🎲Statistical Mechanics Unit 10 Review
10.2 Kullback-Leibler divergence
10.2 Kullback-Leibler divergence
Unit & Topic Study Guides
Foundations of Statistical Mechanics
Thermodynamic Laws and Principles
Ensemble theory
Quantum Statistical Mechanics
Classical Statistical Mechanics
Phase Transitions & Critical Phenomena
Non-equilibrium Statistical Mechanics
Kinetic theory of gases
Interacting Systems in Statistical Mechanics
Information Theory in Statistical Mechanics
Definition of Kullback-Leibler divergence
Kullback-Leibler divergence (KL divergence) measures how one probability distribution differs from a second, reference distribution. In statistical mechanics, this matters because you're constantly approximating complex true distributions with simpler models, and KL divergence tells you exactly how much information you lose in that approximation.
Think of it this way: if is the true distribution of microstates in your system and is your model's approximation, KL divergence quantifies the price you pay for using instead of .
Mathematical formulation
For discrete probability distributions:
For continuous distributions:
Two critical properties follow directly from the definition:
- Non-negativity: always, a consequence of Jensen's inequality applied to the concavity of the logarithm.
- Zero condition: if and only if and are identical distributions (almost everywhere).
The logarithm base determines the units: base 2 gives bits, base gives nats. In statistical mechanics, natural logarithms (nats) are standard.
Interpretation as relative entropy
KL divergence is often called relative entropy, and the name reveals its meaning. It measures the extra information needed to encode samples from using a code optimized for .
Suppose you design an optimal coding scheme assuming distribution . If the data actually follows , you'll need extra bits on average to encode each sample. That average excess cost is exactly .
Another useful way to think about it: KL divergence captures the average "surprise" you experience when observing data drawn from while expecting . The greater the mismatch between the two distributions, the more surprised you are, and the larger the divergence.
Properties of KL divergence
- Asymmetry: in general. This means KL divergence is not a true distance metric. The order of arguments matters, and you need to be deliberate about which distribution is and which is .
- No triangle inequality: Another reason it fails to be a metric.
- Additivity for independent distributions: If are independent and are independent, then . This mirrors how entropy is additive for independent subsystems.
- Invariance under reparametrization: KL divergence doesn't change if you apply an invertible transformation to the random variable.
Applications in statistical mechanics
Free energy calculations
KL divergence connects directly to free energy. If is the true equilibrium (Boltzmann) distribution and is a trial distribution, you can show that:
where is the true free energy and is the variational free energy associated with . Because KL divergence is non-negative, this gives you the Bogoliubov inequality: . Minimizing over a family of trial distributions is the basis of variational free energy methods.
KL divergence also appears in the Jarzynski equality, where it helps quantify the dissipated work in irreversible processes. The average dissipation during a non-equilibrium process relates to the KL divergence between the forward and reverse path distributions.
Model comparison
When you have competing statistical mechanical models for a system, KL divergence quantifies how well each model's predicted distribution matches the observed data. A model with smaller KL divergence from the empirical distribution captures more of the system's statistical structure.
This connects to Bayesian model selection: the evidence ratio between two models relates to their relative KL divergences from the true distribution. The principle at work is a formal version of Occam's razor, where you penalize unnecessary model complexity.
Information theory connections
KL divergence sits at the intersection of statistical mechanics and information theory:
- Thermodynamic entropy and Shannon entropy: For a system at equilibrium, the Gibbs entropy has the same functional form as Shannon entropy (up to the Boltzmann constant). KL divergence from the uniform distribution recovers the difference between maximum entropy and actual entropy.
- Maxwell's demon: The demon's ability to reduce entropy requires acquiring information about molecular states. KL divergence quantifies the information gained, and Landauer's principle states that erasing this information dissipates at least of heat per bit. The demon can't beat the second law.
- Fundamental limits: The minimum thermodynamic cost of any computation or measurement is bounded by information-theoretic quantities expressible through KL divergence.
Relationship to other concepts
KL divergence vs. cross-entropy
Cross-entropy between and is defined as:
The relationship to KL divergence is clean:
Since (the entropy of the true distribution) is a constant with respect to , minimizing cross-entropy and minimizing KL divergence over are equivalent optimization problems. This is why cross-entropy loss works as a training objective in machine learning: it's implicitly minimizing KL divergence from the data distribution.
KL divergence vs. mutual information
Mutual information between two random variables and is itself a KL divergence:
It measures how far the joint distribution is from the product of marginals. If and are independent, the joint equals the product of marginals, so . Any statistical dependence between the variables makes the mutual information positive.
In statistical mechanics, mutual information quantifies correlations between subsystems and appears in analyses of coarse-graining, where you want to know how much information about microscopic details survives in a macroscopic description.
Jensen-Shannon divergence
Because KL divergence is asymmetric, the Jensen-Shannon divergence (JSD) provides a symmetrized alternative:
where is the mixture distribution. JSD is bounded between 0 and (or 0 and 1 when using base-2 logarithms), and its square root is a true metric. This makes it useful when you need a symmetric, bounded measure of distributional difference.
Limitations and considerations
Asymmetry of KL divergence
The asymmetry has real consequences for how you set up problems. (the "forward" KL) penalizes heavily wherever has support but assigns low probability. This tends to produce approximations that are mean-seeking (spreading out to cover all modes of ). The "reverse" KL, , instead penalizes for placing mass where doesn't, producing mode-seeking approximations that lock onto a single peak. Choosing the wrong direction can give misleading results.
Infinite divergence cases
If for any state where , the KL divergence is infinite. Physically, this means your model assigns zero probability to a state that actually occurs, which is infinitely "surprising." In practice, this requires:
- Ensuring the support of covers the support of
- Using smoothing techniques (e.g., adding a small to all probabilities)
- Switching to alternative divergences like JSD that handle this gracefully
Numerical stability issues
Computing KL divergence involves logarithms of potentially very small probabilities, which can cause underflow or overflow. Common remedies include:
- Working in log-space throughout the calculation
- Using the log-sum-exp trick to avoid exponentiating large numbers
- Being especially careful with high-dimensional or sparse distributions where many probabilities are near zero
Calculation methods
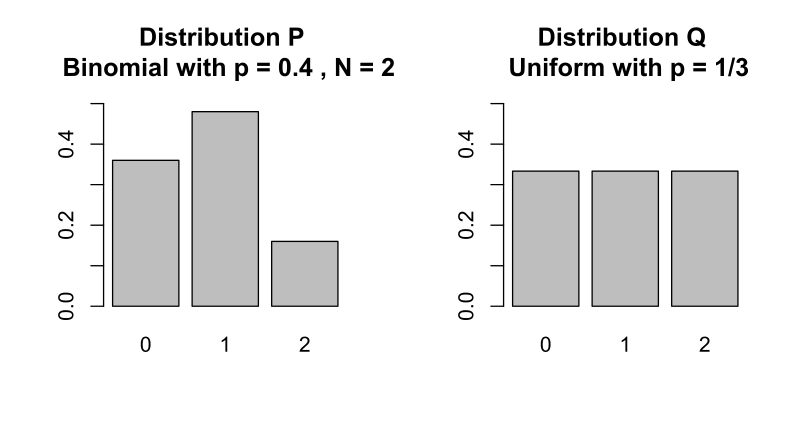
Discrete probability distributions
Direct computation follows the definition:
- For each state , compute
- Handle edge cases: if , that term contributes 0 (by convention, since ). If but , the divergence is infinite.
- Sum over all states.
This is straightforward for small state spaces and can be vectorized efficiently.
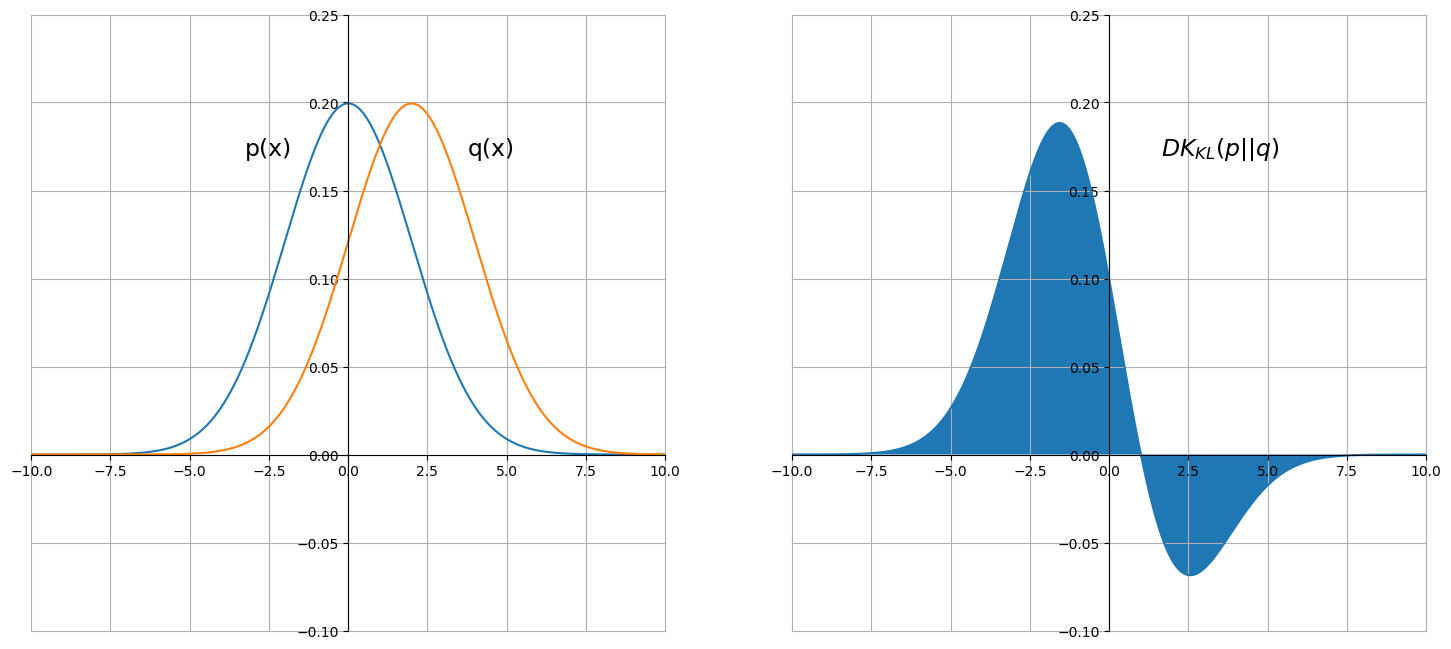
Continuous probability distributions
For continuous distributions, you have several options depending on the situation:
- Analytical solutions exist for certain distribution families. For two Gaussians with means and variances :
- Numerical integration (trapezoidal rule, Simpson's rule) works for low-dimensional distributions where you can evaluate the densities on a grid.
- Monte Carlo estimation is necessary for high-dimensional cases.
Monte Carlo estimation
When you can sample from but can't compute the integral analytically:
This estimator is unbiased and converges as grows, but it requires that you can evaluate both and at the sample points. Importance sampling can reduce variance when and differ substantially.
Extensions and variations
Generalized KL divergence
The standard definition requires and to be normalized probability distributions. The generalized KL divergence (also called the I-divergence) extends this to unnormalized non-negative measures:
The extra terms account for differences in total mass between and . When both are normalized, these terms cancel and you recover the standard KL divergence.
Rényi divergence
The Rényi divergence introduces a parameter that interpolates between different divergence measures:
Taking the limit recovers the standard KL divergence. Different values of emphasize different parts of the distributions: large focuses on regions where is large, while focuses on the support of . Rényi divergence appears in the study of non-extensive statistical mechanics (Tsallis statistics) and quantum information theory.
f-divergences
KL divergence belongs to the broader family of f-divergences, defined for any convex function with :
Choosing gives KL divergence. Other choices yield the Hellinger distance, total variation distance, and chi-squared divergence. The f-divergence framework provides a unified way to study properties shared by all these measures, such as the data processing inequality (divergence can't increase under any transformation applied to both distributions).
Applications beyond statistical mechanics
Machine learning and AI
- Variational inference: Approximate intractable posterior distributions by minimizing over a tractable family . This is the core of variational Bayes and variational autoencoders (VAEs).
- Reinforcement learning: Relative entropy policy search constrains policy updates using KL divergence to prevent catastrophically large changes between iterations.
- Generative models: KL divergence measures how well a generative model's output distribution matches the target data distribution.
Data compression
KL divergence provides theoretical bounds on compression. If you design a code assuming distribution but the true source follows , the expected code length exceeds the optimal length by exactly bits per symbol. This connects to rate-distortion theory, which characterizes the fundamental tradeoff between compression rate and reconstruction quality.
Quantum information theory
The quantum relative entropy generalizes KL divergence to density matrices:
It plays a central role in quantifying entanglement, bounding quantum channel capacities, and establishing fundamental limits on quantum state discrimination. Many results from classical information theory carry over to the quantum setting through this generalization.