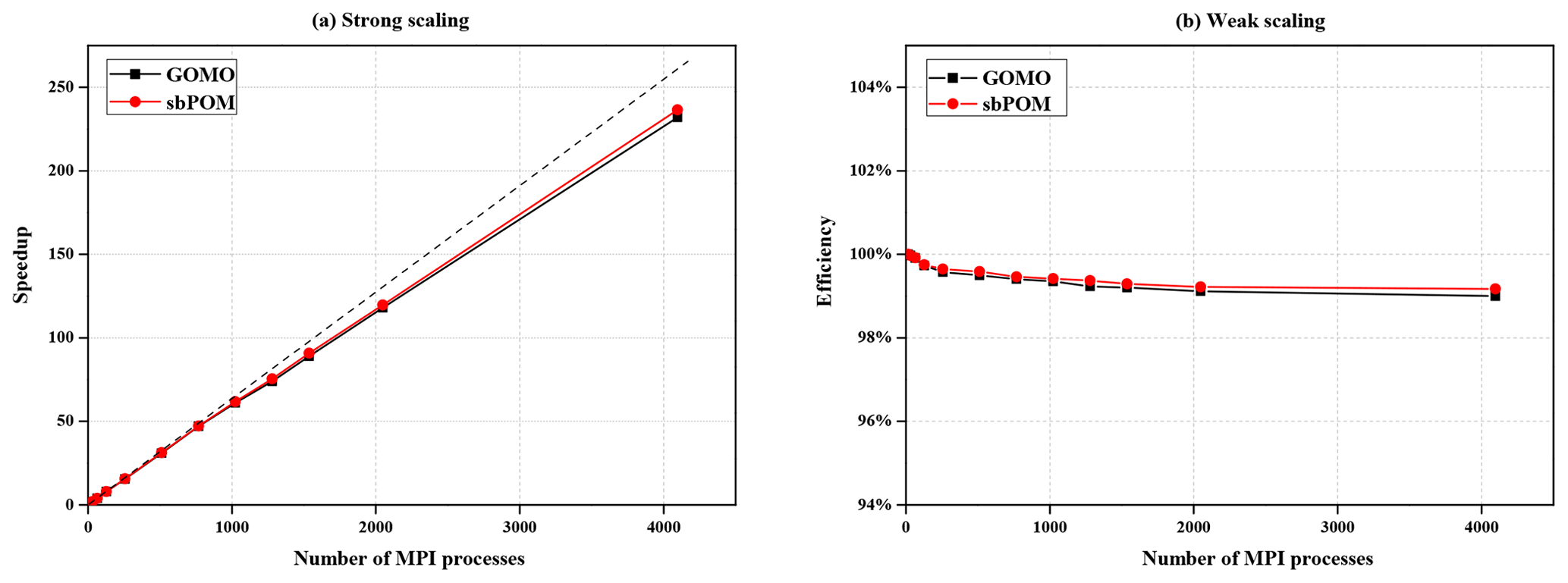
Strong and weak scaling are crucial concepts in parallel computing, measuring how well programs perform as resources increase. Strong scaling focuses on speeding up fixed-size problems, while weak scaling maintains efficiency as both workload and resources grow.
These scaling approaches help optimize parallel algorithms and systems, balancing factors like communication overhead and load balancing. Understanding their nuances is key to designing scalable software and predicting performance in large-scale computing environments.
Strong vs Weak Scaling
Defining Strong and Weak Scaling
- Strong scaling measures speedup achieved when increasing processor count for a fixed problem size
- Aims to reduce execution time
- Calculated as speedup divided by number of processors
- Weak scaling evaluates execution time changes as problem size and processor count increase proportionally
- Maintains constant workload per processor
- Calculated as ratio of execution times between scaled and baseline cases
- Ideal strong scaling results in linear speedup (doubling processors halves execution time)
- Perfect weak scaling maintains constant execution time as both problem size and processor count increase
Theoretical Foundations
- Amdahl's Law underpins strong scaling
- Describes theoretical maximum speedup achievable for a given parallel fraction of the program
- Formula:
- Where S is speedup, n is number of processors, p is parallel fraction
- Gustafson's Law complements Amdahl's Law for weak scaling
- Considers potential for problem size expansion with increased computational resources
- Formula:
- Where S is speedup, n is number of processors, α is serial fraction
Scalability of Parallel Algorithms
Scaling Analysis Techniques
- Strong scaling analysis measures execution times for fixed problem size across varying processor counts
- Typically plotted as speedup versus processor count
- Example: Running a climate model simulation with fixed resolution on 1, 2, 4, 8, 16 processors
- Weak scaling analysis adjusts problem size proportionally to processor count
- Compares execution times to baseline single-processor run
- Example: Increasing the number of particles in a molecular dynamics simulation proportionally to processor count
- Isoefficiency analysis combines strong and weak scaling concepts
- Determines how problem size must increase with processor count to maintain constant efficiency
- Formula:
- Where W is problem size, p is number of processors, K is isoefficiency constant, T_0 is overhead function
Visualization and Metrics
- Log-log plots of execution time versus problem size or processor count reveal scaling limits
- Identify regions of diminishing returns
- Example: Log-log plot showing execution time flattening as processor count increases beyond a certain point
- Strong scaling efficiency quantifies algorithm's utilization of additional processors
- Values closer to 1 (or 100%) indicate better scalability
- Formula:
- Where E_s is strong scaling efficiency, T_1 is execution time on 1 processor, n is number of processors, T_n is execution time on n processors
- Weak scaling efficiency calculated by comparing execution times of scaled runs to baseline
- Consistent times across scales indicate good weak scalability
- Formula:
- Where E_w is weak scaling efficiency, T_1 is execution time on 1 processor, T_n is execution time on n processors with n times larger problem
Factors Affecting Scaling Performance

Problem and Algorithm Characteristics
- Problem size significantly impacts strong scaling
- Larger problems generally exhibit better strong scaling due to improved computation-to-communication ratios
- Example: Matrix multiplication scaling better for 10000x10000 matrices compared to 100x100 matrices
- Algorithmic characteristics determine scaling potential
- Degree of inherent parallelism affects maximum achievable speedup
- Task dependencies limit parallelization opportunities
- Example: Embarrassingly parallel algorithms (Monte Carlo simulations) scale better than algorithms with complex dependencies (Gauss-Seidel iteration)
- Communication-to-computation ratio often determines practical parallelization limits
- High ratios lead to diminishing returns in strong scaling
- Example: N-body simulations becoming communication-bound at high processor counts
System and Implementation Factors
- Load balancing crucial for both strong and weak scaling
- Imbalanced workloads lead to processor idling and reduced efficiency
- Example: Uneven particle distribution in spatial decomposition of molecular dynamics simulations
- Communication overhead (latency, bandwidth limitations) often limits strong scaling at high processor counts
- Example: All-to-all communication patterns in FFT algorithms becoming bottlenecks
- Memory hierarchy and cache effects impact both scaling types
- Changes in data distribution across processors alter cache utilization
- Example: Cache-oblivious algorithms maintaining performance across different problem sizes and processor counts
- System architecture influences scaling behavior
- Interconnect topology affects communication patterns
- Memory organization impacts data access times
- Example: Torus interconnects providing better scaling for nearest-neighbor communication patterns compared to bus-based systems
- I/O operations can become bottlenecks in both scaling scenarios
- Particularly impactful for data-intensive applications
- Example: Parallel file systems (Lustre, GPFS) improving I/O scalability in large-scale simulations
Evaluating Parallel System Efficiency
Performance Curves and Metrics
- Speedup curves plot relative performance improvement against processor count
- Shape indicates degree of scalability
- Example: Linear speedup curve for embarrassingly parallel problems vs. sublinear curve for communication-bound algorithms
- Efficiency curves demonstrate utilization of additional resources
- Declining curves suggest diminishing returns in scalability
- Formula:
- Where E is efficiency, S is speedup, n is number of processors
- Iso-efficiency functions determine problem size increase rate to maintain efficiency
- Help identify scalability limits
- Example: Iso-efficiency function for matrix multiplication:
- Where W is problem size, p is number of processors
- Scalability vectors combine multiple metrics for comprehensive performance view
- Include factors like speedup, efficiency, and problem size scaling
- Example: 3D vector (speedup, efficiency, communication overhead) tracking scaling behavior
Advanced Analysis Techniques
- Crossover points in scaling curves identify transitions between scaling regimes
- Example: Transition from computation-bound to communication-bound behavior in strong scaling of iterative solvers
- Roofline models adapted for scaling analysis
- Incorporate communication costs and parallel efficiency into performance bounds
- Example: Extended roofline model showing how communication bandwidth limits achievable performance at high processor counts
- Scalability prediction models estimate large-scale performance
- Based on analytical or empirical approaches
- Example: LogGP model predicting communication overhead for different system sizes
- Gustafson-Barsis' Law used for weak scaling predictions
- Estimates speedup for scaled problem sizes
- Formula:
- Where S is speedup, p is number of processors, α is serial fraction