos, normalize formats, handle missing or invalid values. - Explore with summary stats and visualizations (exploratory data analysis): means, medians, histograms, scatterplots to identify patterns and outliers. - Use metadata to add context (EK DAT-2.B.*): timestamps, source, units, and provenance help you filter and combine data correctly. - Combine sources only when comparable (data integration); document provenance and beware sampling bias and other sources of bias (EK DAT-2.C.5). - Interpret carefully: report correlations but don’t claim causation without extra research (EK DAT-2.A.3). - Consider scalability: large sets may need aggregation, parallel processing, or sampling (EK DAT-2.C.6–C.8). For AP work, clearly describe your cleaning, metadata, integration, and limitations in your Create task and cite any external data (avoid plagiarism). Want a step-by-step checklist and examples? See the Topic 2.3 study guide (https://library.fiveable.me/ap-computer-science-principles/unit-2/extracting-information-data/study-guide/EFuLgc6tL71cegDFjXRl) and unit resources (https://library.fiveable.me/ap-computer-science-principles/unit-2). For extra practice, try the 1000+ practice problems (https://library.fiveable.me/practice/ap-computer-science-principles).
What's the difference between data and information in computer science?
Data are raw facts or measurements—numbers, text, pixels, timestamps—stored digitally. Information is what you get after processing or analyzing that data: the facts and patterns you extract (trends, correlations, summaries) that help answer a question or solve a problem (EK DAT-2.A.1, EK DAT-2.A.2). For example, individual daily temperatures are data; the weekly average and a warming trend are information. Remember: correlation in information doesn’t prove causation (EK DAT-2.A.3), and you often need to combine sources or clean data first (EK DAT-2.C.2, EK DAT-2.C.4). Metadata are “data about data” (EK DAT-2.B.1) and help organize or make data more useful without changing the primary data. This distinction is tested in AP CSP under Topic 2.3 (Big Idea 2). For a quick review, check the Topic 2.3 study guide on Fiveable (https://library.fiveable.me/ap-computer-science-principles/unit-2/extracting-information-data/study-guide/EFuLgc6tL71cegDFjXRl) and practice questions (https://library.fiveable.me/practice/ap-computer-science-principles).
I'm confused about what metadata actually is - can someone explain with examples?
Metadata = data about data. In other words, it describes or helps manage the primary data without changing it (EK DAT-2.B.1–2). Examples: for a photo the pixels are the data; the metadata might include date/time, GPS location, file size, camera model, or image resolution. For a web page the data is the page content; the metadata might be HTML meta tags (keywords, author), URL, or last-modified timestamp. For a dataset row, the data values are measurements; metadata can document column names, units, data provenance (where/how it was collected), and valid ranges (EK DAT-2.B.3–5). Why it matters for the exam: metadata helps you find, organize, clean, and combine data sources (LO DAT-2.B; EK DAT-2.A.4, DAT-2.C.2). It’s also safe to change metadata without altering the main data (EK DAT-2.B.2). For a quick Topic 2.3 review and examples, see the Fiveable study guide (https://library.fiveable.me/ap-computer-science-principles/unit-2/extracting-information-data/study-guide/EFuLgc6tL71cegDFjXRl). Need practice? Fiveable’s AP practice problems page has lots of questions (https://library.fiveable.me/practice/ap-computer-science-principles).
When should I use correlation vs causation when analyzing data trends?
Use correlation when you’re describing patterns in data—e.g., two variables move together (positive/negative) or have a statistical relationship you found by analyzing a dataset. That’s exactly what EK DAT-2.A.3 warns: digitally processed data may show correlation, but it doesn’t prove one variable caused the other. Use causation only when you have evidence that one variable directly influences another—typically from controlled experiments, randomized trials, or strong causal analysis that rules out confounding factors and bias (EK DAT-2.C.5). On the AP exam, you should be able to recognize correlations in data and explain why they don’t imply causation unless additional research supports a causal link (Topic 2.3). For practice on identifying these distinctions, see the Topic 2.3 study guide (https://library.fiveable.me/ap-computer-science-principles/unit-2/extracting-information-data/study-guide/EFuLgc6tL71cegDFjXRl) and try problems at (https://library.fiveable.me/practice/ap-computer-science-principles).
What's the syntax for cleaning messy data in a program?
There isn’t one “syntax” for cleaning data—cleaning is a process you write with whatever language you’re using. The AP idea is that cleaning makes data uniform without changing meaning (EK DAT-2.C.4). Common operations (and tiny pseudocode examples) you’ll write into a program: - Trim whitespace: value = value.trim() - Normalize case: value = value.lower() or value.upper() - Replace equivalents: if value in ["St.", "St", "Street"]: value = "Street" - Handle missing data: if value == "" or value == null: value = "UNKNOWN" or drop row - Validate types/ranges: if not isNumber(age) or age < 0: flagError() - Parse/standardize formats: date = parseDate(rawDate, formats) - Aggregate/merge sources carefully and keep metadata On the exam you may describe these steps or show code-like algorithms (no specific language required). For practice on how to write/describe cleaning steps for AP tasks, check the Topic 2.3 study guide (https://library.fiveable.me/ap-computer-science-principles/unit-2/extracting-information-data/study-guide/EFuLgc6tL71cegDFjXRl) and try practice problems (https://library.fiveable.me/practice/ap-computer-science-principles).
Why does my data analysis show correlation but my teacher says it's not causation?
Correlation just means two variables change together—your analysis found a pattern, which is valid info (EK DAT-2.A.1–2). Causation means one variable actually causes the other to change. You can get correlation without causation for several reasons: a hidden confounding variable causes both, the data source is biased or incomplete (EK DAT-2.C.2, EK DAT-2.C.5), or the relationship is coincidental. The CED explicitly says digitally processed data may show correlation but that doesn’t prove causality; you need additional research (EK DAT-2.A.3)—e.g., controlled experiments, longitudinal studies, or combining multiple data sources (EK DAT-2.A.4) to rule out confounders. For AP prep, study Topic 2.3 in the course guide (https://library.fiveable.me/ap-computer-science-principles/unit-2/extracting-information-data/study-guide/EFuLgc6tL71cegDFjXRl) and try practice problems (https://library.fiveable.me/practice/ap-computer-science-principles) to see examples of sampling bias, metadata issues, and how conclusions are limited by data.
How do I combine data from multiple sources without messing up my results?
Short answer: be deliberate—track provenance, standardize, validate, and document every step so combining sources doesn’t introduce errors or bias. How to do it (quick checklist): 1. Record provenance/metadata for each source (who collected it, when, how)—this helps judge trustworthiness (EK DAT-2.A.4, DAT-2.B.1). 2. Clean and normalize fields (consistent units, spellings, capitalization) without changing meaning (EK DAT-2.C.4). 3. Validate types and ranges (remove/flag invalid or duplicate rows). 4. Handle missing data explicitly: impute, exclude, or analyze with methods that account for gaps (EK DAT-2.C.2). 5. Align schemas before joining (keys, timestamps, aggregations) and use joins that match your analysis goal (inner vs. left join). 6. Check for bias introduced by source selection and scale issues (EK DAT-2.C.5, CED notes on scalability). For AP prep, focus on describing what info you can extract and the challenges of integration (LO DAT-2.A, LO DAT-2.C). See the Topic 2.3 study guide for examples (https://library.fiveable.me/ap-computer-science-principles/unit-2/extracting-information-data/study-guide/EFuLgc6tL71cegDFjXRl) and practice problems (https://library.fiveable.me/practice/ap-computer-science-principles).
What are the main challenges when processing large data sets?
Main challenges when processing large data sets - Data quality: you often need to clean data (normalize spellings/capitalization, fix invalid entries, fill or handle missing data) so it’s uniform without changing meaning (EK DAT-2.C.2, EK DAT-2.C.3–4). - Integration: one source usually isn’t enough—combining different sources raises format and provenance issues (EK DAT-2.A.4, keywords: data integration, data provenance). - Bias & validity: the source or collection method can create sampling bias; more data doesn’t automatically remove bias (EK DAT-2.C.5). - Scale & performance: very large sets may be too big for one computer and need parallel systems or distributed storage; scalability of tools determines what analyses are feasible (EK DAT-2.C.6–8, keywords: scalability, parallel processing). - Tool and user limits: processing depends on users’ skills and tool capabilities (EK DAT-2.C.1). These are core AP ideas for Topic 2.3—review the study guide (https://library.fiveable.me/ap-computer-science-principles/unit-2/extracting-information-data/study-guide/EFuLgc6tL71cegDFjXRl) and practice problems (https://library.fiveable.me/practice/ap-computer-science-principles) for examples you might see on the exam.
I don't understand how metadata helps organize information - can someone break it down?
Think of metadata as labels and facts about your data that make the data usable and searchable. In AP terms, metadata = “data about data” (LO DAT-2.B, EK DAT-2.B.1). For a photo the pixels are the primary data; metadata might include date, GPS, file size, and tags. That metadata lets you find photos by date or place, sort by size, filter by camera type, or combine datasets from different sources (EK DAT-2.B.3, EK DAT-2.B.4, EK DAT-2.B.5). Important: changing metadata doesn’t change the original data (EK DAT-2.B.2), but it can change how easily you can use it (e.g., adding consistent tags helps data integration and cleaning). On the exam, expect questions about how metadata supports finding, organizing, and managing information (LO DAT-2.B). For a quick refresher, check the Topic 2.3 study guide (https://library.fiveable.me/ap-computer-science-principles/unit-2/extracting-information-data/study-guide/EFuLgc6tL71cegDFjXRl) and practice problems (https://library.fiveable.me/practice/ap-computer-science-principles).
How do I write code to handle incomplete or invalid data entries?
Think of handling bad data as three steps: detect it, decide what to do, and document it. - Detect: validate types/ranges and required fields (e.g., check nulls, regex for emails, numeric ranges). Use explicit checks or try/except for conversions. - Decide: either fix (clean/normalize), fill (impute a default or mean), or drop the record. Choose based on how much is missing and the analysis goal (EK DAT-2.C.2, EK DAT-2.C.4). - Document: log changes, keep metadata about what you removed/filled (EK DAT-2.B.1, EK DAT-2.B.3). Simple pattern (pseudocode): count = 0 for row in data: if missing_required(row) or invalid_format(row): log_problem(row) if can_impute(row): row = impute(row) else: continue # skip bad record clean_row = normalize(row) process(clean_row) count += 1 On the AP exam, you should be able to describe these tradeoffs (data loss vs. bias) and why cleaning preserves meaning (CED EK DAT-2.C.*). For more examples and practice problems, see the Topic 2.3 study guide (https://library.fiveable.me/ap-computer-science-principles/unit-2/extracting-information-data/study-guide/EFuLgc6tL71cegDFjXRl) and unit resources (https://library.fiveable.me/ap-computer-science-principles/unit-2). Fiveable’s practice questions are great for trying these ideas (https://library.fiveable.me/practice/ap-computer-science-principles).
What's the difference between cleaning data and changing the meaning of data?
Cleaning data means making the entries uniform and usable without altering what they represent. For example, replacing "NY", "N.Y.", and "New York" with a single standard label, fixing capitalization, or removing duplicate rows—these are data normalization/validation steps that preserve meaning (EK DAT-2.C.4, EK DAT-2.C.3). Changing the meaning of data is when you alter values or interpretations so they no longer reflect the original facts—e.g., converting reported ages into different age categories without recording how you binned them, or overwriting a timestamp with a different date. That can introduce bias or false conclusions (EK DAT-2.C.5). Cleaning improves accuracy and makes combining sources easier (EK DAT-2.A.4); changing meaning risks invalidating any trends or correlations you extract. For more AP-aligned practice and examples, check the Topic 2.3 study guide (https://library.fiveable.me/ap-computer-science-principles/unit-2/extracting-information-data/study-guide/EFuLgc6tL71cegDFjXRl) and try problems at (https://library.fiveable.me/practice/ap-computer-science-principles).
Why is bias still a problem even when I collect more data?
More data doesn't automatically remove bias because bias comes from how the data were collected, not just how much you have. If your sample over- or under-represents certain groups (sampling bias) or comes from a limited source, adding more of the same kind of data just reinforces the same skewed view (EK DAT-2.C.5). Other issues—missing or invalid data, inconsistent formats, or unrepresentative metadata—can also create biased results even in huge datasets (EK DAT-2.C.2, DAT-2.B.4). Cleaning and combining diverse sources helps, but you must deliberately fix collection methods (change who or how you sample), validate data, and check for confounding variables before assuming correlations imply causation (EK DAT-2.A.3). For AP review, focus on sampling bias, data provenance, and cleaning—these are tested in Topic 2.3 (see the topic study guide (https://library.fiveable.me/ap-computer-science-principles/unit-2/extracting-information-data/study-guide/EFuLgc6tL71cegDFjXRl) and unit overview (https://library.fiveable.me/ap-computer-science-principles/unit-2)). For extra practice, try the practice problems (https://library.fiveable.me/practice/ap-computer-science-principles).
When do I need to use parallel systems instead of just one computer for data processing?
Use parallel systems when a single computer can’t handle the size or time requirements of the data task. The CED explicitly says large data sets are difficult to process on one machine and may require parallel systems (EK DAT-2.C.7)—that’s a scalability issue (EK DAT-2.C.8). Practical signs you need parallelism: - The dataset won’t fit in your computer’s memory or storage. - Processing on one machine would take too long (e.g., hours/days) but needs results faster. - The task can be split into independent parts (e.g., counting, filtering, MapReduce-style aggregations, training large ML models). - You must handle high-volume real-time streams. If work can be split and run concurrently, parallel processors or distributed systems speed things up and allow scaling. For AP CSP, be ready to explain that dataset size affects processing and that cleaning, integration, and bias issues still matter even with parallel systems (LO DAT-2.C). Review Topic 2.3 on Fiveable (study guide: https://library.fiveable.me/ap-computer-science-principles/unit-2/extracting-information-data/study-guide/EFuLgc6tL71cegDFjXRl) and practice problems (https://library.fiveable.me/practice/ap-computer-science-principles) for examples.
How do I identify trends and patterns in data for the AP exam?
To spot trends and patterns for the AP exam, follow a simple process: clean → explore → check → interpret. - Clean data first: fix inconsistencies, fill/remove missing values, normalize formats (EK DAT-2.C.4, EK DAT-2.C.2–3). - Explore with summaries and visuals: compute means/medians, make line charts for trends over time, histograms for distributions, and scatterplots to see relationships (EK DAT-2.A.1–2). - Check relationships: calculate correlation to quantify associations but remember correlation ≠ causation (EK DAT-2.A.3). Ask if you need additional sources to support conclusions (EK DAT-2.A.4). - Use metadata to help interpret results (EK DAT-2.B.1, EK DAT-2.B.4) and watch for bias or sampling issues that can mislead (EK DAT-2.C.5). - Consider scalability: big data may need different tools or parallel processing (EK DAT-2.C.6–8). On the exam expect questions about identifying trends, correlation vs causation, data cleaning, and metadata (Big Idea 2). Review the Topic 2.3 study guide (https://library.fiveable.me/ap-computer-science-principles/unit-2/extracting-information-data/study-guide/EFuLgc6tL71cegDFjXRl) and practice problems (https://library.fiveable.me/practice/ap-computer-science-principles).
What does scalability mean when working with big data sets?
Scalability means how well a system can handle growing amounts of data (or more users) without failing or becoming impractically slow. For big data sets, it’s about whether your hardware, software, and algorithms can be increased (scaled up or out) so you can still clean, combine, analyze, and store data efficiently. If a dataset grows beyond what one computer can process, you need parallel systems or distributed storage/processing (EK DAT-2.C.7, EK DAT-2.C.8). Scalability affects what information you can extract (more data can give clearer trends but also bigger cleaning and bias problems—EK DAT-2.C.2, .5, .6). On the AP exam expect questions about limits of single computers, need for parallel processing, and trade-offs in processing vs. storage (Topic 2.3). For review, see the Topic 2.3 study guide (https://library.fiveable.me/ap-computer-science-principles/unit-2/extracting-information-data/study-guide/EFuLgc6tL71cegDFjXRl) and practice problems (https://library.fiveable.me/practice/ap-computer-science-principles).