Data parallel and SIMD models revolutionize parallel computing by performing identical operations on multiple data elements simultaneously. These approaches leverage vector processing units and specialized instructions to boost performance, making them crucial for tasks like scientific simulations and multimedia processing.
Implementing data parallel algorithms requires careful code restructuring and optimization. Techniques like proper data alignment, efficient memory access patterns, and SIMD-friendly data structures are key to maximizing performance. Understanding performance metrics and architecture-specific optimizations is essential for achieving peak efficiency in parallel programs.
Data Parallel and SIMD Programming
Principles and Characteristics
- Data parallelism performs identical operations on multiple data elements simultaneously exploits inherent parallelism in computational tasks
- Single Instruction, Multiple Data (SIMD) executes a single instruction on multiple data points concurrently
- SIMD architectures utilize vector processing units perform operations on multiple data elements in one clock cycle
- Data parallel models employ vectorization techniques perform operations on vectors or arrays of data rather than individual elements
- Efficiency depends on regularity of data structures and uniformity of operations across data elements
- High-level abstractions express parallelism (parallel loops, array operations)
- SIMD instructions implemented as extensions to existing instruction set architectures (SSE, AVX, NEON)
- SSE (Streaming SIMD Extensions) for Intel processors
- AVX (Advanced Vector Extensions) for Intel and AMD processors
- NEON for ARM processors
SIMD Operations and Data Structures
- SIMD instructions operate on vector registers hold multiple data elements of the same type
- 4 single-precision floats
- 8 16-bit integers
- Common SIMD operations include:
- Element-wise arithmetic (addition, multiplication)
- Logical operations (AND, OR, XOR)
- Comparisons (greater than, equal to)
- Data movement between vector registers and memory
- Vector registers typically 128, 256, or 512 bits wide depending on the SIMD instruction set
- Data alignment crucial for efficient SIMD implementation
- Properly aligned data allows for faster memory access
- Misaligned data may require additional instructions to load and store
Implementing Data Parallel Algorithms
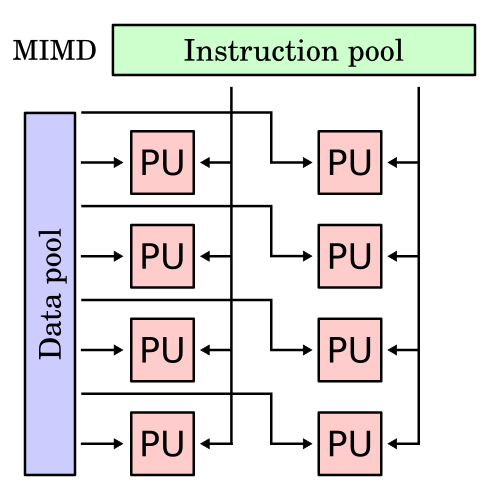
SIMD Libraries and Tools
- SIMD libraries provide C/C++ function calls map directly to SIMD instructions
- Intel Intrinsics
- ARM NEON intrinsics
- Higher-level libraries offer optimized implementations of common algorithms using SIMD instructions internally
- Intel MKL (Math Kernel Library)
- OpenCV (Open Source Computer Vision Library)
- Vectorization techniques help compilers generate efficient SIMD code
- Loop unrolling exposes parallelism by repeating loop body multiple times
- Explicit vectorization directives (pragma omp simd) guide compiler optimizations
Code Restructuring and Optimization
- Implementing data parallel algorithms with SIMD involves restructuring code to expose parallelism
- Enable efficient use of vector operations by:
- Aligning data structures to vector register boundaries
- Organizing data in contiguous memory blocks for efficient loading
- Consider memory access patterns to maximize cache utilization
- Stride-1 access patterns (accessing consecutive elements) perform best
- Avoid scatter-gather operations when possible
- Utilize SIMD-friendly data structures
- Structure of Arrays (SoA) instead of Array of Structures (AoS)
- Allows for more efficient SIMD operations on homogeneous data
- Implement algorithm-specific optimizations
- Exploit symmetry in matrix operations
- Use lookup tables for complex functions when appropriate
Performance and Efficiency of Parallel Programs

Performance Metrics and Analysis
- Speedup measures performance improvement relative to scalar implementation
- Efficiency quantifies how well parallel resources utilized
- Vectorization efficiency expresses SIMD resource utilization
- Percentage of peak theoretical performance achieved
- Profiling tools and hardware performance counters measure:
- SIMD instruction utilization
- Cache behavior (hit rates, miss rates)
- Memory bandwidth usage
- Theoretical frameworks analyze potential speedup and scalability
- Amdahl's Law for fixed problem size
- Gustafson's Law for scaled problem size
- Roofline model analyzes performance in terms of:
- Computational intensity (operations per byte of memory traffic)
- Memory bandwidth limitations
Factors Affecting Efficiency
- Load balancing critical for efficiency in data parallel programs
- Ensures even distribution of work across processing units
- Particularly important for heterogeneous data or irregular computations
- Data locality impacts performance more in SIMD programs
- Higher bandwidth requirements of vector operations
- Efficient cache utilization crucial for maintaining performance
- Memory bandwidth often bottleneck in data parallel programs
- Optimize data movement between memory and processor
- Use techniques like data compression or in-memory computation when appropriate
- Synchronization overhead can limit scalability
- Minimize synchronization points in algorithm design
- Use lock-free data structures when possible
Optimizing Data Parallel Programs
Architecture-Specific Optimizations
- SIMD instruction sets have varying vector widths and capabilities
- SSE: 128-bit vectors
- AVX: 256-bit vectors
- AVX-512: 512-bit vectors
- Leverage auto-vectorization capabilities of modern compilers
- Use appropriate compiler flags (e.g., -O3, -march=native)
- Write vectorization-friendly code (simple loop structures, avoid dependencies)
- Manual vectorization using intrinsics or assembly code for peak performance
- Critical code sections
- Complex algorithms not easily auto-vectorized
- Memory alignment and padding techniques ensure efficient SIMD memory access
- Align data structures to cache line boundaries (typically 64 bytes)
- Add padding to avoid false sharing in multi-threaded environments
Advanced Optimization Strategies
- Exploit Instruction-level parallelism (ILP) in conjunction with SIMD
- Interleave independent operations to maximize processor utilization
- Use techniques like software pipelining for improved instruction scheduling
- Optimize for GPU architectures using CUDA or OpenCL
- Consider GPU-specific memory hierarchies (global memory, shared memory, registers)
- Utilize GPU-specific features like warp-level operations or tensor cores
- Implement heterogeneous computing approaches
- Combine CPUs and GPUs or other accelerators
- Optimize different parts of algorithms for most suitable architecture
- Utilize advanced compiler optimizations
- Function inlining reduces function call overhead
- Loop interchange optimizes memory access patterns
- Constant propagation and folding for compile-time evaluation of expressions