Kernel Density Estimation is a powerful nonparametric method for estimating probability distributions. It uses data points and kernel functions to create smooth, continuous estimates of underlying distributions, offering advantages over traditional histograms.
KDE's flexibility comes with challenges in choosing optimal bandwidths and kernel functions. Understanding these trade-offs is crucial for accurate density estimation, making KDE a valuable tool in the broader context of nonparametric methods and resampling techniques.
Kernel Density Estimation Basics
Nonparametric Density Estimation and Kernel Functions
- Kernel Density Estimation (KDE) provides a nonparametric approach to estimate probability density functions
- Utilizes observed data points to construct a smooth, continuous estimate of the underlying distribution
- Kernel function acts as a weighting function centered at each data point
- Common kernel functions include Gaussian, Epanechnikov, and triangular kernels
- KDE formula:
- represents the estimated density at point
- denotes the number of data points
- signifies the bandwidth
- symbolizes the chosen kernel function
- Kernel functions must be symmetric and integrate to 1
Bandwidth and Smoothing Parameter
- Bandwidth (h) controls the smoothness of the resulting density estimate
- Larger bandwidth values produce smoother estimates but may obscure important features
- Smaller bandwidth values capture more local variations but can lead to overfitting
- Optimal bandwidth selection balances bias and variance
- Rule-of-thumb bandwidth estimators (Silverman's rule) provide quick approximations
- Silverman's rule for Gaussian kernels:
- represents the standard deviation of the data
- denotes the interquartile range
Bias-Variance Tradeoff in KDE
- Bias refers to the systematic error in the estimate
- Variance measures the variability of the estimate across different samples
- Small bandwidth leads to low bias but high variance (undersmoothing)
- Large bandwidth results in high bias but low variance (oversmoothing)
- Optimal bandwidth minimizes the Mean Integrated Squared Error (MISE)
- MISE combines both bias and variance:
- Cross-validation techniques help find the optimal bandwidth by minimizing error estimates
![Nonparametric Density Estimation and Kernel Functions, Kernel Density Estimation [The Hundred-Page Machine Learning Book]](https://storage.googleapis.com/static.prod.fiveable.me/search-images%2F%22Nonparametric_density_estimation_kernel_functions_Gaussian_Epanechnikov_triangular_KDE_probability_density_visualization%22-fetch.php%3Fw%3D400%26tok%3D66fb1c%26media%3Ddensity_estimation.png)
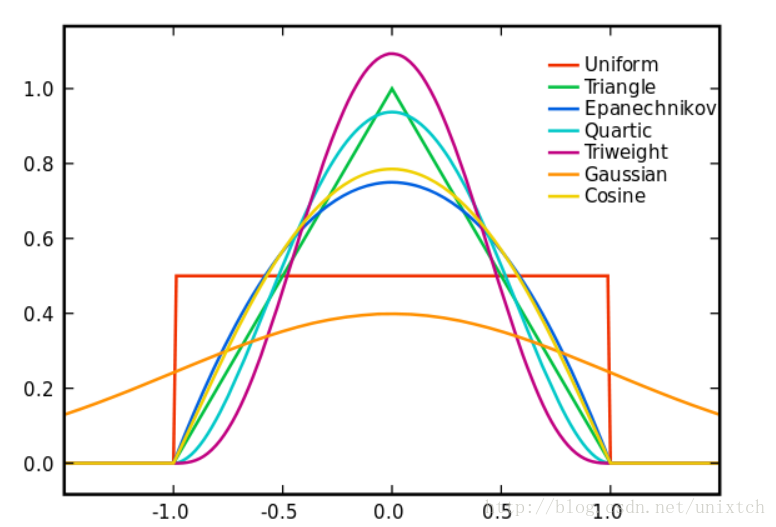
Types of Kernels
Common Kernel Functions
- Epanechnikov kernel maximizes efficiency in terms of mean squared error
- Epanechnikov kernel function:
- Gaussian kernel offers smooth estimates and mathematical convenience
- Gaussian kernel function:
- Triangular kernel provides a simple, computationally efficient option
- Triangular kernel function:
- Uniform kernel assigns equal weight within a fixed range
- Uniform kernel function:
Comparison of KDE with Histogram
- Histograms divide data into discrete bins, while KDE produces a continuous estimate
- KDE overcomes the discontinuity issues present in histograms
- Histogram bin width corresponds to KDE bandwidth
- KDE offers better smoothness and differentiability compared to histograms
- Histograms can be sensitive to bin width and starting point choices
- KDE provides more consistent results across different samples
- Computational complexity: histograms O(n), KDE O(n^2) (naive implementation)
- KDE allows for easier interpretation of multimodal distributions
Advanced KDE Techniques
Multivariate Kernel Density Estimation
- Extends KDE to estimate joint probability densities in multiple dimensions
- Multivariate KDE formula:
- represents the bandwidth matrix
- Bandwidth selection becomes more challenging in higher dimensions
- Curse of dimensionality affects the accuracy of estimates as dimensions increase
- Product kernels use separate bandwidths for each dimension
- Spherical kernels apply the same bandwidth in all dimensions
Boundary Correction and Adaptive KDE
- Boundary bias occurs when estimating densities near the edges of the support
- Reflection method mitigates boundary bias by reflecting data points across boundaries
- Boundary kernel methods adapt the kernel shape near boundaries
- Adaptive KDE adjusts bandwidth based on local data density
- Pilot density estimate guides the selection of local bandwidths
- Adaptive KDE formula:
- denotes the local bandwidth at point
Cross-validation for Bandwidth Selection
- Leave-one-out cross-validation (LOOCV) assesses the quality of bandwidth choices
- LOOCV criterion:
- represents the density estimate at without using
- Likelihood cross-validation maximizes the log-likelihood of the density estimate
- Least squares cross-validation minimizes the integrated squared error
- Grid search or optimization algorithms find the bandwidth minimizing the CV criterion
- K-fold cross-validation offers a computationally efficient alternative to LOOCV
- Plug-in methods estimate optimal bandwidth using asymptotic approximations