Supervised learning is a cornerstone of predictive modeling in data science. It uses labeled data to train algorithms that can make accurate predictions on new, unseen data. This approach is vital for various applications, from financial forecasting to medical diagnosis.
Understanding supervised learning is crucial for developing reliable models. It involves key concepts like feature engineering, model evaluation, and hyperparameter tuning. Mastering these techniques enables data scientists to create robust, reproducible models that generalize well to real-world scenarios.
Fundamentals of supervised learning
- Supervised learning forms a crucial component of Reproducible and Collaborative Statistical Data Science by enabling predictive modeling based on labeled data
- This approach facilitates the development of models that can generalize patterns from historical data to make accurate predictions on new, unseen data
- Supervised learning algorithms play a vital role in various data science applications, from financial forecasting to medical diagnosis
Definition and key concepts
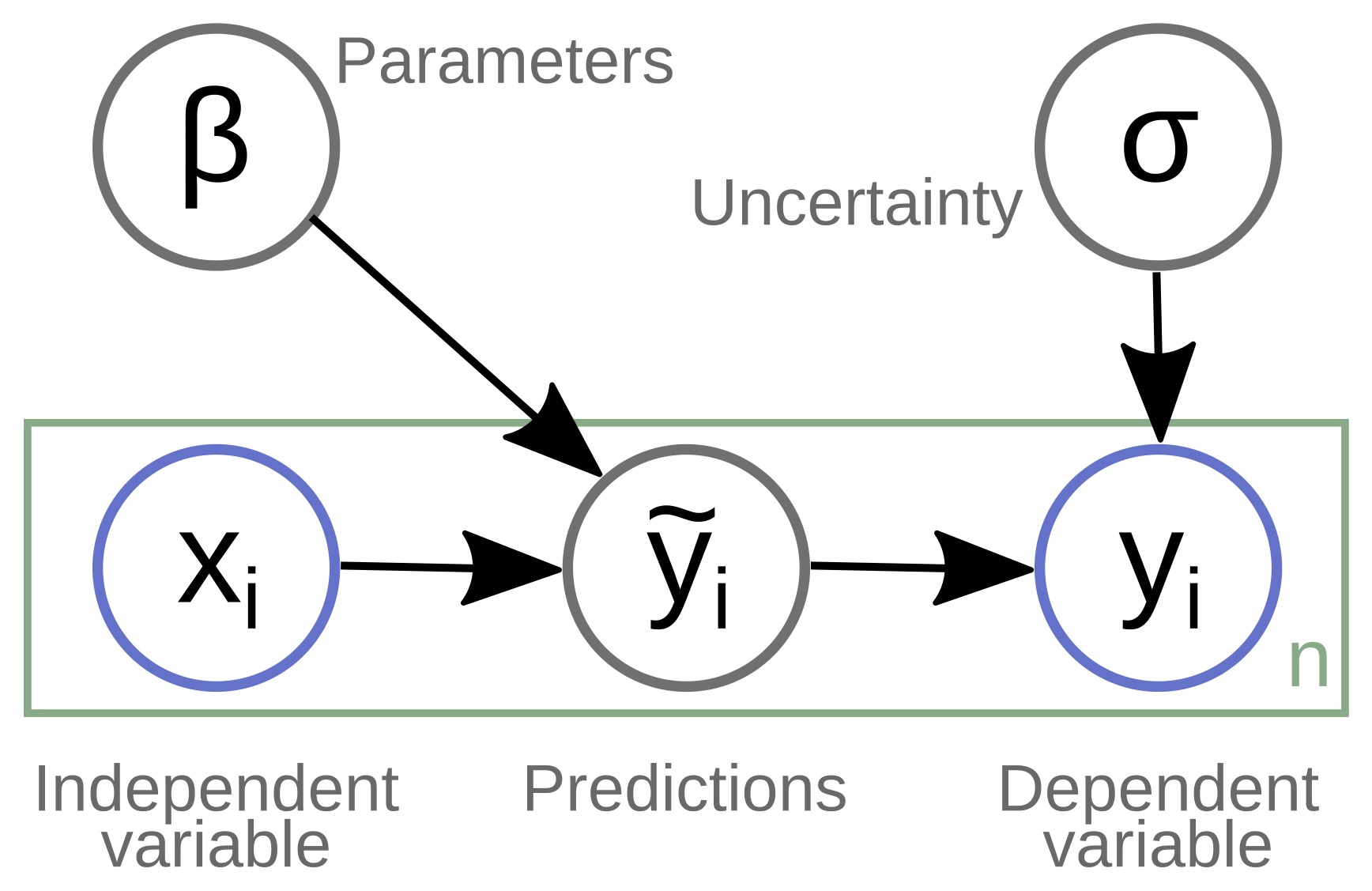
- Learning process where an algorithm is trained on a labeled dataset to predict outcomes or classify new data points
- Involves a target variable (dependent variable) that the model aims to predict based on input features (independent variables)
- Utilizes a training set with known outcomes to learn patterns and relationships between inputs and outputs
- Employs loss functions to measure the difference between predicted and actual values during training
- Iteratively adjusts model parameters to minimize prediction errors and improve performance
Types of supervised learning
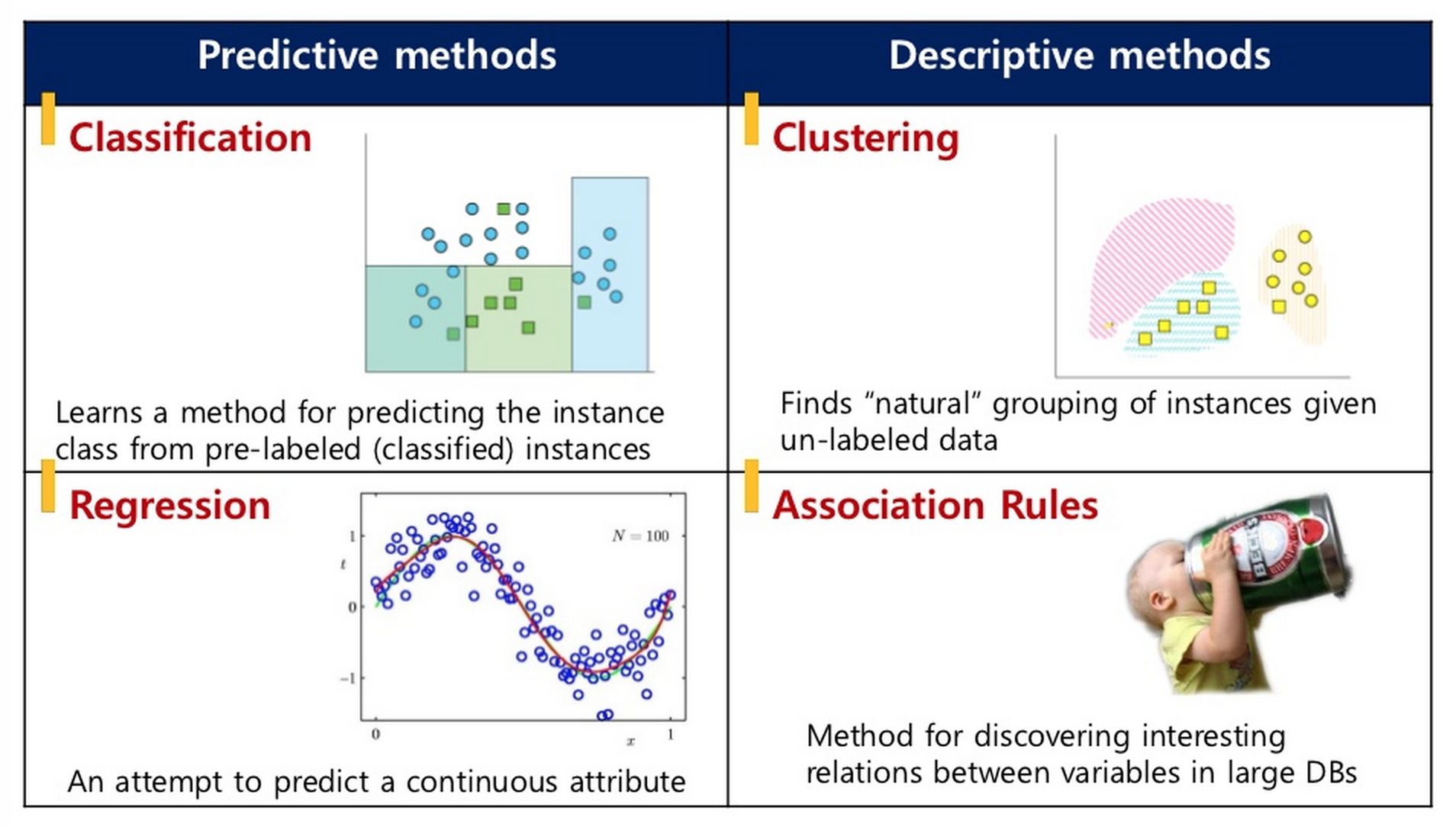
- Classification predicts discrete class labels or categories for input data (spam detection, image recognition)
- Regression estimates continuous numerical values based on input features (house price prediction, sales forecasting)
- Probabilistic modeling assigns probabilities to different outcomes or classes (risk assessment, customer churn prediction)
- Ordinal regression predicts ordered categorical variables (movie ratings, customer satisfaction levels)
Supervised vs unsupervised learning
- Supervised learning requires labeled data with known outcomes for training, while unsupervised learning works with unlabeled data
- Supervised learning focuses on prediction and classification tasks, whereas unsupervised learning aims to discover hidden patterns or structures in data
- Supervised models evaluate performance using predefined metrics, while unsupervised models often rely on intrinsic evaluation measures
- Supervised learning typically has a clear objective function, unlike unsupervised learning which may have more exploratory goals
- Supervised methods include decision trees and support vector machines, while unsupervised techniques encompass clustering and dimensionality reduction
Training data in supervised learning
- Training data serves as the foundation for building accurate and reliable supervised learning models in Reproducible and Collaborative Statistical Data Science
- High-quality, representative training data ensures that models can learn generalizable patterns and make accurate predictions on new, unseen data
- Proper handling and preprocessing of training data significantly impact model performance and the reproducibility of results across different experiments
Features and labels
- Features represent the input variables or attributes used to make predictions (age, income, education level)
- Labels denote the target variable or outcome that the model aims to predict (customer churn, disease diagnosis)
- Feature engineering involves creating new features or transforming existing ones to improve model performance
- Feature scaling normalizes or standardizes features to ensure they contribute equally to the model's learning process
- One-hot encoding converts categorical variables into binary features for use in numerical algorithms
Data preprocessing techniques
- Data cleaning removes or corrects errors, inconsistencies, and outliers in the dataset
- Normalization scales numerical features to a common range, typically between 0 and 1
- Standardization transforms features to have zero mean and unit variance
- Binning groups continuous variables into discrete categories to capture non-linear relationships
- Log transformation reduces the impact of skewed distributions and helps handle multiplicative relationships
Handling missing values
- Deletion removes instances with missing values, suitable for small amounts of missing data
- Mean/median imputation replaces missing values with the average or median of the feature
- Multiple imputation creates multiple plausible imputed datasets to account for uncertainty
- Predictive imputation uses machine learning models to estimate missing values based on other features
- Indicator variables flag the presence of missing data, allowing the model to learn patterns associated with missingness
Common supervised learning algorithms
- Supervised learning algorithms form the core toolkit for predictive modeling in Reproducible and Collaborative Statistical Data Science
- Understanding the strengths and limitations of different algorithms enables data scientists to choose the most appropriate method for a given problem
- Implementing and comparing multiple algorithms helps in identifying the best-performing model for specific datasets and prediction tasks
Linear regression
- Predicts a continuous target variable as a linear combination of input features
- Minimizes the sum of squared errors between predicted and actual values
- Assumes a linear relationship between features and the target variable
- Provides interpretable coefficients indicating the impact of each feature on the prediction
- Suffers from multicollinearity when features are highly correlated
Logistic regression
- Predicts the probability of an instance belonging to a particular class
- Uses the logistic function to map linear combinations of features to probabilities
- Well-suited for binary classification problems (email spam detection, credit approval)
- Provides interpretable odds ratios for understanding feature importance
- Assumes linearity between features and the log-odds of the target variable
Decision trees
- Hierarchical model that splits data based on feature values to make predictions
- Creates a tree-like structure with nodes representing decision points and leaves containing predictions
- Handles both numerical and categorical features without preprocessing
- Prone to overfitting, especially with deep trees
- Provides intuitive visual representation of decision-making process
Random forests
- Ensemble method that combines multiple decision trees to improve prediction accuracy
- Builds trees using random subsets of features and data points (bagging)
- Reduces overfitting by averaging predictions from multiple trees
- Handles high-dimensional data and captures complex non-linear relationships
- Provides feature importance scores based on their contribution to predictions
Support vector machines
- Finds the optimal hyperplane that maximally separates different classes in feature space
- Uses kernel functions to transform data into higher-dimensional spaces for non-linear classification
- Well-suited for high-dimensional data and complex decision boundaries
- Robust to overfitting in high-dimensional spaces
- Computationally intensive for large datasets
Model evaluation and selection
- Model evaluation and selection play a crucial role in ensuring the reliability and generalizability of supervised learning models in Reproducible and Collaborative Statistical Data Science
- Proper evaluation techniques help assess model performance on unseen data and compare different algorithms objectively
- Selecting the best-performing model based on rigorous evaluation metrics enhances the reproducibility and validity of research findings
Train-test split
- Divides the dataset into separate training and testing sets
- Training set used to fit the model, while test set evaluates performance on unseen data
- Typically uses a 70-30 or 80-20 split ratio between training and testing data
- Helps assess model generalization and detect overfitting
- Stratified sampling ensures representative class distribution in both sets for classification problems
Cross-validation techniques
- K-fold cross-validation divides data into k subsets, using k-1 for training and 1 for validation
- Leave-one-out cross-validation uses a single observation for validation and the rest for training
- Stratified k-fold maintains class distribution across folds for imbalanced datasets
- Time series cross-validation respects temporal order for time-dependent data
- Nested cross-validation performs hyperparameter tuning within each fold to avoid data leakage
Performance metrics
- Classification metrics include accuracy, precision, recall, F1-score, and ROC AUC
- Regression metrics encompass mean squared error (MSE), root mean squared error (RMSE), and R-squared
- Confusion matrix visualizes true positives, true negatives, false positives, and false negatives
- Log loss measures the performance of probabilistic classification models
- Domain-specific metrics tailored to particular applications (medical diagnosis accuracy, financial portfolio returns)
Overfitting and underfitting
- Overfitting and underfitting represent common challenges in developing supervised learning models for Reproducible and Collaborative Statistical Data Science
- Addressing these issues is crucial for creating models that generalize well to new, unseen data and produce reliable predictions
- Balancing model complexity with data availability helps achieve optimal performance and enhances the reproducibility of research findings
Bias-variance tradeoff
- Bias represents the error introduced by approximating a real-world problem with a simplified model
- Variance measures the model's sensitivity to fluctuations in the training data
- High bias leads to underfitting, where the model fails to capture important patterns in the data
- High variance results in overfitting, where the model learns noise in the training data
- Optimal model complexity balances bias and variance to achieve the best generalization performance
Regularization techniques
- L1 regularization (Lasso) adds the sum of absolute values of coefficients to the loss function
- L2 regularization (Ridge) adds the sum of squared coefficients to the loss function
- Elastic Net combines L1 and L2 regularization to balance feature selection and coefficient shrinkage
- Dropout randomly deactivates neurons during training in neural networks to prevent co-adaptation
- Early stopping halts training when validation performance starts to degrade, preventing overfitting
Feature selection methods
- Filter methods rank features based on statistical measures (correlation, chi-squared test)
- Wrapper methods use a predictive model to evaluate feature subsets (recursive feature elimination)
- Embedded methods perform feature selection as part of the model training process (Lasso regression)
- Principal Component Analysis (PCA) reduces dimensionality by creating uncorrelated linear combinations of features
- Domain expertise guides the selection of relevant features based on subject matter knowledge
Hyperparameter tuning
- Hyperparameter tuning plays a vital role in optimizing supervised learning models for Reproducible and Collaborative Statistical Data Science
- Proper tuning ensures that models achieve their best possible performance on a given dataset
- Systematic approaches to hyperparameter optimization enhance the reproducibility of model development and improve the reliability of research findings
Grid search
- Exhaustive search over a predefined set of hyperparameter values
- Evaluates all possible combinations of hyperparameters to find the best-performing configuration
- Guarantees finding the optimal combination within the specified search space
- Computationally expensive for large hyperparameter spaces or complex models
- Parallel processing can be used to speed up the search process
Random search
- Randomly samples hyperparameter values from specified distributions
- Often more efficient than grid search, especially for high-dimensional hyperparameter spaces
- Allows for a broader exploration of the hyperparameter space with fewer iterations
- May miss optimal configurations due to its stochastic nature
- Useful when the impact of different hyperparameters on model performance is unknown
Bayesian optimization
- Sequential approach that uses probabilistic models to guide the search for optimal hyperparameters
- Builds a surrogate model of the objective function to predict promising regions of the hyperparameter space
- Balances exploration of unknown regions with exploitation of known good configurations
- Particularly effective for expensive-to-evaluate objective functions (long training times)
- Adapts the search strategy based on previous evaluations to focus on promising areas
Ensemble methods
- Ensemble methods combine multiple models to create more powerful and robust predictive systems in Reproducible and Collaborative Statistical Data Science
- These techniques often lead to improved performance and generalization compared to individual models
- Ensemble approaches enhance the stability and reliability of predictions, contributing to more reproducible research outcomes
Bagging
- Bootstrap Aggregating creates multiple subsets of the training data through random sampling with replacement
- Trains independent models on each subset and combines their predictions through voting or averaging
- Reduces variance and helps prevent overfitting, especially effective for high-variance models (decision trees)
- Random Forests represent a popular implementation of bagging with decision trees
- Parallel processing can be used to train multiple models simultaneously, improving computational efficiency
Boosting
- Sequential ensemble method that builds new models to correct errors made by previous models
- Assigns higher weights to misclassified instances in subsequent iterations
- Gradient Boosting builds new models to predict the residuals of previous models
- AdaBoost adjusts instance weights based on classification errors
- XGBoost and LightGBM are popular gradient boosting implementations with optimized performance
Stacking
- Combines predictions from multiple diverse base models using a meta-model
- Base models are trained on the original dataset and make predictions on a hold-out set
- Meta-model learns to combine base model predictions to make final predictions
- Can leverage strengths of different algorithms to improve overall performance
- Requires careful cross-validation to prevent overfitting and ensure generalization
Supervised learning in practice
- Applying supervised learning techniques to real-world problems in Reproducible and Collaborative Statistical Data Science requires addressing practical challenges
- Scalability, data imbalance, and model interpretability are key considerations for developing effective and reliable predictive models
- Addressing these practical aspects enhances the applicability and reproducibility of supervised learning research in various domains
Scaling to large datasets
- Distributed computing frameworks (Apache Spark, Dask) enable processing of large-scale datasets across multiple machines
- Online learning algorithms update models incrementally with new data, suitable for streaming scenarios
- Feature hashing reduces memory requirements by mapping high-dimensional feature spaces to lower dimensions
- Subsampling techniques (reservoir sampling) allow working with representative subsets of large datasets
- GPU acceleration leverages parallel processing capabilities for faster model training and inference
Handling imbalanced data
- Oversampling minority class instances (SMOTE) creates synthetic examples to balance class distribution
- Undersampling majority class reduces the number of instances to match minority class size
- Class weighting assigns higher importance to minority class instances during model training
- Ensemble methods (EasyEnsemble, BalancedRandomForestClassifier) combine sampling techniques with ensemble learning
- Anomaly detection approaches treat minority class as anomalies for highly imbalanced datasets
Interpretability and explainability
- Feature importance measures quantify the contribution of each feature to model predictions
- Partial dependence plots visualize the relationship between features and model predictions
- SHAP (SHapley Additive exPlanations) values provide consistent feature attribution across different model types
- Local Interpretable Model-agnostic Explanations (LIME) explain individual predictions by approximating the model locally
- Rule extraction techniques derive interpretable rules from complex models (decision trees from neural networks)
Advanced topics in supervised learning
- Advanced supervised learning techniques extend the capabilities of traditional methods in Reproducible and Collaborative Statistical Data Science
- These approaches address specific challenges and enable more efficient learning in various scenarios
- Incorporating advanced techniques can lead to improved model performance and adaptability in diverse research contexts
Transfer learning
- Leverages knowledge gained from one task to improve performance on a related task
- Pre-trained models serve as starting points for fine-tuning on specific datasets
- Reduces the amount of labeled data required for training in the target domain
- Particularly effective in computer vision and natural language processing tasks
- Domain adaptation techniques align feature distributions between source and target domains
Online learning
- Updates model parameters incrementally as new data becomes available
- Suitable for streaming data scenarios and environments with limited memory
- Stochastic Gradient Descent (SGD) serves as a foundation for many online learning algorithms
- Handles concept drift by adapting to changes in data distribution over time
- Requires careful management of learning rates to balance stability and adaptability
Active learning
- Selectively queries the most informative instances for labeling to minimize annotation costs
- Uncertainty sampling chooses instances where the model is least confident in its predictions
- Query-by-committee uses disagreement among an ensemble of models to select instances for labeling
- Expected model change selects instances that would cause the largest update to model parameters
- Particularly useful in domains where labeling data is expensive or time-consuming (medical imaging, sentiment analysis)
Ethical considerations
- Ethical considerations play a crucial role in the development and deployment of supervised learning models in Reproducible and Collaborative Statistical Data Science
- Addressing fairness, bias, and transparency issues is essential for creating responsible and trustworthy AI systems
- Incorporating ethical principles into the model development process enhances the societal impact and acceptability of machine learning applications
Fairness in machine learning
- Demographic parity ensures equal prediction rates across different protected groups
- Equal opportunity requires equal true positive rates across protected groups
- Disparate impact measures the ratio of favorable outcomes between privileged and unprivileged groups
- Fairness-aware algorithms incorporate fairness constraints during model training
- Post-processing techniques adjust model outputs to achieve fairness criteria
Bias in training data
- Selection bias occurs when the training data is not representative of the target population
- Historical bias reflects past prejudices and societal inequalities present in the data
- Measurement bias arises from inconsistent or inaccurate data collection processes
- Algorithmic bias amplifies existing biases in the data through model learning and predictions
- Debiasing techniques (reweighting, adversarial debiasing) aim to mitigate biases in training data
Model transparency and accountability
- Explainable AI techniques provide insights into model decision-making processes
- Model cards document model characteristics, intended use cases, and performance metrics
- Algorithmic impact assessments evaluate the potential societal consequences of deploying AI systems
- Auditing frameworks systematically examine models for biases and unintended behaviors
- Regulatory compliance ensures adherence to legal and ethical standards in AI development and deployment