Parallel complexity theory dives into the efficiency of algorithms running on multiple processors. It's all about measuring how fast and how much work these algorithms do, compared to their single-processor counterparts. This stuff is crucial for designing speedy parallel programs.
In this part of the chapter, we're looking at key concepts like parallel time and work complexity, theoretical models, and performance metrics. We'll also explore how problems are classified based on their parallel solvability and learn techniques for proving where a problem fits in the parallel complexity world.
Parallel Time and Work Complexity
Fundamental Concepts
- Parallel time complexity measures execution time of parallel algorithms as function of input size, assuming unlimited processors
- Parallel work complexity represents total computational work performed by all processors in parallel algorithm
- Work-time principle defines relationship between parallel time and work complexity
- Product of time and number of processors used should not exceed work of best sequential algorithm
- Speedup in parallel computing calculated as ratio of sequential to parallel execution time
- Ideal linear speedup rarely achieved due to communication overhead and load balancing issues
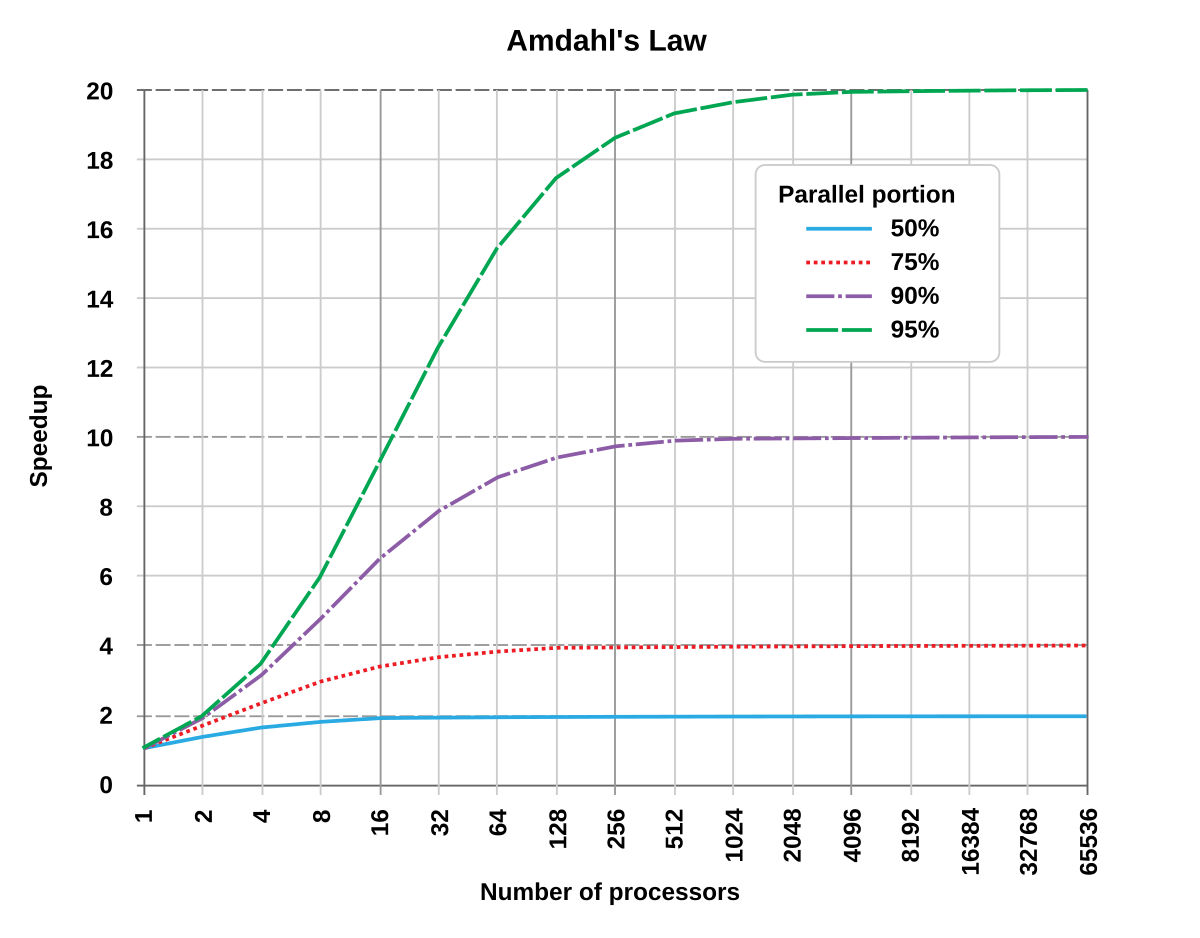
- Amdahl's Law quantifies maximum achievable speedup through parallelization
- Considers fraction of program that can be parallelized
- Scalability in parallel algorithms refers to efficient utilization of increasing processor numbers
- Often measured by isoefficiency functions
Theoretical Frameworks
- Work-depth model analyzes parallel algorithms
- Focuses on depth (critical path length) and total work of computation
- PRAM (Parallel Random-Access Machine) model serves as theoretical foundation
- Used for analyzing parallel algorithms and defining complexity classes
- Circuit models provide alternative framework for parallel complexity analysis
- Circuit depth and size correspond to time and work in PRAM model
Performance Metrics and Analysis
- Efficiency measures how well processors are utilized in parallel computation
- Calculated as speedup divided by number of processors
- Cost optimality achieved when parallel algorithm's work complexity matches best sequential algorithm
- Brent's Theorem relates work and depth to execution time on p processors
- Time ≤ (Work/p) + Depth
- Gustafson's Law provides alternative to Amdahl's Law for scaling problems
- Focuses on fixed time rather than fixed problem size
Problem Classification by Parallel Complexity
Complexity Classes
- NC (Nick's Class) contains problems solvable in polylogarithmic time using polynomial processors on PRAM
- P-complete problems considered inherently sequential
- Unlikely to benefit significantly from parallelization
- Form crucial boundary in parallel complexity theory
- RNC (Randomized Nick's Class) probabilistic counterpart to NC
- Contains problems solvable by randomized parallel algorithms in polylogarithmic time with polynomial processors
- AC hierarchy (AC^0, AC^1, ...) classifies problems based on circuit depth
- Each level corresponds to specific parallel complexity class

Hierarchies and Relationships
- NC^k classes form hierarchy within NC
- NC^k contains problems solvable in O(log^k n) time with polynomial processors
- Key relationships between complexity classes
- NC ⊆ P (open question whether P = NC)
- AC^0 ⊂ AC^1 ⊂ ... ⊂ NC
- PSPACE-complete problems represent upper bound for parallel computation
- Cannot be solved efficiently in parallel unless PSPACE = NC
Examples and Applications
- Matrix multiplication (Strassen's algorithm) in NC^2
- Sorting networks (AKS sorting network) in NC^1
- Maximum flow problem P-complete
- Primality testing in RNC (Miller-Rabin algorithm)
- Boolean formula evaluation in NC^1 (parallel prefix computation)
Proving Problem Membership in Parallel Classes
Proof Techniques
- Circuit depth and size key parameters for proving AC and NC hierarchy membership
- Reduction techniques (NC-reductions) essential for relating problems to known class members
- Uniformity in circuit families crucial for efficient circuit construction in proofs
- Proving NC membership involves designing parallel algorithms with polylogarithmic time complexity
- Analyze work-depth characteristics
- Randomized class (RNC) proofs consider probability of correctness and required random bits
- Simulation arguments establish relationships between complexity classes
- Show higher class problem simulated by lower class
- Adapted classical complexity theory techniques for parallel complexity proofs
- Diagonalization and padding establish class separation or prove lower bounds
Specific Proof Strategies
- Divide-and-conquer paradigm often used to design NC algorithms
- Prove logarithmic depth recursion with polynomial total work
- Parallel prefix computation technique proves many problems in NC^1
- (List ranking, expression evaluation)
- Algebraic techniques used for problems like matrix inversion and determinant computation
- Prove membership in NC^2
- Randomized algorithms often easier to parallelize
- Used to prove membership in RNC (maximal independent set problem)
Case Studies and Examples
- Proving planarity testing in NC using Euler tour technique and tree contraction
- Demonstrating graph connectivity in RNC using random walks
- Establishing P-completeness of Circuit Value Problem through logspace reductions
- Proving membership of perfect matching in RNC using Lovász's algorithm
- Showing Fast Fourier Transform (FFT) in NC^1 using butterfly network
Parallel vs Sequential Complexity
Fundamental Relationships
- P^NC = P establishes parallel algorithms with polylogarithmic time and polynomial processors simulated by polynomial-time sequential algorithms
- Time-processor tradeoffs in parallel algorithms illustrate diminishing returns of increasing processors
- Communication overhead limits effectiveness
- Efficient parallel algorithms achieve polylogarithmic time while keeping total work within polynomial factor of best sequential algorithm
- Key inclusions relate parallel complexity to sequential space and time classes
- NC^1 ⊆ L ⊆ NL ⊆ NC^2 ⊆ P
Theoretical Implications
- P-completeness theory identifies likely inherently sequential problems
- Resistant to significant parallelization
- Parallel decision trees compared to sequential decision trees offer insights into potential speedups
- (Binary search tree vs. parallel binary search)
- Parallel approximation algorithms sometimes provide faster solutions to NP-hard problems
- Trade-off between speed and solution quality (parallel approximation for traveling salesman problem)
Practical Considerations
- Amdahl's Law implications for real-world parallel speedup
- Even small sequential portions significantly limit overall speedup
- Memory hierarchy effects on parallel vs. sequential performance
- Cache coherence and false sharing in parallel systems
- Communication complexity often dominates parallel algorithm performance
- May lead to sublinear speedups in practice
- Load balancing challenges in parallel implementations
- Static vs. dynamic scheduling strategies (parallel quicksort with work stealing)