Bubble Sort, Selection Sort, and Insertion Sort are simple yet crucial sorting algorithms. They form the foundation for understanding more complex sorting methods. While not efficient for large datasets, these algorithms shine in specific scenarios and are invaluable for learning basic sorting concepts.
Each algorithm has unique characteristics that make it suitable for different situations. Bubble Sort and Insertion Sort adapt well to partially sorted data, while Selection Sort minimizes swaps. Understanding their strengths and weaknesses helps in choosing the right algorithm for specific tasks.
Sorting Algorithms Comparison
Characteristics and Efficiency
- Bubble Sort compares adjacent elements and swaps them if they are in the wrong order, repeating until no swaps are needed
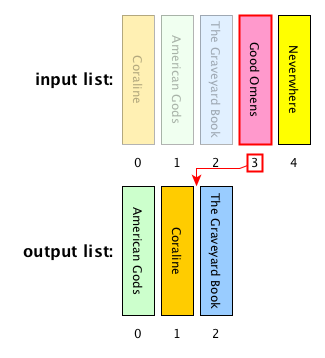
- Selection Sort divides the input list into sorted and unsorted portions, repeatedly selecting the smallest element from the unsorted portion
- Insertion Sort builds the final sorted array one item at a time, growing a sorted output list
- All three algorithms have quadratic time complexity in worst and average cases (inefficient for large datasets)
- Bubble Sort and Insertion Sort perform better on partially sorted arrays (adaptive algorithms)
- Insertion Sort generally outperforms Bubble Sort and Selection Sort for small datasets or nearly sorted arrays
- Bubble Sort and Insertion Sort preserve the relative order of equal elements (stable sorting algorithms)
- Example: Sorting a list of students by grade, maintaining original order for students with the same grade
- Selection Sort does not preserve relative order of equal elements (not stable)
- Example: Sorting a deck of cards by rank, potentially changing the order of suits for cards with the same rank
Algorithm Implementations
- Bubble Sort implementation:
</>Code
for i = 0 to n-1 for j = 0 to n-i-1 if arr[j] > arr[j+1] swap arr[j] and arr[j+1] - Selection Sort implementation:
</>Code
for i = 0 to n-1 min_idx = i for j = i+1 to n if arr[j] < arr[min_idx] min_idx = j swap arr[i] and arr[min_idx] - Insertion Sort implementation:
</>Code
for i = 1 to n-1 key = arr[i] j = i - 1 while j >= 0 and arr[j] > key arr[j+1] = arr[j] j = j - 1 arr[j+1] = key
Time Complexities of Sorting Algorithms
Best, Average, and Worst-Case Scenarios
- Bubble Sort time complexities
- Best-case when input is already sorted
- Worst-case and average-case
- Selection Sort time complexities
- Consistently for best, average, and worst cases
- Performs the same number of comparisons regardless of input
- Insertion Sort time complexities
- Best-case when input is already sorted
- Worst-case and average-case
- Space complexity for all three algorithms (sort in-place, require constant additional memory)
Comparisons and Swaps Analysis
- Bubble Sort operations
- Performs comparisons in worst case
- Up to swaps in worst case
- Example: Sorting [5, 4, 3, 2, 1] requires 10 comparisons and 10 swaps
- Selection Sort operations
- Always performs comparisons
- Only swaps
- Example: Sorting [5, 4, 3, 2, 1] requires 10 comparisons but only 4 swaps
- Insertion Sort operations
- comparisons and swaps in worst case
- Significantly fewer in best case
- Example: Sorting [2, 1, 4, 3, 5] requires 4 comparisons and 3 swaps
Choosing the Right Sorting Algorithm
Dataset Characteristics
- Consider size of dataset
- Very small arrays (less than 10-20 elements) suitable for any of these algorithms due to simplicity and low overhead
- Example: Sorting a hand of cards in a card game
- Evaluate initial order of data
- Insertion Sort preferable for nearly sorted arrays or when elements received in a stream
- Example: Updating a sorted list of recent high scores in a game
- Assess importance of stability
- Choose Bubble Sort or Insertion Sort if maintaining relative order of equal elements crucial
- Example: Sorting a list of employees by department, then by seniority within each department
- Analyze cost of swapping elements
- Selection Sort preferable if swaps expensive (minimizes number of swaps)
- Example: Sorting large objects in memory where moving data expensive
Algorithm Properties
- Consider memory constraints
- All three algorithms suitable for situations with limited additional memory (in-place sorting)
- Example: Sorting on embedded systems with limited RAM
- Evaluate need for adaptivity
- Choose Bubble Sort or Insertion Sort for good performance on partially sorted data
- Example: Maintaining a sorted list of recently accessed files, where most recent files likely to remain at the top
- Assess online vs offline sorting requirements
- Insertion Sort well-suited for online sorting (elements received one at a time)
- Bubble Sort and Selection Sort require entire dataset available
- Example: Sorting a stream of incoming sensor data in real-time
Trade-offs in Sorting Algorithm Selection
Implementation and Performance Considerations
- Implementation complexity varies
- Bubble Sort and Selection Sort easier to implement than Insertion Sort
- Beneficial in educational or quick prototyping scenarios
- Example: Teaching basic sorting concepts to programming beginners
- Performance on small datasets differs
- Insertion Sort often outperforms Bubble Sort and Selection Sort for small arrays or partially sorted data
- Example: Sorting a small list of daily tasks by priority
- Stability requirements impact choice
- Bubble Sort or Insertion Sort preferred when stability needed
- Example: Sorting a list of search results by relevance while maintaining original order for equal relevance scores
- Adaptivity affects efficiency
- Bubble Sort and Insertion Sort adapt better to partially sorted arrays
- Potentially offer better performance in such cases
- Example: Sorting a mostly-sorted list of customer orders by date
Practical Applications and Educational Value
- Number of writes to memory varies
- Selection Sort performs fewest writes
- Beneficial in specific hardware environments or when write operations costly
- Example: Sorting data on flash memory where write operations are limited
- Online vs offline sorting capabilities differ
- Insertion Sort well-suited for online sorting
- Other two algorithms require entire dataset available
- Example: Sorting items in a production line as they arrive
- Educational value significant
- These algorithms often taught for simplicity and to illustrate basic sorting concepts
- Inefficient for large datasets but valuable for understanding fundamental principles
- Example: Demonstrating time complexity analysis and algorithm comparison in computer science courses