Open science is revolutionizing research by promoting transparency, collaboration, and accessibility. It aligns with reproducible and collaborative statistical data science, emphasizing shared methods, data, and findings to enhance the quality and reliability of scientific output.
Key principles include transparency, collaboration, accessibility, open data, and open source software. These practices accelerate progress, improve reproducibility, and foster a more ethical research environment. New metrics are evolving to measure the impact of open science contributions beyond traditional citation counts.
Definition of open science
- Open science revolutionizes traditional research practices by promoting transparency, collaboration, and accessibility throughout the scientific process
- Aligns with the principles of reproducible and collaborative statistical data science by emphasizing the sharing of methods, data, and findings
- Facilitates the verification and extension of research results, enhancing the overall quality and reliability of scientific output
Key principles of open science
- Transparency ensures research methods, data, and results are openly available for scrutiny and replication
- Collaboration encourages researchers to work together across institutions and disciplines, fostering innovation
- Accessibility removes barriers to scientific knowledge, allowing anyone to access and build upon research findings
- Open data promotes the sharing of raw data and datasets, enabling further analysis and discovery
- Open source software encourages the development and use of freely available tools for data analysis and visualization
Historical context of open science
- Roots trace back to the 17th century with the establishment of scientific journals for knowledge dissemination
- Gained momentum in the late 20th century with the advent of digital technologies and the internet
- Open Access movement in the early 2000s challenged traditional publishing models (Budapest Open Access Initiative)
- Recent years have seen increased adoption of preprint servers (arXiv, bioRxiv) for rapid dissemination of research
- Growing emphasis on reproducibility in response to the "replication crisis" in various scientific fields
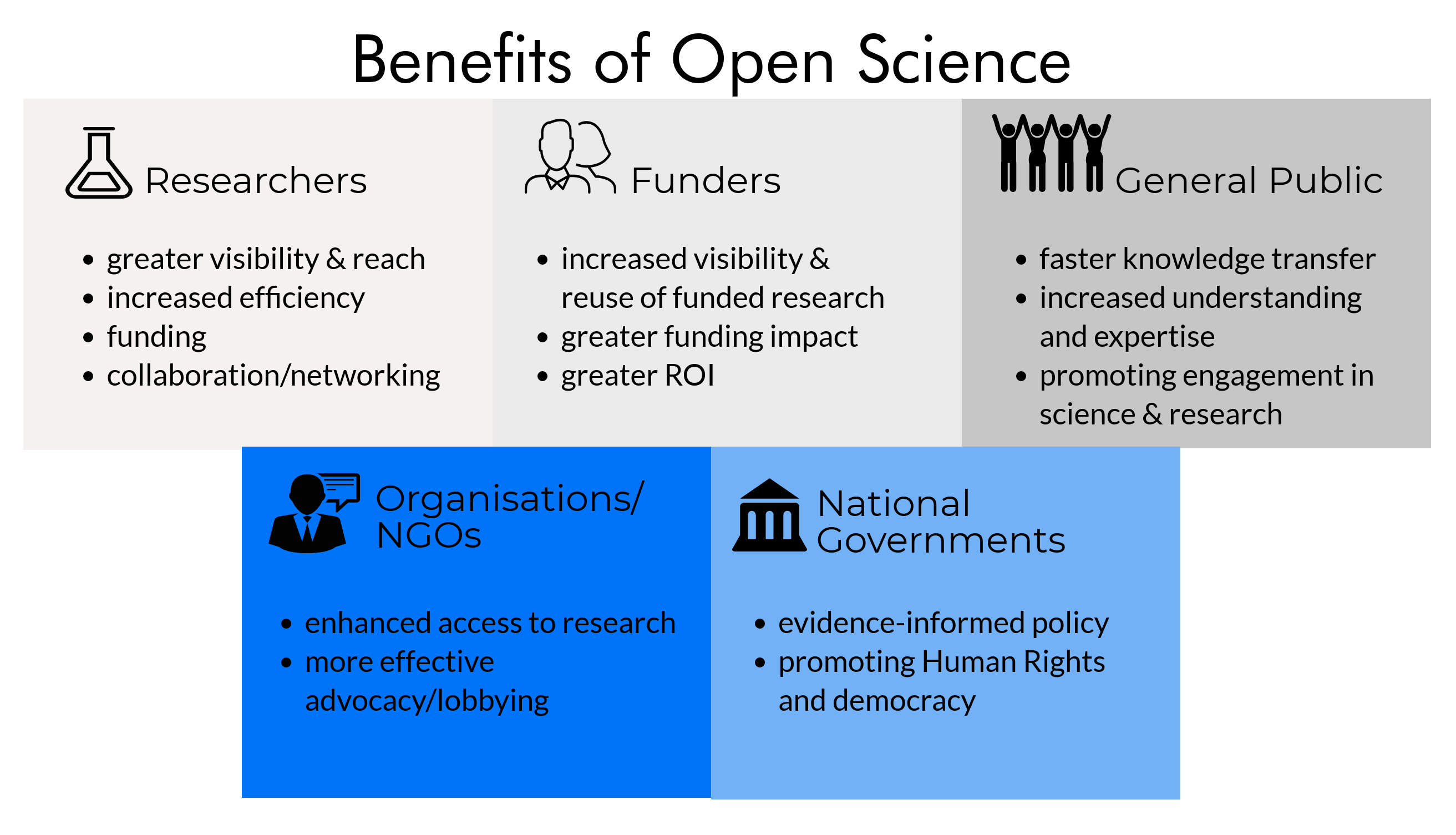
Benefits of open science
- Enhances the reproducibility and reliability of statistical data science research by providing access to raw data and analysis methods
- Fosters a collaborative environment where researchers can build upon each other's work, accelerating scientific progress
- Aligns with the goals of transparent and ethical research practices in data science and statistics
Accelerated scientific progress
- Rapid dissemination of research findings through preprint servers and open access journals
- Increased collaboration opportunities lead to faster problem-solving and innovation
- Reduced duplication of efforts as researchers can build upon existing work more efficiently
- Crowdsourcing of scientific challenges (Foldit protein folding game) harnesses collective intelligence
- Cross-disciplinary insights emerge from open access to diverse research fields
Enhanced research transparency
- Detailed methodologies and protocols are made available for scrutiny and replication
- Raw data accessibility allows for independent verification of results
- Open peer review processes provide transparency in the evaluation of scientific work
- Preregistration of studies helps combat publication bias and p-hacking
- Conflict of interest disclosures become more comprehensive and accessible
Improved reproducibility
- Availability of complete datasets and analysis scripts enables exact replication of studies
- Version control systems (Git) track changes in research materials over time
- Containerization technologies (Docker) ensure consistent computational environments
- Literate programming approaches (Jupyter Notebooks, R Markdown) combine code, data, and narrative
- Open lab notebooks provide detailed records of experimental procedures and observations
Metrics for open science impact
- Traditional impact metrics are evolving to capture the broader influence of open science practices in reproducible and collaborative statistical data science
- New metrics aim to measure not only the reach of published papers but also the impact of shared data, code, and collaborative efforts
- Understanding these metrics is crucial for researchers to effectively demonstrate the value of their open science contributions
Citation-based metrics
- Journal Impact Factor measures the average number of citations received by articles in a journal
- H-index reflects both the productivity and impact of a researcher's publications
- Field-normalized citation impact accounts for differences in citation practices across disciplines
- Citation half-life indicates the long-term relevance of published work
- Open access citation advantage refers to the potential increase in citations for freely accessible articles
Altmetrics vs traditional metrics
- Altmetrics capture online attention and engagement with research outputs
- Social media mentions (Twitter, Facebook) indicate public interest and discussion
- Mendeley readership statistics reflect scholarly interest across disciplines
- Policy document citations measure real-world impact on decision-making
- News media coverage highlights research with broader societal relevance
- Wikipedia citations demonstrate the integration of research into public knowledge resources
Data sharing indicators
- Data citation index tracks the reuse and impact of shared datasets
- Number of dataset downloads indicates the interest and potential reuse of data
- Data availability statements in publications signal commitment to open data practices
- Data repository badges (Zenodo, Figshare) recognize researchers for sharing data
- Linked data metrics measure the interconnectedness of open datasets
Open access publishing
- Plays a crucial role in making statistical data science research freely available to a global audience
- Supports the principles of reproducibility by ensuring that the full text of research articles is accessible for scrutiny
- Challenges traditional publishing models while promoting broader dissemination of scientific knowledge
Types of open access
- Gold open access provides immediate free access to articles upon publication
- Green open access allows self-archiving of pre- or post-prints in institutional repositories
- Diamond/platinum open access offers free publication and access without author fees
- Hybrid journals combine subscription-based and open access articles
- Delayed open access makes articles freely available after an embargo period
Impact on journal metrics
- Open access journals often experience higher citation rates due to increased visibility
- Article Processing Charges (APCs) shift the cost of publishing from readers to authors or institutions
- Journal prestige metrics are evolving to account for open access status and practices
- Emergence of mega-journals (PLOS ONE) challenges traditional journal scope and selectivity
- Preprint citations are increasingly recognized in impact calculations
Collaborative platforms
- Essential tools for facilitating reproducible and collaborative statistical data science research
- Enable seamless cooperation among researchers across geographical and institutional boundaries
- Provide infrastructure for version control, code sharing, and collaborative analysis
Version control systems
- Git tracks changes in code, documents, and other files over time
- GitHub, GitLab, and Bitbucket offer web-based platforms for collaborative code development
- Branching and merging allow parallel development of features or analyses
- Pull requests facilitate code review and discussion before integration
- Commit history provides a detailed record of project evolution and contributions
Open source software tools
- R and Python serve as primary programming languages for statistical analysis and data science
- Jupyter Notebooks enable interactive, shareable computational narratives
- RStudio supports integrated development for R-based projects
- OpenRefine assists in data cleaning and transformation tasks
- Scikit-learn provides machine learning tools for Python users
Data repositories
- Critical infrastructure for storing, sharing, and discovering datasets in reproducible and collaborative statistical data science
- Enable researchers to make their data FAIR (Findable, Accessible, Interoperable, and Reusable)
- Facilitate data citation and tracking of dataset impact
Types of data repositories
- General-purpose repositories (Zenodo, Figshare) accept data from various disciplines
- Domain-specific repositories (GenBank, ICPSR) cater to particular scientific fields
- Institutional repositories host data produced by researchers within a specific organization
- Government data portals (data.gov) provide access to publicly funded research data
- Journal-specific data repositories support data associated with published articles

FAIR data principles
- Findable data has unique persistent identifiers and rich metadata
- Accessible data can be retrieved using standardized protocols
- Interoperable data uses widely applicable formats and vocabularies
- Reusable data has clear usage licenses and detailed provenance information
- Machine-readable metadata facilitates automated discovery and analysis of datasets
Challenges in open science
- Addressing these challenges is crucial for the widespread adoption of open science practices in reproducible and collaborative statistical data science
- Balancing openness with other ethical and practical considerations requires ongoing dialogue and policy development
- Overcoming these obstacles can lead to more robust and trustworthy scientific research
Data privacy concerns
- Sensitive personal information in datasets requires careful anonymization techniques
- Medical research data often involves strict privacy regulations (HIPAA)
- Differential privacy methods allow sharing of aggregate statistics while protecting individual privacy
- Data use agreements define terms for accessing and using sensitive datasets
- Synthetic data generation offers a way to share data characteristics without exposing real individuals
Intellectual property issues
- Patent considerations may limit the immediate sharing of certain research findings
- Copyright protection for software code can conflict with open source principles
- Licensing choices (Creative Commons, GNU GPL) impact the reusability of shared materials
- Material Transfer Agreements govern the sharing of physical research materials
- Trade secrets in industry-sponsored research may restrict full disclosure of methods or data
Cultural barriers in academia
- "Publish or perish" mentality can discourage sharing of preliminary results
- Fear of being scooped may lead researchers to withhold data until publication
- Traditional metrics for career advancement may not fully recognize open science contributions
- Lack of training in open science practices creates hesitation among researchers
- Resistance to change from established senior researchers can slow adoption of open practices
Policy and funding implications
- Policies and funding requirements play a crucial role in shaping the landscape of open science in reproducible and collaborative statistical data science
- Understanding these implications is essential for researchers to align their practices with institutional and funder expectations
- Policy changes are driving a shift towards more open and transparent research practices across disciplines
Institutional open science policies
- Universities implement data management plan requirements for research projects
- Institutional repositories are established to host and share research outputs
- Open access policies mandate or encourage free availability of published research
- Promotion and tenure criteria are updated to recognize open science contributions
- Research integrity offices provide guidance on open and reproducible practices
Funder requirements for openness
- National funding agencies (NIH, NSF) mandate data sharing plans in grant applications
- European Commission's Horizon Europe program requires open access publication
- Private foundations (Gates Foundation, Wellcome Trust) implement open access policies
- Data management costs are increasingly considered allowable expenses in grants
- Funders require ORCID identifiers to track researcher contributions across projects
Future of open science
- The future of open science is closely intertwined with the evolution of reproducible and collaborative statistical data science
- Emerging trends and technologies are shaping new possibilities for open research practices
- Long-term impacts of open science are expected to transform the scientific enterprise and its relationship with society
Emerging trends in open practices
- Blockchain technology for immutable record-keeping of research processes
- Artificial intelligence tools for automated literature reviews and meta-analyses
- Virtual and augmented reality for collaborative data visualization and analysis
- Citizen science platforms engaging the public in large-scale data collection and analysis
- Decentralized autonomous research organizations (DAROs) for community-driven science
Potential long-term impacts
- Democratization of science leads to more diverse participation in research
- Increased public trust in scientific findings due to transparency and reproducibility
- Faster response to global challenges through open collaboration (COVID-19 research)
- Shift towards more holistic evaluation of researchers beyond publication metrics
- Integration of open science principles into early education and research training programs