Machine learning is revolutionizing robotics. Supervised learning uses labeled data for tasks like object recognition, while unsupervised learning uncovers patterns in unlabeled data, enhancing robot autonomy.
Practical applications include classification and regression techniques for various robotic tasks. Performance evaluation is crucial, with metrics and methods tailored to supervised and unsupervised learning approaches in robotics.
Fundamentals of Machine Learning in Robotics
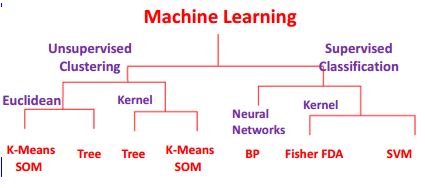
Supervised vs unsupervised learning in robotics
- Supervised Learning
- Leverages labeled data for training models learns from input-output pairs enabling accurate predictions
- Applications enhance robot capabilities (object recognition, pose estimation, motion planning)
- Unsupervised Learning
- Analyzes unlabeled data to uncover hidden patterns and structures without predefined outputs
- Applications improve robot autonomy (clustering sensor data, anomaly detection, feature extraction)
- Key differences
- Labeled vs unlabeled data usage shapes learning approach
- Prediction-focused vs pattern discovery objectives guide algorithm design
- Evaluation methods vary (accuracy metrics vs clustering quality measures)
Practical Applications and Techniques
![Supervised vs unsupervised learning in robotics, Lab 9. Unsupervised Learning. K-Means Clustering [CS Open CourseWare]](https://storage.googleapis.com/static.prod.fiveable.me/search-images%2F%22Supervised_vs_unsupervised_learning_in_robotics_labeled_data_object_recognition_autonomy_pattern_discovery%22-machine_learning_2_.png%3Fw%3D600%26tok%3D013e3a.png)
Applications of supervised learning techniques
- Classification techniques
- Support Vector Machines optimize hyperplane separation using kernel tricks for non-linear classification
- Convolutional Neural Networks extract features through convolution layers excelling in image-based tasks
- Regression techniques
- Linear Regression models relationships between variables for continuous output prediction
- Random Forests combine multiple decision trees enhancing prediction accuracy and handling complex relationships
- Object recognition in robotics
- Extracts features from sensor data trains on labeled object datasets enables real-time classification
- Pose estimation
- Applies regression for continuous pose parameters utilizes deep learning approaches (PoseNet) integrates with robot kinematics
Unsupervised methods for pattern discovery
- Clustering algorithms
- K-means performs centroid-based clustering groups similar sensor readings
- DBSCAN conducts density-based clustering identifies clusters of arbitrary shapes
- Dimensionality reduction techniques
- Principal Component Analysis maximizes variance through linear transformation compresses data
- t-SNE visualizes high-dimensional data using non-linear techniques
- Applications in robotics
- Preprocesses sensor data analyzes robot behavior detects anomalies in performance
- Self-organizing maps
- Implement unsupervised neural networks for data visualization and clustering tasks
Performance evaluation of learning algorithms
- Performance metrics for supervised learning
- Calculates accuracy, precision, recall, F1-score assesses classification performance
- Measures Mean Squared Error for regression problem evaluation
- Utilizes confusion matrix for multi-class classification analysis
- Evaluation techniques for unsupervised learning
- Computes silhouette score to assess clustering quality
- Determines explained variance ratio for dimensionality reduction effectiveness
- Cross-validation methods
- Implements K-fold cross-validation to assess model generalization
- Utilizes leave-one-out cross-validation for small datasets
- Robotic-specific evaluation considerations
- Assesses real-time performance capabilities
- Tests generalization to new environments
- Evaluates robustness against sensor noise and environmental variations
- Dataset considerations
- Splits data into training-validation-test sets
- Addresses balanced vs imbalanced dataset challenges
- Generates synthetic data to augment robotic application training