Natural language processing (NLP) is a crucial field in robotics, enabling machines to understand and generate human language. It combines linguistics, computer science, and AI to process text and speech, forming the foundation for voice interfaces and human-robot communication.
NLP encompasses various techniques, from basic text processing to advanced semantic analysis and generation. Machine learning, especially deep learning, has revolutionized NLP, enabling systems to learn complex language patterns from data and adapt to new domains and languages efficiently.
Fundamentals of NLP
- Encompasses core principles and techniques for processing and understanding human language computationally
- Integrates linguistics, computer science, and artificial intelligence to enable machines to interpret and generate natural language
- Forms the foundation for various applications in robotics, including voice interfaces and human-robot communication
Linguistic components
- Phonology studies sound patterns in language, crucial for speech recognition systems
- Morphology analyzes word structure and formation, aiding in tokenization and lemmatization
- Syntax examines sentence structure and grammatical rules, essential for parsing algorithms
- Semantics focuses on meaning at word and sentence levels, vital for natural language understanding
- Pragmatics considers context and intent, important for dialogue systems and conversational AI
Computational approaches
- Rule-based methods utilize hand-crafted linguistic rules for language processing
- Statistical approaches leverage probabilistic models and large corpora of text data
- Machine learning techniques employ algorithms to learn patterns from data automatically
- Deep learning models use neural networks to capture complex language representations
- Hybrid systems combine multiple approaches to leverage strengths of different methods
Historical development
- 1950s: Early machine translation attempts using rule-based systems
- 1960s: Introduction of formal grammars and parsing algorithms
- 1980s: Rise of statistical methods and corpus-based approaches
- 1990s: Emergence of machine learning techniques in NLP
- 2010s: Breakthrough of deep learning models, revolutionizing NLP performance
Text processing techniques
- Involve fundamental operations for converting raw text into structured representations
- Serve as preprocessing steps for higher-level NLP tasks and applications
- Enable machines to break down and analyze textual data systematically
Tokenization and segmentation
- Tokenization splits text into individual units (words, subwords, or characters)
- Word tokenization separates text into words based on whitespace and punctuation
- Subword tokenization breaks words into meaningful subunits (WordPiece, Byte Pair Encoding)
- Sentence segmentation divides text into sentences, considering punctuation and context
- Challenges include handling contractions, abbreviations, and multi-word expressions
Part-of-speech tagging
- Assigns grammatical categories (nouns, verbs, adjectives) to words in a sentence
- Utilizes context and word order to determine appropriate tags
- Rule-based approaches employ hand-crafted linguistic rules for tagging
- Statistical methods use Hidden Markov Models or Maximum Entropy models
- Neural network-based taggers leverage deep learning for improved accuracy
- Applications include information extraction, syntactic parsing, and machine translation
Named entity recognition
- Identifies and classifies named entities (persons, organizations, locations) in text
- Employs sequence labeling techniques to tag entity boundaries and types
- Rule-based systems use gazetteers and pattern matching for entity detection
- Machine learning approaches utilize features like capitalization, context, and word embeddings
- Deep learning models (BiLSTM-CRF, BERT) achieve state-of-the-art performance in NER tasks
- Crucial for information extraction, question answering, and knowledge graph construction
Syntactic analysis
- Focuses on analyzing the grammatical structure of sentences
- Provides a formal representation of sentence structure for further processing
- Enables machines to understand relationships between words and phrases in text
Parsing algorithms
- Top-down parsing starts with the root node and expands downwards (recursive descent)
- Bottom-up parsing begins with leaf nodes and builds upwards (shift-reduce)
- Chart parsing uses dynamic programming to efficiently explore multiple parse trees
- Probabilistic parsing assigns probabilities to different parse trees
- Incremental parsing processes input left-to-right, updating partial parses as new words arrive
Grammar formalisms
- Context-free grammars (CFGs) define language structure using production rules
- Tree-adjoining grammars (TAGs) extend CFGs with tree-based operations
- Lexicalized grammars incorporate lexical information into grammatical rules
- Combinatory Categorial Grammars (CCGs) use logical rules for syntactic composition
- Dependency grammars focus on relationships between words rather than phrase structure
Dependency vs constituency parsing
- Dependency parsing represents sentences as directed graphs of word relationships
- Captures head-dependent relationships between words
- Suitable for languages with flexible word order
- Useful for semantic role labeling and information extraction
- Constituency parsing organizes sentences into nested phrase structures
- Represents hierarchical structure of phrases and clauses
- Aligns well with traditional linguistic theories
- Beneficial for tasks like sentiment analysis and machine translation
- Transition-based and graph-based algorithms exist for both parsing approaches
- Universal Dependencies project aims to create cross-linguistically consistent treebanks
Semantic analysis
- Focuses on extracting meaning from text beyond syntactic structure
- Enables machines to understand the content and context of language
- Crucial for advanced NLP applications like question answering and text summarization
Word sense disambiguation
- Determines the correct meaning of polysemous words in context
- Utilizes context windows, part-of-speech information, and semantic resources
- Knowledge-based approaches leverage lexical databases (WordNet) and semantic networks
- Supervised methods use labeled corpora to train classifiers for sense prediction
- Unsupervised techniques cluster word occurrences based on context similarity
- Applications include machine translation, information retrieval, and text understanding
Semantic role labeling
- Identifies and labels semantic roles of predicates in sentences
- Determines "who did what to whom, when, where, and how"
- Predicate-argument structure represents relationships between verbs and their arguments
- Utilizes syntactic parsing, named entity recognition, and word sense information
- Machine learning approaches use features like syntactic path, voice, and lexical information
- Deep learning models (BERT, XLNet) achieve state-of-the-art performance in SRL tasks
- Important for information extraction, question answering, and text summarization
Coreference resolution
- Identifies and links mentions that refer to the same entity in text
- Resolves pronouns, noun phrases, and other referring expressions to their antecedents
- Rule-based systems use syntactic and semantic constraints for mention clustering
- Machine learning approaches employ features like gender agreement, number, and distance
- Neural coreference models use end-to-end architectures to learn mention representations
- Crucial for discourse understanding, text summarization, and information extraction
- Challenges include handling long-distance references and ambiguous pronouns
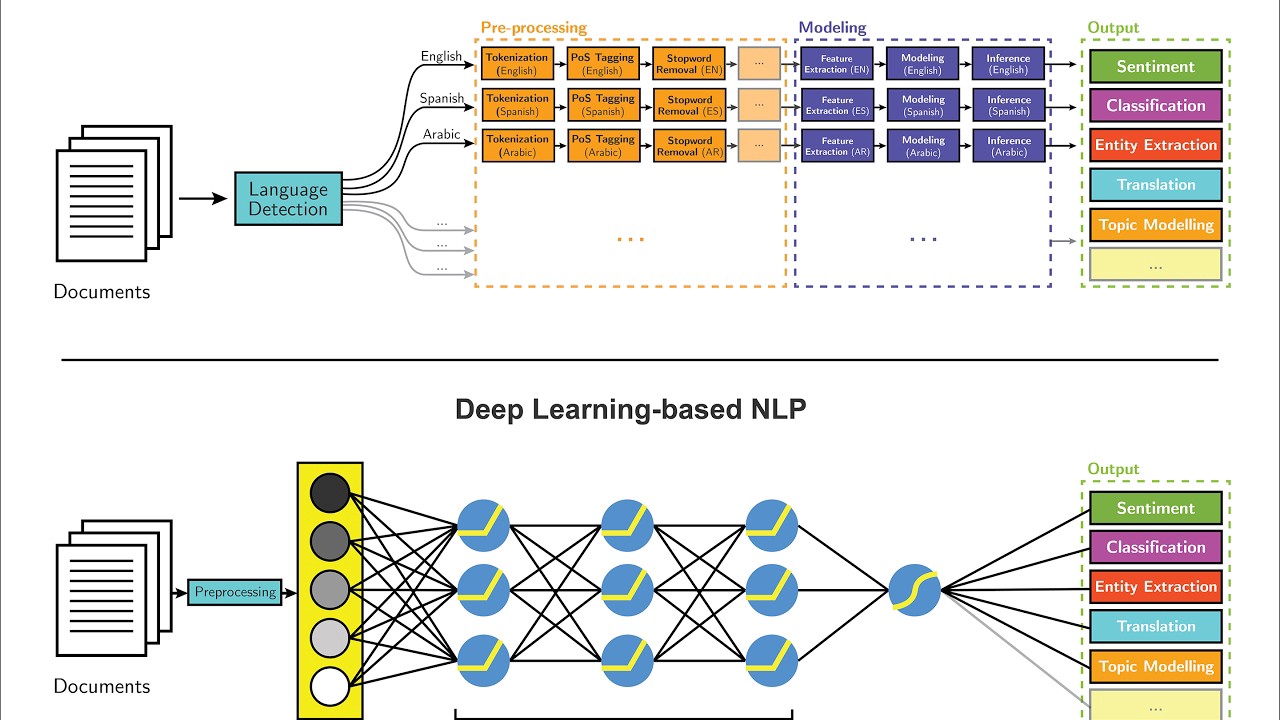
Machine learning in NLP
- Employs algorithms to learn patterns and make predictions from language data
- Enables NLP systems to improve performance through exposure to large datasets
- Facilitates adaptation to new domains and languages without manual rule engineering
Statistical vs neural methods
- Statistical methods use probabilistic models to capture language patterns
- Hidden Markov Models for part-of-speech tagging and named entity recognition
- N-gram language models for text generation and speech recognition
- Maximum Entropy models for text classification and sentiment analysis
- Neural methods leverage artificial neural networks for language processing
- Feed-forward networks for simple classification tasks
- Recurrent Neural Networks (RNNs) for sequence modeling
- Convolutional Neural Networks (CNNs) for text classification and sentiment analysis
- Neural approaches often outperform statistical methods on large datasets
- Statistical methods remain relevant for interpretability and low-resource scenarios
Supervised vs unsupervised learning
- Supervised learning uses labeled data to train models for specific tasks
- Text classification, named entity recognition, and machine translation
- Requires large annotated datasets, which can be expensive and time-consuming to create
- Achieves high performance on well-defined tasks with sufficient training data
- Unsupervised learning discovers patterns in unlabeled data
- Topic modeling, word clustering, and language model pretraining
- Doesn't require manual annotations, making it suitable for large-scale analysis
- Useful for exploratory data analysis and feature learning
- Semi-supervised learning combines labeled and unlabeled data to improve performance
- Self-training and co-training leverage small labeled datasets with large unlabeled corpora
- Active learning selectively labels most informative examples to reduce annotation costs
Transfer learning applications
- Utilizes knowledge gained from one task or domain to improve performance on another
- Pretrained language models (BERT, GPT) capture general language knowledge
- Fine-tuning adapts pretrained models to specific downstream tasks
- Few-shot learning enables quick adaptation to new tasks with limited labeled data
- Cross-lingual transfer learning applies knowledge from resource-rich to low-resource languages
- Domain adaptation techniques transfer knowledge between different text domains
- Crucial for improving NLP performance in low-resource scenarios and specialized domains
Deep learning for NLP
- Employs artificial neural networks with multiple layers for language processing tasks
- Enables end-to-end learning of complex language representations and transformations
- Has revolutionized NLP performance across various tasks and applications
Word embeddings
- Represent words as dense vectors in a continuous vector space
- Capture semantic and syntactic relationships between words
- Word2Vec uses shallow neural networks to learn word representations
- Continuous Bag-of-Words (CBOW) predicts target word from context
- Skip-gram predicts context words given a target word
- GloVe learns embeddings based on global word co-occurrence statistics
- FastText incorporates subword information for improved representation of rare words
- Contextualized embeddings (ELMo, BERT) generate dynamic word representations based on context
- Applications include text classification, named entity recognition, and machine translation
Recurrent neural networks
- Process sequential data by maintaining hidden state across time steps
- Suitable for variable-length input and output sequences in NLP tasks
- Long Short-Term Memory (LSTM) networks address vanishing gradient problem
- Use gating mechanisms to control information flow in hidden state
- Effective for long-range dependencies in language
- Gated Recurrent Units (GRUs) simplify LSTM architecture with fewer parameters
- Bidirectional RNNs process sequences in both forward and backward directions
- Applications include language modeling, machine translation, and sentiment analysis
- Challenges include difficulty in parallelization and capturing very long-range dependencies
Transformer architecture
- Introduces self-attention mechanism for modeling dependencies in sequences
- Enables parallel processing of input sequences, improving training efficiency
- Multi-head attention allows model to focus on different aspects of input simultaneously
- Positional encoding incorporates sequence order information without recurrence
- Encoder-decoder structure suitable for various NLP tasks
- BERT uses bidirectional encoder for language understanding tasks
- GPT employs unidirectional decoder for text generation tasks
- Achieves state-of-the-art performance in machine translation, text summarization, and question answering
- Variants like Transformer-XL and Reformer address limitations in processing long sequences
Natural language understanding
- Focuses on comprehending and interpreting the meaning and intent of human language
- Enables machines to extract relevant information and make inferences from text
- Crucial for developing intelligent systems that can interact naturally with humans
Intent recognition
- Identifies the purpose or goal behind user utterances in conversational systems
- Classifies user input into predefined intent categories (booking, inquiry, complaint)
- Rule-based approaches use keyword matching and pattern recognition
- Machine learning methods employ text classification techniques
- Feature extraction using bag-of-words, TF-IDF, or word embeddings
- Classifiers like Support Vector Machines, Random Forests, or neural networks
- Deep learning models (CNN, LSTM, BERT) achieve high accuracy in intent classification
- Challenges include handling out-of-domain queries and multi-intent utterances
- Applications in chatbots, virtual assistants, and customer service automation
Sentiment analysis
- Determines the emotional tone or opinion expressed in text
- Classifies sentiment as positive, negative, neutral, or on a continuous scale
- Lexicon-based approaches use dictionaries of sentiment-bearing words
- Machine learning methods treat sentiment analysis as a classification problem
- Feature engineering considers n-grams, part-of-speech tags, and syntactic information
- Classifiers like Naive Bayes, Logistic Regression, or SVMs for sentiment prediction
- Deep learning models capture complex sentiment patterns and context
- Convolutional Neural Networks for local feature extraction
- Recurrent Neural Networks for sequential information processing
- Attention mechanisms for focusing on sentiment-relevant parts of text
- Aspect-based sentiment analysis identifies sentiment towards specific entities or attributes
- Applications in social media monitoring, product reviews, and brand reputation management
Text classification
- Assigns predefined categories or labels to text documents
- Encompasses various tasks like topic classification, spam detection, and language identification
- Preprocessing steps include tokenization, lowercasing, and stop word removal
- Feature extraction techniques:
- Bag-of-words representation with term frequency or TF-IDF weighting
- N-gram features to capture short phrases and word combinations
- Word embeddings for dense vector representations of words
- Traditional machine learning classifiers:
- Naive Bayes for probabilistic classification
- Support Vector Machines for finding optimal decision boundaries
- Random Forests for ensemble learning with decision trees
- Deep learning approaches:
- Convolutional Neural Networks for hierarchical feature extraction
- Recurrent Neural Networks for sequential text processing
- Transformer-based models (BERT, XLNet) for contextual understanding
- Evaluation metrics include accuracy, precision, recall, and F1-score
- Applications in content categorization, document routing, and automated tagging
Natural language generation
- Involves creating human-readable text from structured data or other input forms
- Enables machines to communicate information in a natural and coherent manner
- Crucial for developing interactive and expressive AI systems
Text summarization
- Condenses long documents into shorter versions while preserving key information
- Extractive summarization selects important sentences from the original text
- Utilizes features like sentence position, keyword frequency, and centrality
- Graph-based algorithms (TextRank) rank sentences based on importance
- Supervised learning approaches train models to classify sentences as summary-worthy
- Abstractive summarization generates new sentences to capture document essence
- Sequence-to-sequence models with attention for end-to-end summarization
- Pointer-generator networks combine copying and generation mechanisms
- Pretrained language models (BART, T5) fine-tuned for summarization tasks
- Evaluation metrics include ROUGE scores and human judgments of coherence and informativeness
- Applications in news aggregation, document summarization, and meeting minute generation
Machine translation
- Automatically translates text from one language to another
- Rule-based systems use linguistic rules and bilingual dictionaries
- Statistical machine translation (SMT) learns translation patterns from parallel corpora
- Phrase-based SMT aligns and translates multi-word units
- Syntactic SMT incorporates grammatical structure into translation process
- Neural machine translation (NMT) uses end-to-end neural networks for translation
- Encoder-decoder architecture with attention mechanism
- Transformer models achieve state-of-the-art performance in NMT
- Multilingual NMT enables translation between multiple language pairs
- Challenges include handling low-resource language pairs and preserving context
- Evaluation metrics include BLEU score, TER, and human evaluation of fluency and adequacy
- Applications in cross-language communication, localization, and multilingual content creation

Dialogue systems
- Enable natural language interactions between humans and machines
- Task-oriented systems focus on completing specific tasks (booking, information retrieval)
- Employ dialogue state tracking to maintain conversation context
- Use policy learning for optimal action selection in different dialogue states
- Open-domain chatbots engage in general conversations on various topics
- Retrieval-based methods select responses from predefined sets
- Generative models create responses on-the-fly using language models
- End-to-end neural approaches learn dialogue patterns directly from conversation data
- Sequence-to-sequence models with attention for response generation
- Transformer-based models (DialoGPT) for more coherent and contextual responses
- Challenges include maintaining consistency, handling ambiguity, and generating diverse responses
- Evaluation considers response relevance, coherence, and overall conversation quality
- Applications in customer service, virtual assistants, and interactive storytelling
Information retrieval
- Focuses on efficiently finding relevant information from large collections of data
- Enables users to access and extract knowledge from vast amounts of unstructured text
- Crucial for developing search engines, question answering systems, and knowledge bases
Search engines
- Retrieve relevant documents or web pages in response to user queries
- Indexing process creates inverted indices for efficient document lookup
- Tokenization, stop word removal, and stemming preprocess documents
- Term frequency-inverse document frequency (TF-IDF) weighs term importance
- Query processing involves parsing and expanding user queries
- Query expansion adds related terms to improve recall
- Spell correction and query suggestion enhance user experience
- Ranking algorithms determine the order of search results
- Boolean retrieval for exact matching of query terms
- Vector space model computes similarity between query and document vectors
- PageRank algorithm considers link structure for web page importance
- Relevance feedback incorporates user interactions to improve search results
- Evaluation metrics include precision, recall, and mean average precision (MAP)
- Applications in web search, enterprise search, and digital libraries
Question answering systems
- Provide specific answers to natural language questions
- Closed-domain QA focuses on specific domains with structured knowledge bases
- Open-domain QA handles general questions using large text corpora
- Components of a typical QA system:
- Question analysis classifies question type and expected answer format
- Document retrieval finds relevant passages or documents
- Answer extraction identifies and ranks candidate answers
- Machine reading comprehension models learn to extract answers from context
- SQuAD dataset for training and evaluating reading comprehension models
- BERT and its variants achieve human-level performance on many QA tasks
- Knowledge-based QA systems utilize structured knowledge graphs
- Entity linking maps question terms to knowledge base entities
- Semantic parsing converts questions into formal queries (SPARQL)
- Evaluation metrics include exact match, F1 score, and human judgment of answer quality
- Applications in virtual assistants, customer support, and information access systems
Document clustering
- Groups similar documents together based on content similarity
- Unsupervised learning technique for organizing large document collections
- Preprocessing steps include tokenization, stop word removal, and feature extraction
- Clustering algorithms:
- K-means partitions documents into K clusters based on centroid similarity
- Hierarchical clustering builds a tree-like structure of document relationships
- DBSCAN identifies clusters based on density of document representations
- Feature representation techniques:
- Bag-of-words with TF-IDF weighting for term importance
- Topic modeling (LDA) for discovering latent themes in document collections
- Document embeddings (Doc2Vec) for dense vector representations
- Evaluation metrics include silhouette coefficient, Davies-Bouldin index, and human assessment
- Challenges include determining optimal number of clusters and handling high-dimensional data
- Applications in document organization, topic discovery, and recommendation systems
Evaluation metrics
- Quantify the performance of NLP models and systems
- Enable comparison between different approaches and track progress in the field
- Crucial for assessing the quality and effectiveness of NLP applications
BLEU score
- Measures the quality of machine-generated text, primarily used in machine translation
- Computes n-gram overlap between candidate and reference translations
- Incorporates precision for different n-gram lengths (usually up to 4-grams)
- Applies brevity penalty to penalize overly short translations
- BLEU score ranges from 0 to 1, with 1 indicating perfect translation
- Advantages include language-independence and correlation with human judgments
- Limitations include lack of consideration for meaning and fluency
- Variants like smoothed BLEU address issues with short segments
- Used in conjunction with other metrics for comprehensive evaluation of MT systems
ROUGE metric
- Evaluates the quality of automatically generated summaries
- Compares system-generated summaries with human-written reference summaries
- Different variants measure different aspects of summary quality:
- ROUGE-N: N-gram overlap between system and reference summaries
- ROUGE-L: Longest common subsequence between summaries
- ROUGE-S: Skip-bigram co-occurrence statistics
- Computes precision, recall, and F1-score for each ROUGE variant
- Higher ROUGE scores indicate better alignment with reference summaries
- Advantages include simplicity and correlation with human judgments
- Limitations include focus on lexical overlap rather than semantic similarity
- Often used in combination with human evaluation for comprehensive assessment
- Applications in text summarization, headline generation, and content evaluation
F1 score
- Harmonic mean of precision and recall, providing a balanced measure of performance
- Particularly useful for evaluating classification tasks with imbalanced classes
- Precision measures the proportion of correct positive predictions
- Recall measures the proportion of actual positives correctly identified
- F1 score formula:
- Ranges from 0 to 1, with 1 indicating perfect precision and recall
- Macro-averaged F1 calculates F1 for each class and averages the results
- Micro-averaged F1 calculates overall precision and recall across all classes
- Weighted F1 considers class imbalance by weighting F1 scores by class frequency
- Applications in named entity recognition, text classification, and information retrieval
- Often reported alongside precision and recall for comprehensive performance assessment
Ethical considerations
- Address moral and societal implications of NLP technologies
- Ensure responsible development and deployment of language processing systems
- Crucial for building trust and mitigating potential harm in AI applications
Bias in NLP systems
- Occurs when models exhibit unfair or discriminatory behavior towards certain groups
- Sources of bias:
- Training data bias reflects societal prejudices present in text corpora
- Algorithmic bias arises from model design and optimization procedures
- Deployment bias results from misapplication of models in real-world contexts
- Types of bias in NLP:
- Gender bias in word embeddings and language generation
- Racial bias in sentiment analysis and toxicity detection
- Age and socioeconomic bias in speech recognition systems
- Mitigation strategies:
- Diverse and representative data collection and annotation
- Bias-aware model architectures and training objectives
- Regularization techniques to reduce reliance on biased features
- Post-processing methods to adjust model outputs for fairness
- Evaluation frameworks for measuring and quantifying bias in NLP systems
- Ongoing research in fairness-aware NLP and debiasing techniques
- Importance of transparency and accountability in AI development processes
Privacy concerns
- Arise from collection, storage, and processing of personal data in NLP applications
- Risks of unintended disclosure or misuse of sensitive information
- Data anonymization techniques:
- Named entity recognition and replacement for de-identification
- K-anonymity and differential privacy for statistical data release
- Federated learning enables model training without centralizing user data
- Homomorphic encryption allows computation on encrypted data
- Challenges in balancing privacy protection with model performance
- Legal and regulatory frameworks (GDPR, CCPA) governing data privacy
- Ethical considerations in collecting and using personal language data
- Importance of user consent and control over data usage in NLP systems
- Privacy-preserving NLP research for sensitive domains (healthcare, finance)
Multilingual challenges
- Address issues in developing NLP systems for diverse languages and cultures
- Low-resource languages lack sufficient data for traditional ML approaches
- Cross-lingual transfer learning leverages resources from high-resource languages
- Challenges in handling different writing systems and linguistic phenomena
- Universal language models aim to capture multilingual representations
- Machine translation as a tool for cross-lingual NLP tasks
- Cultural sensitivity in developing language technologies for global audiences
- Importance of preserving linguistic diversity in the digital age
- Ethical considerations in language technology access and digital inclusion
- Collaborative efforts for developing multilingual NLP resources and benchmarks
Applications in robotics
- Integrate NLP capabilities into robotic systems for enhanced human-machine interaction
- Enable natural and intuitive communication between humans and robots
- Crucial for developing intelligent and responsive robotic assistants
Human-robot interaction
- Facilitates communication between humans and robots using natural language
- Speech recognition converts spoken language to text for robot processing
- Natural language understanding extracts intent and meaning from user commands
- Dialogue management maintains context and handles multi-turn conversations
- Natural language generation produces appropriate robot responses
- Challenges include handling ambient noise, accents, and informal language
- Multimodal interaction combines language with gestures and facial expressions
- Applications in social robots, assistive technologies, and industrial collaboration
- Ethical considerations in designing human-like interactions and managing user expectations
Voice command systems
- Enable control of robotic systems through spoken instructions
- Wake word detection activates the system upon hearing specific phrases
- Automatic speech recognition (ASR) converts audio to text
- Intent classification determines the purpose of the voice command
- Slot filling extracts relevant parameters from the command
- Text-to-speech (TTS) synthesis generates spoken responses from the robot
- Challenges include handling background noise and speaker variability
- Integration with robot control systems for executing voice-based instructions
- Applications in home automation, autonomous vehicles, and industrial robotics
- Importance of robust error handling and confirmation mechanisms for safety-critical tasks
Natural language interfaces
- Provide text-based interaction with robotic systems using natural language
- Chatbot-like interfaces for querying robot status and issuing commands
- Natural language to code translation for programming robots by description
- Semantic parsing converts natural language into structured robot instructions
- Explainable AI techniques for robots to describe their actions in natural language
- Challenges in handling ambiguity and context in complex instructions
- Integration with robot planning and execution systems
- Applications in educational robotics, remote robot operation, and human-robot collaboration
- Importance of user-friendly design and clear feedback mechanisms
- Ethical considerations in ensuring transparency and user control in robot interactions