Sampling distributions are a key concept in statistics, bridging the gap between population parameters and sample statistics. They describe how sample statistics vary across multiple samples, enabling statisticians to make inferences about populations based on limited data.
Understanding sampling distributions is crucial for selecting appropriate statistical methods and interpreting results. This topic covers various types of sampling distributions, their properties, and applications in hypothesis testing and regression analysis, providing a foundation for statistical inference.
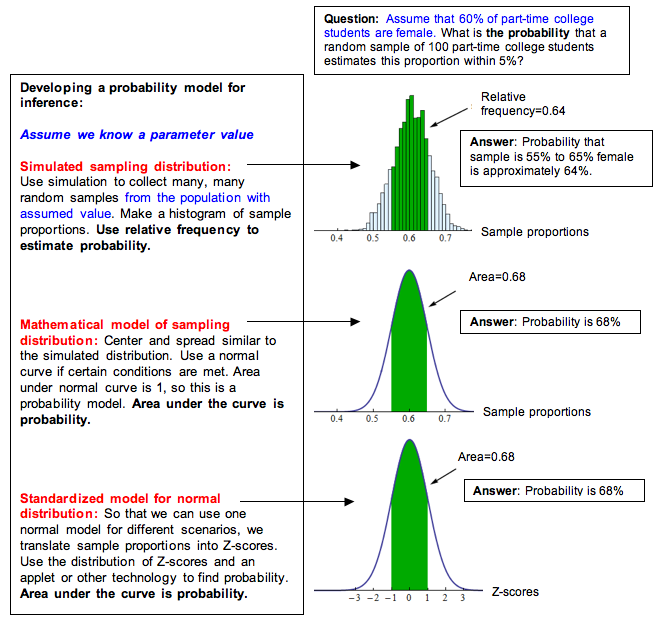
Definition of sampling distributions
- Sampling distributions form a crucial concept in theoretical statistics, bridging the gap between population parameters and sample statistics
- Understanding sampling distributions enables statisticians to make inferences about populations based on limited sample data
- These distributions describe the variability of sample statistics across multiple samples drawn from the same population
Population vs sample
- Population encompasses all possible observations or measurements of interest in a study
- Sample represents a subset of the population, typically used to estimate population characteristics
- Relationship between population and sample illustrated through the sampling process (random selection, stratification)
- Importance of representative samples in making valid statistical inferences about the population
Parameters vs statistics
- Parameters defined as numerical characteristics of the entire population (μ for mean, σ for standard deviation)
- Statistics calculated from sample data to estimate corresponding population parameters ( for sample mean, s for sample standard deviation)
- Sampling variability causes statistics to differ from sample to sample
- Sampling distributions describe the behavior of these sample statistics across repeated sampling
Types of sampling distributions
- Sampling distributions vary depending on the statistic of interest and the underlying population distribution
- Understanding different types of sampling distributions aids in selecting appropriate statistical methods for analysis
- Common sampling distributions include those for means, proportions, and variances
Distribution of sample mean
- Describes the behavior of sample means across repeated sampling from a population
- Shape influenced by the underlying population distribution and sample size
- Central Limit Theorem applies for large sample sizes, resulting in approximately normal distribution
- Standard error of the mean given by
- Applications in constructing confidence intervals and hypothesis tests for population means
Distribution of sample proportion
- Characterizes the variability of sample proportions in repeated sampling from a population
- Approximated by normal distribution when sample size is large and population proportion is not extreme
- Standard error of the proportion calculated as
- Used in analyzing categorical data and estimating population proportions
Distribution of sample variance
- Describes the behavior of sample variances across repeated sampling
- Follows a chi-square distribution when the population is normally distributed
- Degrees of freedom equal to n-1, where n is the sample size
- Applications in hypothesis testing for population variances and constructing confidence intervals
Properties of sampling distributions
- Understanding the properties of sampling distributions enables statisticians to make accurate inferences about population parameters
- These properties form the foundation for many statistical techniques used in data analysis and hypothesis testing
- Key properties include expected value, standard error, and shape characteristics
Expected value
- Expected value of a sampling distribution equals the corresponding population parameter
- Unbiasedness of estimators demonstrated when E(statistic) = parameter
- For sample mean: E() = μ
- For sample proportion: E(p) = π (population proportion)
- Importance in assessing the quality of estimators and their long-run behavior
Standard error
- Measures the variability or precision of a sampling distribution
- Calculated as the standard deviation of the sampling distribution
- Decreases as sample size increases, indicating improved precision
- Used in constructing confidence intervals and conducting hypothesis tests
- Relationship with margin of error in survey sampling and polling
Shape and symmetry
- Shape of sampling distribution influenced by underlying population distribution and sample size
- Tendency towards normality for large sample sizes (Central Limit Theorem)
- Symmetry properties affect the applicability of certain statistical methods
- Skewness and kurtosis measures used to describe deviations from normality
- Impact on the choice of parametric vs non-parametric statistical techniques
Central Limit Theorem
- Fundamental theorem in probability theory and statistics
- States that the sampling distribution of the mean approaches a normal distribution as sample size increases
- Applies regardless of the shape of the underlying population distribution
- Enables the use of normal distribution-based methods for large sample sizes

Conditions for CLT
- Independent and identically distributed (i.i.d.) random variables
- Finite population variance
- Sufficiently large sample size (generally n ≥ 30)
- Relaxation of normality assumption for underlying population
- Robustness to slight violations of assumptions in practice
Applications of CLT
- Justification for using normal distribution in many statistical analyses
- Construction of confidence intervals for population means
- Hypothesis testing for population parameters
- Quality control in manufacturing processes
- Risk assessment in finance and insurance
Standard error vs standard deviation
- Both measures of variability, but applied to different contexts
- Standard deviation describes variability in individual observations
- Standard error quantifies variability in sampling distributions of statistics
- Understanding the distinction crucial for proper interpretation of statistical results
Relationship between SE and SD
- Standard error typically smaller than standard deviation
- SE decreases as sample size increases, while SD remains constant
- For sample mean:
- Implications for precision of estimates and power of statistical tests
- Trade-off between sample size and precision in study design
Factors affecting SE
- Sample size: Larger samples lead to smaller standard errors
- Population variability: Greater population SD results in larger SE
- Sampling method: Complex sampling designs may increase SE
- Non-response and measurement error in surveys
- Stratification and clustering effects in complex sampling designs
Sampling distribution of differences
- Describes the behavior of differences between two sample statistics
- Important in comparative studies and hypothesis testing involving two groups
- Assumptions of independence between samples and normality of underlying distributions
Difference between two means
- Sampling distribution of follows normal distribution for large samples
- Standard error calculated as
- Applications in two-sample t-tests and confidence intervals for mean differences
- Pooled vs unpooled standard error depending on equal variance assumption
Difference between two proportions
- Sampling distribution of approximately normal for large samples
- Standard error given by
- Used in hypothesis testing for equality of proportions
- Applications in comparing treatment effects in clinical trials
- Considerations for small samples and extreme proportions
Sampling techniques
- Various methods used to select samples from a population
- Choice of technique affects the representativeness and precision of estimates
- Trade-offs between simplicity, cost, and statistical efficiency
Simple random sampling
- Each unit in the population has an equal probability of selection
- Unbiased method for selecting a representative sample
- Implemented using random number generators or systematic selection
- Advantages include simplicity and well-established statistical theory
- Limitations in practice due to lack of complete sampling frames
Stratified sampling
- Population divided into homogeneous subgroups (strata) before sampling
- Samples drawn independently from each stratum
- Improves precision for given sample size compared to simple random sampling
- Ensures representation of important subgroups in the sample
- Applications in survey research and population studies
Cluster sampling
- Population divided into clusters, typically based on geographic areas
- Clusters randomly selected, then all units within selected clusters sampled
- Cost-effective for geographically dispersed populations
- Reduces travel and administrative costs in field surveys
- Generally less precise than simple random sampling due to intra-cluster correlation
Sample size considerations
- Determining appropriate sample size crucial for balancing statistical power and resource constraints
- Impacts the precision of estimates and the ability to detect significant effects
- Involves trade-offs between desired level of accuracy and practical limitations
Effect on sampling distribution
- Larger sample sizes lead to narrower sampling distributions
- Improved precision of estimates with increasing sample size
- Reduction in standard error proportional to square root of sample size
- Diminishing returns in precision as sample size becomes very large
- Impact on statistical power and ability to detect smaller effect sizes
Precision vs cost trade-offs
- Increasing sample size improves precision but raises costs
- Optimal sample size depends on budget constraints and desired level of accuracy
- Consideration of marginal benefits of additional samples
- Strategies for allocating resources in multi-stage or stratified sampling designs
- Use of power analysis and effect size considerations in sample size determination
Bootstrapping
- Resampling technique used to estimate sampling distributions empirically
- Particularly useful when theoretical distributions are unknown or assumptions are violated
- Enables inference about population parameters without relying on parametric assumptions
Concept and methodology
- Repeatedly drawing samples with replacement from the original sample
- Calculating the statistic of interest for each resampled dataset
- Distribution of resampled statistics approximates the true sampling distribution
- Number of bootstrap samples typically large (1000 to 10000)
- Implementation using computer simulations and statistical software
Advantages and limitations
- Non-parametric approach, applicable to a wide range of statistics
- Provides estimates of standard errors and confidence intervals
- Useful for complex estimators without known sampling distributions
- Limitations in small samples or when original sample is not representative
- Computational intensity and potential for bias in certain scenarios
Applications in hypothesis testing
- Sampling distributions form the basis for many hypothesis testing procedures
- Understanding sampling distributions crucial for interpreting test results and p-values
- Applications in various fields including medicine, psychology, and economics
Test statistics
- Functions of sample data used to make decisions about hypotheses
- Common test statistics include t-statistic, z-score, and F-statistic
- Sampling distributions of test statistics under null hypothesis known or approximated
- Critical values determined from these sampling distributions
- Relationship between test statistic, effect size, and sample size
P-value calculations
- Probability of obtaining test statistic as extreme as observed, assuming null hypothesis true
- Calculated using the sampling distribution of the test statistic under H0
- Interpretation as strength of evidence against null hypothesis
- Relationship between p-value, significance level, and Type I error rate
- Controversies and limitations of p-value based inference
Sampling distribution in regression
- Describes the behavior of regression coefficients across repeated sampling
- Crucial for making inferences about population parameters in regression analysis
- Assumptions of linearity, independence, homoscedasticity, and normality of errors
Distribution of regression coefficients
- Sampling distribution of slope and intercept coefficients
- Normality of coefficient distributions under classical linear regression assumptions
- Standard errors of coefficients derived from the sampling distribution
- Impact of violations of assumptions on the distribution of coefficients
- Applications in testing significance of predictors and model comparisons
Confidence intervals for coefficients
- Constructed using the sampling distribution of regression coefficients
- Interpretation as plausible range for true population parameter
- Calculation using point estimate ± (critical value × standard error)
- Relationship between confidence level and interval width
- Applications in assessing precision of estimated effects and prediction intervals