Parallel algorithms need to be fast and efficient, but how do we measure that? Performance metrics and scalability analysis help us understand how well our algorithms work as we throw more processors at them.
We'll look at key metrics like speedup and efficiency, and explore how to measure them. We'll also dive into scalability, which tells us if our algorithm can handle bigger problems or more processors without breaking a sweat.
Key performance metrics for parallel algorithms
Fundamental metrics and ratios
- Execution time measures total computation duration including computation and communication time
- Speedup quantifies performance gain compared to sequential counterpart
- Calculated as ratio of sequential execution time to parallel execution time
- Efficiency evaluates effective resource utilization
- Computed as ratio of speedup to number of processors used
- Cost defined as product of parallel runtime and number of processors
- Provides insight into algorithm's resource utilization
- Communication overhead quantifies additional inter-processor communication time
- Can significantly impact parallel performance (network congestion, latency)
Scalability measures
- Scalability assesses algorithm's ability to maintain performance as problem size or processor count increases
- Isoefficiency function relates problem size to processors required for constant efficiency
- Serves as measure of algorithm's scalability
- Helps determine how quickly problem size must grow to maintain efficiency
- Strong scaling examines speedup with fixed problem size and increasing processors
- Weak scaling analyzes performance with fixed problem size per processor
Measuring speedup, efficiency, and scalability
Calculating key metrics
- Speedup calculated by dividing sequential execution time by parallel execution time
- Linear speedup ideal but rarely achievable (hardware limitations, overhead)
- Efficiency computed as speedup divided by number of processors
- Values range from 0 to 1, with 1 representing perfect efficiency
- Efficiency of 0.8 indicates 80% utilization of available processing power
- Scalability analysis involves plotting speedup or efficiency vs number of processors
- Visualizes performance trends and identifies scaling limitations
- Logarithmic scales often used for large processor counts

Theoretical models and laws
- Amdahl's Law provides theoretical upper bound on speedup
- Based on fraction of algorithm that can be parallelized
- Highlights impact of sequential bottlenecks
- Formula: where p is parallelizable fraction, n is number of processors
- Gustafson's Law offers alternative perspective on speedup
- Focuses on tackling larger problems in same time as sequential systems
- Formula: where α is serial fraction of parallel execution time
Interpreting results
- Consider factors affecting observed performance patterns:
- Problem size (may reveal different scaling behavior for small vs large problems)
- Algorithm structure (embarrassingly parallel vs tightly coupled)
- Hardware characteristics (memory bandwidth, network topology)
- Identify scaling regimes:
- Linear scaling (ideal case, speedup proportional to processors)
- Sublinear scaling (common, diminishing returns as processors increase)
- Superlinear scaling (rare, can occur due to cache effects)
Scalability of parallel algorithms
Theoretical analysis techniques
- Derive mathematical models of algorithm performance based on structure and computational complexity
- Apply asymptotic analysis (big O notation) to understand scalability as problem size approaches infinity
- Utilize isoefficiency function to determine problem size growth rate for constant efficiency
- Example: for many divide-and-conquer algorithms, where W is problem size, P is processors, K is constant
- Employ performance modeling frameworks:
- LogP model considers latency, overhead, gap, and processor count
- BSP (Bulk Synchronous Parallel) model analyzes computation, communication, and synchronization phases
Empirical analysis methods
- Conduct experiments on real parallel systems
- Measure performance metrics for various problem sizes and processor counts
- Use benchmarking suites (PARSEC, NAS Parallel Benchmarks) for standardized analysis
- Apply statistical methods to analyze results:
- Regression analysis fits empirical data to theoretical models
- Extrapolate scalability trends beyond measured data points
- Visualize results using scaling plots:
- Speedup vs processors (reveals deviation from ideal linear speedup)
- Efficiency vs processors (shows how well system utilizes additional resources)
- Execution time vs problem size (demonstrates weak scaling behavior)
Combining theoretical and empirical approaches
- Validate theoretical models with empirical data
- Identify discrepancies and refine models accordingly
- Use theoretical insights to guide empirical experiments
- Focus on predicted bottlenecks or interesting scaling regions
- Iteratively improve understanding of algorithm scalability
- Refine models based on experimental observations
- Design new experiments to test theoretical predictions
Factors limiting scalability and optimizations
Workload distribution and communication
- Load imbalance creates idle time and reduces scalability
- Implement dynamic load balancing techniques (work stealing, task queues)
- Example: In parallel matrix multiplication, use block cyclic distribution instead of simple block partitioning
- Communication overhead increases with processor count
- Minimize data transfers (local computations, data replication)
- Use efficient communication patterns (collective operations, topology-aware algorithms)
- Example: Reduce all-to-all communication in parallel FFT by using butterfly communication pattern
Algorithm structure and synchronization
- Synchronization points create bottlenecks
- Apply barrier elimination techniques
- Develop asynchronous algorithms where possible
- Example: Replace global barriers with point-to-point synchronization in parallel iterative solvers
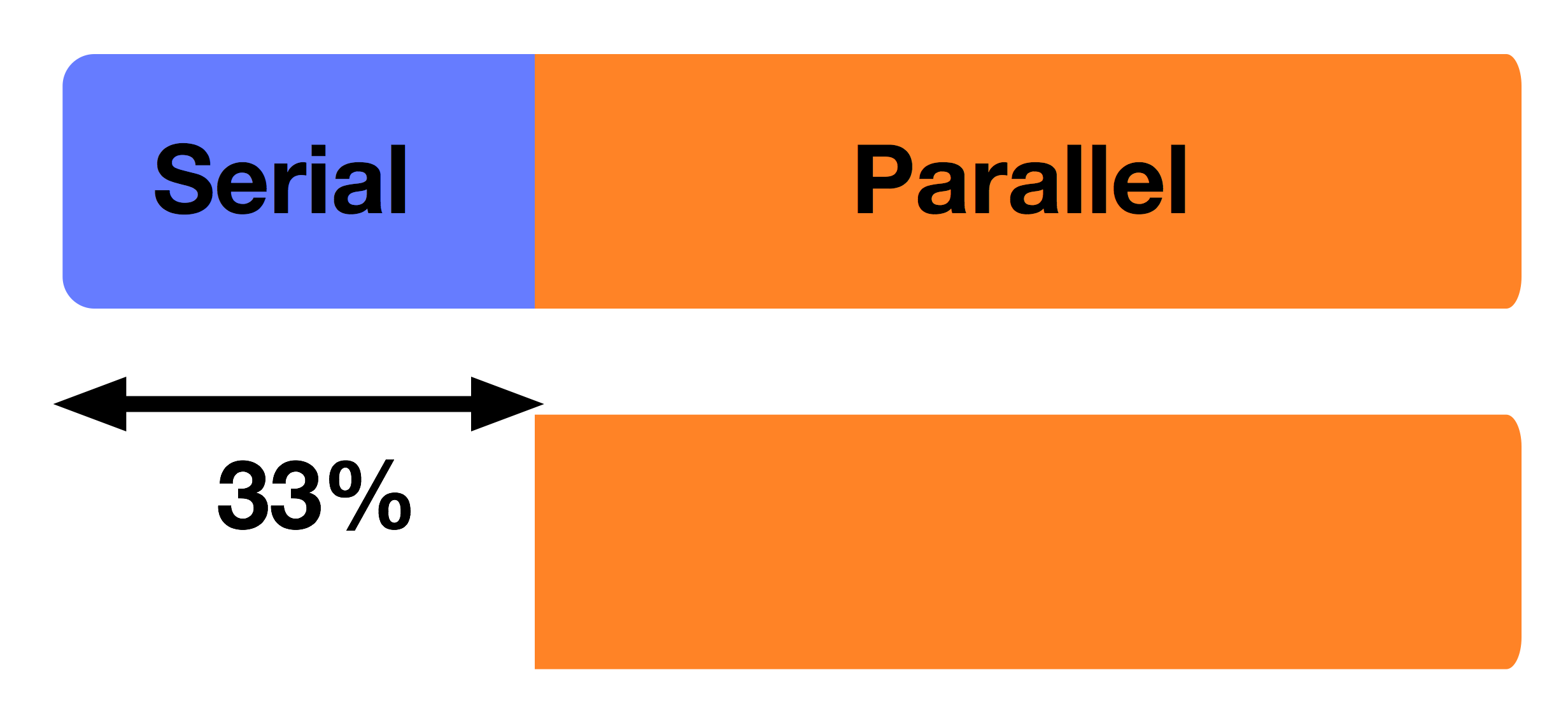
- Sequential portions limit overall scalability (Amdahl's Law)
- Identify and parallelize sequential sections
- Redesign algorithms with inherent parallelism
- Example: Parallelize initialization and result collection phases in parallel simulations
Hardware constraints and optimizations
- Memory bandwidth limitations restrict scalability in shared memory systems
- Implement data locality optimizations (cache blocking, data layout transformations)
- Develop cache-aware and cache-oblivious algorithms
- Example: Use cache-friendly Morton order for matrix traversals in parallel linear algebra routines
- Network topology and interconnect bandwidth can limit scalability
- Consider hardware characteristics in algorithm design (hierarchical algorithms for NUMA systems)
- Optimize for specific network topologies (hypercube algorithms for fat-tree networks)
- Example: Implement topology-aware MPI collective operations for improved performance on large-scale systems