Multiple linear regression expands on simple linear regression by incorporating multiple predictors. This powerful statistical tool allows us to model complex relationships between variables, making it essential for data scientists and researchers analyzing real-world phenomena.
Understanding the components, evaluation methods, and challenges of multiple linear regression is crucial. This knowledge enables us to build accurate models, interpret results effectively, and address common issues like multicollinearity and heteroscedasticity in our analyses.
Model Components
Key Elements of Multiple Linear Regression
- Dependent variable represents the outcome or response being predicted
- Independent variables serve as predictors or explanatory factors influencing the dependent variable
- Regression coefficients measure the change in the dependent variable for a one-unit increase in an independent variable, holding other variables constant
- Intercept indicates the expected value of the dependent variable when all independent variables equal zero
- Residuals capture the difference between observed and predicted values, representing unexplained variation in the model
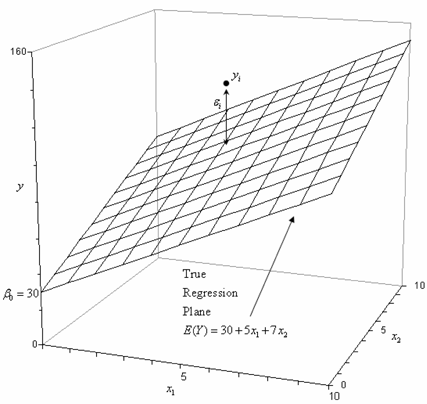
Mathematical Representation and Interpretation
- Multiple linear regression model expressed as:
- Y denotes the dependent variable
- X₁, X₂, ..., Xₖ represent k independent variables
- β₀ symbolizes the intercept term
- β₁, β₂, ..., βₖ correspond to regression coefficients for each independent variable
- ε represents the error term or residuals
- Interpretation of coefficients provides insights into the relative importance of each predictor variable
Model Evaluation
Estimation and Fitting Techniques
- Least squares estimation minimizes the sum of squared residuals to find optimal coefficient values
- Ordinary Least Squares (OLS) method commonly used for parameter estimation in multiple linear regression
- Calculation of least squares estimates involves matrix algebra and solving normal equations
- Goodness-of-fit measures assess how well the model explains the variation in the dependent variable
Performance Metrics and Interpretation
- R-squared quantifies the proportion of variance in the dependent variable explained by the independent variables
- R-squared ranges from 0 to 1, with higher values indicating better model fit
- Adjusted R-squared accounts for the number of predictors in the model, penalizing unnecessary complexity
- Comparison between R-squared and adjusted R-squared helps identify potential overfitting issues
- F-statistic tests the overall significance of the regression model, comparing it to a null model
Model Challenges
Multicollinearity and Its Effects
- Multicollinearity occurs when independent variables exhibit high correlation with each other
- Consequences of multicollinearity include inflated standard errors and unstable coefficient estimates
- Detection methods for multicollinearity involve correlation matrices and variance inflation factors
- Variance Inflation Factor (VIF) quantifies the severity of multicollinearity for each predictor
- VIF values greater than 5 or 10 typically indicate problematic levels of multicollinearity
Heteroscedasticity and Its Implications
- Heteroscedasticity refers to non-constant variance of residuals across different levels of independent variables
- Violates the assumption of homoscedasticity in multiple linear regression
- Consequences of heteroscedasticity include biased standard errors and unreliable hypothesis tests
- Detection methods for heteroscedasticity involve residual plots and statistical tests (Breusch-Pagan test)
- Remedies for heteroscedasticity include weighted least squares regression and robust standard errors
Advanced Model Features
Incorporating Complex Relationships
- Interaction terms capture the combined effect of two or more independent variables on the dependent variable
- Multiplicative interaction modeled as:
- Interpretation of interaction terms requires considering the effect of one variable at different levels of another
- Centering or standardizing variables helps mitigate multicollinearity issues in models with interaction terms
Handling Categorical Predictors
- Dummy variables represent categorical variables with two or more levels in regression models
- Creation of dummy variables involves assigning binary codes (0 or 1) to different categories
- Reference category serves as the baseline for comparison in dummy variable coding
- Interpretation of dummy variable coefficients compares each category to the reference category
- One-hot encoding extends dummy variable approach to categorical variables with multiple levels